La possibilità di suddividere grossi programmi in porzioni il più possibile ridotte e autosufficienti (detti
moduli) è una caratteristica
che semplifica le operazioni di produzione e manutenzione del software. I programmi risultano più chiari e quindi più facili da mantenere ed aggiornare
(specie se i programmatori che lavorano a un stesso progetto sono molti).
Un modulo è costituito da dati logicamente correlati e dalle procedure che li utilizzano. L'idea base è quella del "data hiding"
(occultamento dei dati), in ragione della quale un programmatore "utente" del modulo non ha bisogno di
conoscere l'effettiva implementazione delle funzioni offerte da un modulo con
relativi tipi e variabili, ma gli basta sapere come sappia come utilizzarlo.
Un modulo è pertanto paragonabile a un dispositivo (il cui meccanismo interno è a noi sconosciuto), con il quale possiamo comunicare attraverso
particolari funzioni di input/output.
Tali operazioni sono a loro volta raggruppate in un elemento separato, detto
interfaccia che rappresenta l'unico canale di comunicazione fra il modulo effettivo e
i suoi "moduli clienti". La programmazione modulare offre così un duplice vantaggio:
Dal punto di vista sintattico, la definizione di un namespace somiglia molto a quella di una struttura (cambia la parola-chiave e inoltre il punto e virgola in fondo non è obbligatorio). A differenza dalle strutture, il namespace non è un tipo (non può essere istanziato da oggetti) ma identifica semplicemente un ambito di visibilità (scope). Il programmatore è perciò libero di definire gli stessi nomi usati all'interno di un namespace anche al di fuori, senza pericolo di conflitti o ambiguità.
namespace [NomeNameSpace]
{
tipo var1;
. . .
tipo varN;
funzione membro1 { //implementazione della funzione }
. . .
funzione membroM { //implementazione della funzione }
};
Definire un namespace significa dichiarare/definire un gruppo di nomi a sua volta identificato da un nome.
I membri di un namespace sono dichiarazioni o definizioni (con eventuali inizializzazioni) di identificatori di qualunque genere (variabili, funzioni, typedef, strutture, enumeratori, altri tipi astratti qualsiasi ecc...).
void f( );
namespace A
{
void g( );
namespace B
{
void h( );
}
}
la funzione f è dichiarata nel namespace globale; la funzione
g è dichiarata nel namespace A; e infine la funzione h è dichiarata nel
namespace B definito nel namespace A.
Per accedere (dall'esterno) a un membro del namespace B bisogna ripetere due volte l'operazione di risoluzione di visibilità
(::). Esempio:
void A::B::h( ) {......} // definizione esterna della funzione h
Per i namespace "annidati" valgono le normali regole di visibilità e di qualificazione: all'interno della funzione
h non occorre qualificare i membri di B (come sempre), ma neppure quelli di A, in quanto
i nomi definiti in ambiti superiori sono ancora visibili negli ambiti sottostanti; viceversa, all'interno della funzione
g bisogna qualificare i membri di B (perchè i nomi definiti in ambiti inferiori non solo visibili in quelli superiori),
ma non quelli di A.Operatore binario di risoluzione di visibilità
Per accedere a un nome definito in un namespace, bisogna "qualificarlo", associandogli il nome del namespace (quest'ultimo è sempre visibile, avendo global scope), tramite l'operatore binario di risoluzione di visibilità :: (doppi due punti).NomeNameSpace::NomeMembro(...)
#include <stdio.h>
namespace Stack
{
const int max_size = 100;
char v[max_size];
int top = 0;
void push(char c) { if (top < max_size) v[top++] = c; }
char pop() { return ( top==0 ? '\0' : v[--top]); };
}
int main()
{
char ch;
printf("Inserisci una stringa: ");
while ( ch=getchar(), ch != '\n' )
Stack::push(ch);
while ( ch = Stack::pop() )
printf("%c",ch);
// metto in stop il programma prima della sua chiusura
fflush(stdin);
getchar();
return 0;
}
E' auspicabile separare, dove è possibile, le dichiarazioni dalle definizioni (implementazione) ed includere solo le dichiarazioni fra i membri di un namespace, ponendo le seconde al di fuori. Nelle definizioni esterne però, i nomi devono essere qualificati, altrimenti non sarebbero riconoscibili.
namespace [NomeNameSpace]
{
tipo var1;
. . .
tipo varN;
funzione membro1(tipo11,...);
. . .
funzione membroM(tipo1m,...);
};
NomeNameSpace::membro1(tipo11 param11,...); { //implementazione della funzione }
. . .
NomeNameSpace::membroM(tipo1m param1m,...); { //implementazione della funzione }
#include <stdio.h>
namespace Stack
{
const int max_size = 100;
char v[max_size];
int top = 0;
void push(char);
char pop();
}
void Stack::push(char c) { if (top < max_size) v[top++] = c; }
char Stack::pop() { return ( top==0 ? '\0' : v[--top]); }
int main()
{
using namespace Stack;
char ch;
printf("Inserisci una stringa: ");
while ( ch=getchar(), ch != '\n' )
push(ch); // non uso :: per via dell'using
while ( ch = pop() )
printf("%c",ch);
// metto in stop il programma prima della sua chiusura
fflush(stdin);
getchar();
return 0;
}
E' possibile definire un sinonimo "breve" per il nome "vero" "lungo" di un namespace. I sinonimi possono anche essere definiti localmente, a differrenza dei namespace.
Per definire un sinonimo si usa la seguente sintassi:
NameSpace AliasNameSpace=NomeNameSpace;
Da questo punto in poi (nello stesso ambito in cui è definito il sinonimo) si può qualificare un membro del namespace utilizzando come left-operand il sinonimo appena definito.
#include <stdio.h>
namespace Stack
{
const int max_size = 100;
char v[max_size];
int top = 0;
void push(char c) { if (top < max_size) v[top++] = c; }
char pop() { return ( top==0 ? '\0' : v[--top]); };
}
int main()
{
namespace Pila=Stack;
char ch;
printf("Inserisci una stringa: ");
while ( ch=getchar(), ch != '\n' )
Pila::push(ch);
while ( ch = Pila::pop() )
printf("%c",ch);
// metto in stop il programma prima della sua chiusura
fflush(stdin);
getchar();
return 0;
}
Estendibilità della definizione di un namespace
Al contrario delle strutture, i namespace sono costrutti "aperti", nel senso che possono essere definiti più volte con lo stesso nome. Non si tratta però di diverse
definizioni, bensì di estensioni della definizione iniziale. E quindi, pur essendovi blocchi diversi di un namespace con lo stesso nome, l'ambito definito
dal namespace con quel nome resta unico.
I membri complessivamente definiti in un namespace (anche se frammentato in più blocchi) devono essere tutti diversi
(cioè nelle estensioni è consentito aggiungere nuovi membri ma non ridefinire membri definiti precedentemente).
La possibilità di suddividere un namespace in blocchi separati consente, da un lato, di racchiudere grandi frammenti di programma
in un unico namespace e, dall'altro, di presentare diverse interfacce a diverse categorie di utenti, mostrandone parti differenti. Vediamo un esempio:
#include <stdio.h>
namespace Stack
{
const int max_size = 100;
char v[max_size];
int top = 0;
void push(char c) { if (top < max_size) v[top++] = c; }
char pop() { return ( top==0 ? '\0' : v[--top]); };
}
namespace Stack
{
// int top=1 questa istruzioni determina un errore di redifinizione
void reset() { for (int i=0,top=0; i < max_size ; v[i++]='\0'); }
}
int main()
{
char ch;
Stack::reset();
printf("Inserisci una stringa: ");
while ( ch=getchar(), ch != '\n' )
Stack::push(ch);
while ( ch = Stack::pop() )
printf("%c",ch);
// metto in stop il programma prima della sua chiusura
fflush(stdin);
getchar();
return 0;
}
using
Quando un membro di un namespace viene usato ripetutamente fuori dal suo ambito, esiste la possibilità, aggiungendo una sola istruzione, di evitare il fastidio
di qualificarlo ogni volta. La parola chiave using serve a questo scopo e può essere usata in due modi diversi:
#includenamespace Stack { const int max_size = 100; char v[max_size]; int top = 0; void push(char c) { if (top < max_size) v[top++] = c; } char pop() { return ( top==0 ? '\0' : v[--top]); }; } void leggi() { char ch; using Stack::push; // using declaration while ( ch=getchar(), ch != '\n' ) push(ch); } int main() { using namespace Stack; // using directive - block scope char ch; printf("Inserisci una stringa: "); leggi(); while ( ch = pop() ) printf("%c",ch); // metto in stop il programma prima della sua chiusura fflush(stdin); getchar(); return 0; }
In generale è consigliabile memorizzare in un file la dichiarazione della classe, in un altro file la definizione delle funzioni membro e in un altro file ancora il programma principale. Riprendiamo a questo proposito il nostro esempio iniziale del namespace Stack e mettiamoci "nei panni" sia del progettista del modulo che dell'utente che lo utilizza.
| Main.cpp | stack.h | stack.cpp | ||
|---|---|---|---|---|
#include <stdio.h>
#include "stack.h"
using namespace Stack; // using directive - global scope
int main()
{
char ch;
printf("Inserisci una stringa: ");
while ( ch=getchar(), ch != '\n' )
push(ch);
while ( ch = pop() )
printf("%c",ch);
// metto in stop il programma prima della sua chiusura
fflush(stdin);
getchar();
return 0;
}
|
namespace Stack
{
void push(char);
char pop();
}
|
#include "stack.h"
namespace Stack
{
const int max_size = 100;
char v[max_size];
int top = 0;
}
void Stack::push(char c) { if (top < max_size) v[top++] = c; }
char Stack::pop() { return ( top==0 ? '\0' : v[--top]); };
|
| Main.cpp | stack.h | stack.cpp | ||
|---|---|---|---|---|
#include <;stdio.h>
#include "stack.h"
using namespace Stack; // using directive - global scope
int main()
{
char ch;
printf("Inserisci una stringa: ");
while ( ch=getchar(), ch != '\n' )
push(ch);
while ( ch = pop() )
printf("%c",ch);
// metto in stop il programma prima della sua chiusura
fflush(stdin);
getchar();
return 0;
}
|
namespace Stack
{
void push(char);
char pop();
}
|
namespace Stack
{
const int max_size = 100;
char v[max_size];
int top = 0;
void push(char c) { if (top < max_size) v[top++] = c; }
char pop() { return ( top==0 ? '\0' : v[--top]); };
}
|
Link utili
http://www.bo.cnr.it/corsi-di-informatica/corsoCstandard/Lezioni/25Namespace.htmlRiprendiamo il concetto di strutture dati (struct). Le strutture sono insiemi (aggregati) di tipi di dati diversi che presentano alcuni limiti:
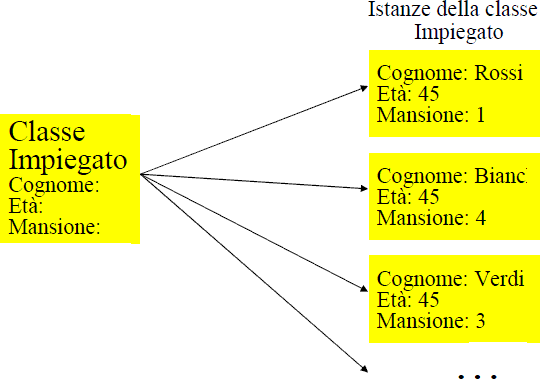
class NomeClasse
{
public: // Membri e metodi pubblici
tipo varPub1;
. . .
tipo varPubN;
funzione membroPub1
. . .
funzione membroPubM
protected:
tipo varPro1;
. . .
tipo varProH;
funzione membroPro1;
. . .
funzione membroProK;
private:// Membri e metodi privati
tipo varPri1;
. . .
tipo varPriS;
funzione membroPri1;
. . .
funzione membroPriT;
};
#include <stdio.h>
class cContatore
{
int val; // private per default
public:
void reset() { val=0; }
void inc() { val++; }
void dec() { val--; }
void visualizza() { printf("%d\n",val); }
};
int main()
{
cContatore x;
x.reset();
x.inc();
x.inc();
x.visualizza();
x.dec();
x.visualizza();
// metto in stop il programma prima della sua chiusura
fflush(stdin);
getchar();
return 0;
}
Le funzioni membro di una classe possono essere
definite:
[inline] TipoRestituito NomeClasse::Funzione(tipo1 parametro1, ...)
{
//implementazione della funzione
}
#include <stdio.h>
class cContatore
{
int val; // è private per default
public:
// Funzioni di interfaccia
void reset();
void inc();
void dec();
void visualizza();
};
void cContatore::reset() { val=0; }
inline void cContatore::inc() { val++; }
inline void cContatore::dec() { val--; }
void cContatore::visualizza() { printf("%d\n",val); }
int main()
{
cContatore x;
x.reset();
x.inc();
x.inc();
x.visualizza();
x.dec();
x.visualizza();
// metto in stop il programma prima della sua chiusura
fflush(stdin);
getchar();
return 0;
}
E’ buona norma di programmazione inserire la definizione di una classe in un file
header (i file intestazione, con estensione
".h"). Tutte le implementazioni dei metodi della classe andranno, invece, inseriti nel file con estensione
.cpp. Quando, nella definizione di una classe, si lasciano solo i prototipi dei metodi, si suole dire che viene creata un'intestazione di classe (solitamente
distribuite in header-files).
| main.cpp | counter.h | counter.cpp | ||
|---|---|---|---|---|
#include <stdio.h> // necessaria per fflush e getchar
#include "counter.h"
int main()
{
cContatore x;
x.reset();
x.inc();
x.inc();
x.visualizza();
x.dec();
x.visualizza();
// metto in stop il programma prima della sua chiusura
fflush(stdin);
getchar();
return 0;
}
|
class cContatore
{
int val; // è private per default
public:
// Funzioni di interfaccia
void reset();
void inc();
void dec();
void visualizza();
};
|
#include <stdio.h>
#include "counter.h"
void cContatore::reset() { val=0; }
void cContatore::inc() { val++; }
void cContatore::dec() { val--; }
void cContatore::visualizza() { printf("%d\n",val); }
|
In C++, quando definisco una classe, utilizzo gli specificatori di accesso ed esattamente:
- private:
- protected:
- public:
Questi specificatori possono essere inseriti più volte all'interno della definizione di una classe. Tutti i membri dichiarati da quel punto in poi
(fino al termine della definizione della classe o fino ad un nuovo specificatore) acquisiscano la connotazione di membri privati,protetti
o publici a seconda.
Private: e protected: hanno un significato analogo: la loro differenza riguarda esclusivamente le classi ereditate
Il "data hiding" (occultamento dei dati) consiste nel rendere certe aree del programma invisibili ad altre aree del programma.
Mentre l'istanza di una classe (variabile di tipo classe) é regolarmente visibile all'interno del proprio ambito di visibilità i suoi membri dichiarati come
private non lo sono: non é possibile, da parte del "modulo cliente" (programma che usa la classe), accedere direttamente ai membri privati di una classe. Esempio:
class Persona
{
int stipendio ; //private è lo specificatore di default
public:
char telefono[20] ;
char indirizzo[30] ;
} ;
Persona Giuseppe; // istanza della classe Persona
ll programma può accedere a Giuseppe.telefono e Giuseppe.indirizzo, ma non a
Giuseppe.stipendio!Specificatori const: funzioni membro a sola lettura
Quando un metodo ha il solo compito di riportare informazioni su un oggetto, senza modificarne il contenuto si può, per evitare errori, imporre tale condizione a priori: basta inserire lo specificatore const dopo la lista degli argomenti della funzione (sia nella dichiarazione che nella definizione). Ad esempio la seguente funzione-membro get non può modificare i membri della sua classe.
class point
{
double x;
double y;
public:
void set(double, double ) ;
};
void point::get(double& x0, double& y0) const
{
x0 = x ;
y0 = y ;
}
Una classe può anche essere definita all'interno di un'altra classe (oppure semplicemente dichiarata, e poi definita esternamente: in questo caso però il suo nome deve
essere qualificato con il nome della classe di appartenenza). La classe
ospitante un'altra classe si dice composta.
Esempio di definizione di un metodo f di una classe B, definita all'interno di un'altra classe A:
void A::B::f( ) {......}
Le classi definite all'interno delle altre classi sono dette: classi-membro o classi annidate.
A parte i problemi inerenti all'ambito di visibilità e alla conseguente necessità di qualificare i loro nomi, queste classi si comportano esattamente come se
fossero indipendenti. Se però sono collocate nella sezione privata della classe di appartenenza, possono essere istanziate solo dai metodi di detta classe.
In sostanza, annidare una classe dentro un'altra classe permette di controllare la creazione dei suoi oggetti. L'accesso ai suoi membri, invece, non dipende
dalla collocazione nella classe di appartenenza, ma solo da come sono dichiarati gli stessi membri al suo interno (cioè se pubblici o privati).
#include <stdio.h>
class segmento
{
private:
class point
{
private:
double x, y;
void get(double *, double *) const;
public:
void set(double, double );
void show();
};
public:
point A,B;
void set(double,double,double,double);
void show();
};
// Implementazioni funzioni-membro classe segmento
void segmento::set(double x1,double y1,double x2,double y2)
{
A.set(x1,y1);
B.set(x2,y2);
}
void segmento::show()
{
printf("A=");
A.show();
printf(" -> B=");
B.show();
}
// Implementazioni funzioni-membro classe annidata point
void segmento::point::get(double *_x, double *_y) const
{
*_x = x ;
*_y = y ;
}
void segmento::point::set(double _x, double _y)
{
x = _x ;
y = _y ;
}
void segmento::point::show()
{
double a,b;
get(&a,&b); // potevo scrivere this->get(&a,&b);
printf("(%.2f,%.2f)",a,b);
}
int main()
{
segmento s;
// questa dichiarazione da un errore in complilazione poichè
// point è private (visibile solo nella classe segmento);
// point p;
s.set(1.01,2.02,3.03,4.04);
// Essendo public i metodi set e show di point possono essere usati
// s.B.set(5.05,6.06);
// s.B.show();
// mentre s.B.get(&a,&b); no!
s.show();
// metto in stop il programma prima della sua chiusura
fflush(stdin);
getchar();
return 0;
}
Come fa il programma a sapere, in esecuzione, su quale oggetto applicare una funzione-membro ?
In realtà il compilatore trasforma la definizione della funzione-membro inserendo il puntatore nascosto this come primo argomento nella funzione.
Ogni volta che incontra la chiamata di una funzione-membro invece inserisce il puntatore all'istanza come primo argomento nella funzione.
Per le funzione-membro a sola lettura, il compilatore trasforma la sua definizione im modo che this diventi un puntatore costante a costante.
Vediamo un esempio:
void myclass::init()
{
.....
x =
.....
}
int myclass::get() const { ..... }
ogg.init( ) ;
viene trasformata in:
void init(myclass* const this)
{
.....
this->x =
.....
}
int get(const myclass* const this) { ..... }
init(&ogg) ;
Come si può notare dall'esempio, il puntatore nascosto this punta all'oggetto utilizzato dalla funzione.
Nel caso che la funzione abbia degli argomenti, il puntatore this viene inserito per primo, e gli altri argomenti vengono spostati in avanti di una posizione.Costruzione e distruzione di un oggetto
Vediamo le varie circostanze in cui un oggetto può essere costruito o distrutto:
point p = p1 + p2;dove p1 e p2 sono istanze già create della stessa classe. In questo caso è costruito l'oggetto temporaneo p1 + p2, che viene distrutto dopo che l'istruzione è stata eseguita.
I costruttori degli oggetti devono sottostare alle seguenti regole:
class NomeClasse
{
....
public:
NomeClasse(); // Costruttore di default
NomeClasse(ListaTipiArgomenti);
....
};
NomeClasse::NomeClasse() { .... } // implementazione costruttore default
NomeClasse::NomeClasse(ListaArgomenti) { .... }
point *pP, *pPa;
pP=new point(3);
pPa=new point[5];
pP->show();
delete [] pPa; // deallocazione per un array
delete pP;
I modi possibili per invocare un costruttore con argomenti sono due: vediamo un esempio:
point::point(double x0=0, double y0=0) { x=x0 ; y=y0 ;} // nell'esempio ho dei valori di default
point p(3.5, 2.1);
point p=point(3.5, 2.1);
La prima forma è più concisa, ma la seconda è più chiara, in quanto ha proprio
l'aspetto di una inizializzazione tramite chiamata esplicita di una funzione.
Anche i tipi nativi hanno i loro costruttori di default, che però, quando servono, vanno esplicitamente chiamati (esempio int i = int();).
I costruttori di default dei tipi nativi inizializzano le variabili con zero (in modo appropriato al tipo). Sono utili quando si ha a che fare con tipi parametrizzati
(come nei template), in cui non è noto a priori se al parametro verrà sostituito un tipo nativo o un tipo astratto.
CONVERSIONE IMPLICITA
Un'attenzione particolare merita il costruttore con un solo argomento. In questo caso, infatti, il costruttore definisce anche una conversione implicita di tipo dal tipo
dell'argomento a quello della classe. Esempio
point::point(double x0) { x=x0;}
point p = point(3);
// Equivale a:
point p=3;
Il numero 3 (che è di tipo int) è convertito implicitamente, prima in
double e poi in "point" (tramite esecuzione del costruttore).
La conversione implicita può essere esclusa premettendo, nella dichiarazione (non nella definizione esterna) del costruttore lo specificatore explicit .
Il casting continua invece ad essere ammesso, in quanto coincide puramente con la chiamata del costruttore.
#include <stdio.h>
// -----------------------------------------------
// Classe senza costruttore
class pointNC
{
public:
double x;
void show();
};
void pointNC::show() { printf("[%.2f]\n",x); }
// -----------------------------------------------
// Classe senza costruttore di default
class pointNDC
{
public:
double x;
explicit pointNDC(double);
void show();
};
pointNDC::pointNDC(double d) { x=d; }
void pointNDC::show() { printf("[%.2f]\n",x); }
// -----------------------------------------------
// Classe con costruttore di default
class point
{
public:
double x;
point();
point(double);
void show();
};
point::point() { x=-10; }
point::point(double d) { x=d; }
void point::show() { printf("[%.2f]\n",x); }
// -----------------------------------------------
int main()
{
// -----------------------------------------------
// Esempio senza costruttore
// -----------------------------------------------
pointNC p;
p.x=1; // devo valorizzarlo altrimenti l'output è imprevedibile
p.show();
// -----------------------------------------------
// Esempio senza costruttore di default
// -----------------------------------------------
pointNDC q(2);
// - potevo scrivere anche in questo modo:
// pointNDC q=pointNDC(2);
// - Non posso dichiarare q nel seguente modo
// poichè manca il costruttore di default
// pointNDC q;
// - Non posso dichiarare q nel seguente modo
// poichè a fianco del costruttore ho explicit
// pointNDC q=2;
// - ma potevo usare il casting:
// pointNDC q=(pointNDC)2;
q.show();
// -----------------------------------------------
// Esempio con costruttore di default
// -----------------------------------------------
point r;
r.x=3;
// - La dichiarazione seguente (equivalente) non genera un errore
// poichè non ho la parola explicit a fianco del costruttore
// point r=3;
// - oppure potevo scrivere:
// point r=point(3);
// point r(3);
r.show();
// metto in stop il programma prima della sua chiusura
fflush(stdin);
getchar();
return 0;
}
I distruttori degli oggetti devono sottostare alle seguenti regole
class NomeClasse
{
....
public:
~NomeClasse(); // Distruttore
....
};
NomeClasse::~NomeClasse() { .... } // implementazione distruttore
class Persona
{
char *nome;
char *cognome;
public:
Persona::Persona(int);
Persona::~Persona();
};
Persona::Persona(int n=20)
{
nome = new char [n];
cognome = new char [n];
}
Persona::~Persona()
{
delete [] nome;
delete [] cognome;
}
I costruttori di copia sono particolari costruttori che vengono eseguiti quando un oggetto é creato per copia.
Ricordiamo brevemente in quali casi ciò si verifica:
- definizione di un oggetto e sua inizializzazione tramite un oggetto esistente dello stesso tipo;
- passaggio by value di un argomento a una funzione;
- restituzione by value del valore di ritorno di una funzione;
- passaggio di un'eccezione al costrutto catch.
Un costruttore di copia deve avere un solo argomento, dello stesso tipo dell'oggetto da costruire; l'argomento (che rappresenta l'oggetto esistente)
deve essere dichiarato const (per sicurezza) e passato by reference (altrimenti si creerebbe una copia della copia!).
Il costruttore di copia della classe verrà chiamato automaticamente ogni volta che si verifica una delle quattro circostanze sopraelencate
(esempio NomeClasse IstanzaNew=IstanzaOld).
questa istruzione aziona il costruttore di copia, a cui é trasmesso IstanzaOld come argomento (byRef).
class NomeClasse
{
....
public:
NomeClasse(const NomeClasse&); // Costruttore di copia
....
};
NomeClasse::NomeClasse(const NomeClasse *A) { .... } // implementazione costruttore di copia
#include <stdio.h>
class point
{
double x,y;
public:
point();
point(double, double);
void show();
};
point::point() { x=0; y=0; }
point::point(double a, double b) { x=a; y=b; }
void point::show() { printf("(%.2f,%.2f)\n",x,y); }
int main()
{
point p(3,4);
point q=p; // Qui il costruttore di copia non serve.
q.show();
// metto in stop il programma prima della sua chiusura
fflush(stdin);
getchar();
return 0;
}
Se la classe possiede dei membri puntatori, l'azione di
default copia i puntatori, ma non le aree puntate: alla fine si ritrovano due oggetti i cui rispettivi membri puntatori puntano alla stessa area.
Ciò potrebbe essere pericoloso, perché, se viene chiamato il distruttore di uno dei due oggetti, il membro puntatore dell'altro, che esiste ancora,
punta a un'area che non esiste più (errore di dangling references). Vediamo un esempio che non usando il costruttore di copia determina un output
non corretto| soluzione errata (senza costruttore di copia) |
soluzione corretta (con costruttore di copia) |
|
|---|---|---|
#include <stdio.h>
class point
{
double *x,*y;
public:
point();
point(double, double);
~point();
void azzera();
void show();
};
point::point() { x=new double; y=new double; *x=0; *y=0; }
point::point(double a, double b) { x=new double; y=new double; *x=a; *y=b; }
point::~point(){ delete x, delete y; }
void point::azzera(){ *x=0 ; *y=0 ; delete x, delete y; }
void point::show() { printf("(%.2f,%.2f)\n",*x,*y); }
int main()
{
point p(3,4);
point q=p;
p.azzera(); // libero l'area di memoria
q.show(); // stampa 0,0 invece di 3,4
// metto in stop il programma prima della sua chiusura
fflush(stdin);
getchar();
return 0;
}
|
#include |
point::point(const point *a)
{
x=new double; y=new double;
*x=*(a->x); *y=*(a->y);
}
...
point q=point(&p);
Quando un costruttore deve, fra l'altro, inizializzare i membri della propria classe, lo può fare tramite una lista di inizializzazione (introdotta dal segno ":" e inserita nella definizione del costruttore dopo la lista degli argomenti). Quindi il costruttore:
point::point(double a, double b) { x=a; y=b; }
può essere scritto in questo modo:
point::point(double a, double b): y(b),x(a) {};
L'ordine nella lista è indifferente; in ogni i caso i membri sono costruiti e inizializzati nell'ordine in cui appaiono nella definizione della classe.
Gli elementi di un array di oggetti (caso 5. dell'elenco iniziale) vengono inizializzati, tramite il costruttore della classe comune di appartenenza, non appena l'array è definito. Con questa istruzione viene utilizzato il costruttore di default:
point pt[5];Consideriamo il caso di un costruttore con un solo argomento (o con più argomenti di cui uno solo required). Ricordiamo a questo proposito come si inizializza un array di tipo nativo:
int valori[] = {32, 53, 28, 85, 21};
nello stesso modo si può inizializzare un array di tipo astratto:
point pt[] = {2.3, -1.2, 0.0, 1.4, 0.5};
ma in questo caso ogni valore di inizializzazione, relativo a un elemento dell'array, viene passato come argomento al costruttore.
Ciò è possibile in quanto, grazie alla presenza del costruttore con un solo argomento, ogni valore è convertito implicitamente in un oggetto
della classe point (chiamiamolo pn) e quindi questa espressione precedente diventa:
point pt[] = {p0, p1, p2, p3, p4};
L'inizializzazione in questa forma di un array di un certo tipo, tramite elementi dello stesso tipo precedentemente costruiti, è comunque sempre consentita,
anche per i tipi astratti.
Non esiste invece alcuna possibilità di utilizzare costruttori con due o più argomenti nel caso di array.
Link utili
http://www.bo.cnr.it/corsi-di-informatica/corsoCstandard/Lezioni/27Classi.html
Il linguaggio C non contiene alcuna istruzione di Input/Output. Tali operazioni vengono svolte mediante
chiamate a funzioni definite nella libreria standard contenute nel file stdio.h. Tali funzioni rendono possibile
la lettura/scrittura in modo indipendente dalle caratteristiche proprie dei dispositivi di Input/Output. Le stesse
funzioni possono essere utilizzate, ad esempio, sia per leggere un valore dalla tastiera sia per leggere un
valore da un dispositivo di memoria di massa. Lo stesso vale per le funzioni di scrittura: le stesse operazioni
possono essere utilizzate sia per la visualizzazione sullo schermo sia per scrivere un valore su un disco o
una stampante. Ciò è possibile poichè il sistema di I/O C è caratterizzato da un’interfaccia indipendente dal
dispositivo effettivo che si interpone tra il programmatore e il dispositivo. Tale interfaccia è chiamata
flusso,
mentre il dispositivo effettivo è chiamato file.
Il sistema di I/O C associa ad ogni dispositivo fisico un dispositivo logico chiamato flusso. Poichè tutti i flussi
si comportano alla stessa maniera, possono essere utilizzate le stesse funzioni per la loro gestione.
Esistono due tipi di flussi: flussi binari e di testo.
Un flusso binario è formato da una sequenza di byte con
una corrispondenza uno ad uno con i byte presenti sul dispositivo fisico.
Un flusso di testo è una sequenza di caratteri generalmente suddivisa in linee terminate da un carattere di newline.
Un File è un qualsiasi dispositivo, da un disco a un monitor a una stampante. Per associare un
flusso a un
file è necessario un’operazione di apertura.
Una volta aperto un file sarà possibile scambiare informazioni tra
il file e il programma.
Per eliminare l’associazione tra flusso e file è necessaria un’operazione di chiusura.
Nel caso un file aperto
in scrittura, l’eventuale contenuto del flusso viene scritto sul dispositivo fisico.
Ogni flusso ha associato una struttura chiamata FILE contenente i seguenti campi:
- Modalità di utilizzo del file (lettura, scrittura o lettura e scrittura);
- Posizione corrente su file (indicante il prossimo byte da leggere o scrivere su file);
- Un indicatore di errore di lettura/scrittura;
- Un indicatore di end-of-file, indicante il raggiungimento della fine del file.
Ogni operazione di apertura a file restituisce un puntatore a una variabile di tipo FILE. Per potere leggere o scrivere i file è necessario usare delle variabili di tipo puntatore a FILE, dichiarate nel seguente modo:
FILE *fp;
L’apertura di un file viene realizzata mediante la funzione fopen() avente il seguente prototipo:
FILE * fopen ( const char * nomefile, const char * mode );
dove nomefile è una stringa di caratteri indicante il nome del file da aprire e
mode è la modalità che indica il modo
in cui il file deve essere aperto. Il parametro mode assume i seguenti
valori:
| Modalità file testuali | |
|---|---|
| mode | significato |
| r | Apre un file di testo in lettura |
| w | Crea un file di testo in scrittura |
| a | Apre un file di testo in modalità append |
| r+ | Apre un file di testo in lettura/scrittura |
| w+ | Crea un file di testo in lettura/scrittura |
| a+ | Crea o apre un file di testo in modalità append per lettura/scrittura |
| Modalità file binari | |
|---|---|
| mode | significato |
| rb | Apre un file binario in lettura |
| wb | Crea un file di binario in scrittura |
| ab | Apre un file di binario in modalità append |
| r+b | Apre un file di binario in lettura/scrittura |
| w+b | Crea un file di binario in lettura/scrittura |
| a+b | Crea o apre un file di binario in modalità append per lettura/scrittura |
Se si verifica un errore in apertura del file, la fopen() restituisce un puntatore nullo.
La chiusura di un file viene realizzata mediante la funzione fclose avente il seguente prototipo:
int fclose ( FILE *fp );
dove fp è il puntatore restituito dalla fopen().
La funzione feof() restituisce un valore logico vero nel caso in cui è raggiunta la fine del file e zero in tutti gli altri casi. Il prototipo della feof è il seguente:
int feof ( FILE *fp );
dove fp è il puntatore restituito dalla fopen().
La funzione fprintf() è utilizzata per la scrittura su file testuali. Il suo comportamento è lo stesso della funzione printf(). Il suo prototipo è il seguente:
int fprintf ( FILE *fp, const char *formato, ... );
dove fp è il puntatore restituito dalla fopen(). La funzione restituisce il numero di caratteri scritti. Se si verifica un errore di scrittura la funzione restituisce un numero negativo corrispondente all'errore che viene rilevato con la funzione ferror().
La funzione fscanf() è utilizzata per la lettura di file testuali. Il suo comportamento è lo stesso della funzione scanf(). Il suo prototipo è il seguente:
int fscanf ( FILE *fp, const char *formato, ... );
dove fp è il puntatore restituito dalla fopen(). In caso di successo la funzione restituisce il numero di elementi della lista degli argomenti che sono stati correttamente
letti. Questo conteggio potrebbe essere inferiore a causa di:
- una non corrispondenza dei parametri rispetto alla maschera indicata in formato.
- un errore di lettura
- il raggiungimento della fine del file
Quando arrivo in fondo al file feof() ritorna true.
Link utili
http://www.math.unipd.it/~sperduti/CORSO-C%2B%2B/Strutture.htmm