(pubblicato il 20/11/2009)
SHELL UNIX - I COMANDI PRINCIPALI
(tratto dal sito:
http://www.freebsd.org/doc/it/books/unix-introduction/index.html)
CENNI STORICI
1965 Bell Laboratory con la collaborazione del MIT e della General Electric
lavorano per la realizzazione di un nuovo sistema operativo, Multics, il quale
vuole fornire, come principali caratteristiche, capacità multi-utente (multi-user),
multi-processo (multi-process) e un file system multi-livello (gerarchico) (multi-level
file system).
1969 AT&T non era soddisfatta del progresso di Multics e abbandona il progetto. Ken
Thompson, Dennis Ritchie, Rudd Canaday e Doug McIlroy, alcuni programmatori dei
Bell Lab che avevano lavorato nel progetto Multics, progettano ed implementano su
un PDP-7 la prima versione del file system Unix insieme ad alcune utility. Il
nome Unix è stato assegnato da parte di Brian Kernighan come gioco di parole su
Multics.
Dennis Ritchie (a destra) con Ken Thompson

Il suo primo reale impiego è come strumento di manipolazione del testo in
esclusiva per il dipartimento dei Bell Lab. Quel tipo di utilizzo giustifica
ulteriormente la ricerca e lo sviluppo attraverso la programmazione di gruppo.
Unix attira i programmatori perché è stato progettato con queste
caratteristiche:
- possiede un ambiente di programmazione;
- ha una semplice interfaccia utente (rispetto ai tempi!);
- semplici utility che possono essere combinate tra loro per realizzare potenti funzioni;
- file system gerarchico (ad albero);
- semplice interfacciamento con i dispositivi, simile a quello usato per i
file;
- sistema multi-utente e multi-processo;
- architettura indipendente e trasparente all'utente.
CRONOSTORIA
1 Gennaio 1970 Inizio di Unix.
1971 Il sistema ora gira su un PDP-11 con 16 Kbyte di memoria, di cui 8 Kbyte
dedicati ai programmi utente (il resto è per il sistema operativo), e con un disco di 512 Kbyte.
1973 Unix è riscritto prevalentemente in C, un nuovo linguaggio di
programmazione sviluppato da Dennis Ritchie. La codifica in questo linguaggio di
alto livello diminuisce fortemente lo sforzo necessario per portare Unix su
nuove macchine.
1974 Thompson e Ritchie descrivono in una relazione pubblicata in un comunicato
dell'ACM il nuovo sistema operativo Unix. Unix genera entusiasmo nella comunità
accademica che lo vede come un potente strumento di insegnamento per lo studio
della programmazione di sistemi.
1977 Ci sono circa 500 siti Unix nel mondo.
1984 Ci sono circa 100.000 siti Unix che girano su differenti piattaforme
hardware, con differenti capacità.
1988 AT&T e Sun Microsystem sviluppano System V Release 4 (SVR4). Questo sarà in
futuro implementato in UnixWare (Novell) e Solaris 2 (Sun).
1993 Novell compra Unix da AT&T.
1994 Novell porta il nome UNIX a X/OPEN.
1995 Santa Cruz Operation e Hewlett-Packard annunciano lo sviluppo di una
versione di Unix a 64 bit.
1996 International Data Corporation prevede che nel 1997 ci saranno 3 milioni di
sistemi Unix nel mondo.
STRUTTURA DI UNIX
Unix è un sistema operativo a strati. Lo strato più interno è l'hardware
il quale fornisce servizi al OS. Il modulo di sistema operativo (riferito in
Unix) che interagisce direttamente con l'hardware si dice kernel e fornisce i servizi necessari
sia ai livelli superiori del OS che ai
programmi utente. I programmi utente non necessitano di conoscere informazioni
sull'hardware. Devono solo sapere come interagire con il kernel ed è
quest'ultimo a fornire i servizi richiesti. Uno dei principali motivi che ha
contribuito al successo di Unix da parte dei programmatori è stato che molti
programmi utente corretti sono indipendenti dall'hardware sottostante, e ciò li
rende facilmente trasportabili su nuovi sistemi.
I programmi utente interagiscono con il kernel attraverso un set di system call
(chiamate di sistema) standard. Queste system call chiedono dei servizi, servizi
che saranno forniti dal kernel. Così i servizi possono includere l'utilizzo di
un file come ad esempio aprire, chiudere, leggere, scrivere un file, creare un link o eseguire un
file; creare o aggiornare degli account (informazioni relative ad un utente come
nome, password, ecc.); cambiare il proprietario di un file o di una directory;
spostarsi in una nuova directory; creare, sospendere o terminare un processo;
abilitare l'accesso a un dispositivo hardware e impostare dei limiti sulle
risorse di sistema.
Unix è un sistema operativo multi-user (multi-utente) e multi-tasking (multi-processo).
Si possono avere molti utenti “loggati” simultaneamente nel sistema (multi-user),
ognuno dei quali esegue alcuni programmi (multi-tasking). È compito del kernel
mantenere ogni processo e ogni utente separato e regolare l'accesso all'hardware
di sistema, inclusa la cpu, la memoria, il disco e altri dispositivi di I/O.
FIGURA 1 Struttura di un sistema Unix
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
| |
| Programmi |
| |
| _ _ _ _ _ System Call _ _ _ _ _ _ |
| | | |
| | Kernel | |
| | _ _ _ _ _ _ _ _ _ _ _ _ _ _ | |
| | | Hardware | | |
| | |_ _ _ _ _ _ _ _ _ _ _ _ _ _| | |
| | | |
| | | |
| |_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _| |
| |
|_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _|
L'aspetto del file system di
Unix è paragonabile alla struttura rovesciata di un albero. Si parte dall'alto
con la directory root, denotata con /, per poi scendere attraverso
sotto-directory sottostanti la root.
FIGURA Struttura del filesystem di Unix
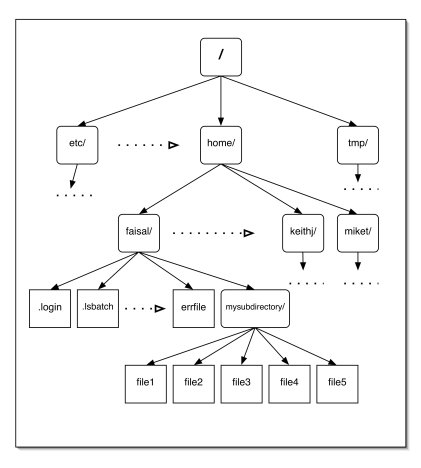
La logica del file system Unix è semplice,
elegante e potente, alcune sue caratteristiche sono comuni al DOS, altre
all'antico MULTICS, altre sono uniche.
Le directory, a livello di sistema, sono trattate come dei file che
invece di contenere dei dati contengono riferimenti a altri file o directory.
In generale, un file contiene delle informazioni (data) ed è caratterizzato da
alcune proprietà, come il tipo, la dimensione, i permessi di accesso, ...,
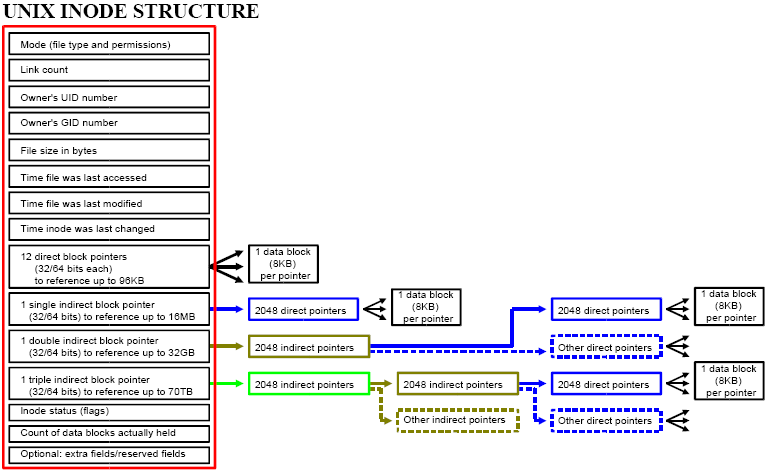
ovvero quelli che vengono denominati metadati (metadata). Il filesystem ext2
memorizza i metadati di un file in un’apposita struttura, detta index node, o
più comunemente inode, mentre le informazioni contenute nel file sono
memorizzate nei blocchi, denominati anche data block. Ogni inode ha la
struttura riportata nella figura sottostante ed il numero di inode ammessi è fissato alla
creazione del filesystem (per default viene creato un inode ogni 4096 byte
disponibili nella partizione considerata). Quando tutti gli inode saranno
utilizzati (allocati) da altrettanti file, non sarà più possibile creare altri
file anche se ci sono data block liberi.
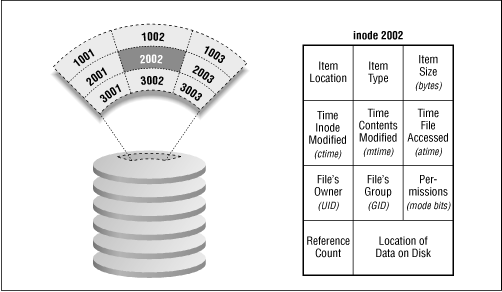
Il nome dei file può avere qualsiasi carattere (escluso NUL), anche caratteri
speciali per la shell o spazi e CR (Carriage Return).
Le estensioni non hanno nessuno specifico significato: sono usate per comodità
da alcuni comandi ma non sono indispensabili e, a livello del file system,
nemmeno identificano il tipo di file.
Una tipica partizione Unix contiene un file system così organizzato:
- Blocco 0, non usato da Unix, a volte usato per il boot del sistema (è l'MBR se
si trova sul device primario);
- Blocco 1 o superblock, contiene informazioni critiche sulla struttura del file
system (numero di i-node, numero di blocchi del disco ecc);
- Elenco degli I-node, numerati da 1 a un numero finito, che contengono le
informazioni sui singoli file presenti nel file system e sulla posizione dei
rispettivi dati;
- Blocchi dei dati, con i dati effettivi contenuti nel file.
Tramite l'uso di link è
possibile fare in modo che lo stesso i-node sia condiviso da diversi oggetti nel filesystem.
FIGURA Esempio di link
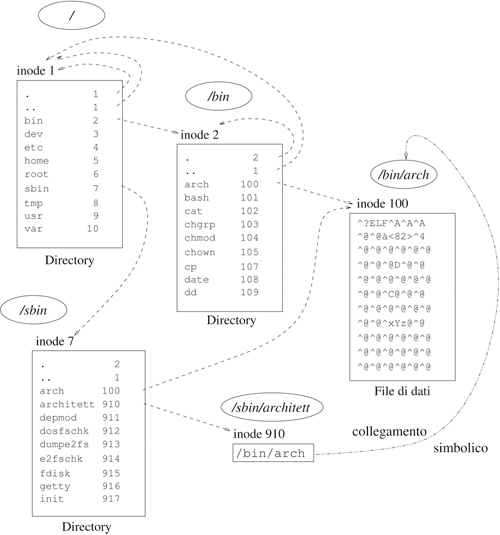
Dal punto di vista utente ogni nodo è o un file o una
directory di file, dove quest'ultima può contenere altri file e directory. Un
file o una directory vengono specificati attraverso il loro pathname (percorso
del nome del file o della directory), il quale può essere un pathname assoluto
oppure un pathname relativo ad un'altra locazione. Un pathname assoluto inizia
con la directory root: /, seguono poi i “rami” del file system, ognuno separato
da /, fino a raggiungere il file desiderato, come per esempio:
/home/faisal/mysubdirectory/file1
Un pathname relativo specifica un percorso relativo ad un altro pathname, che
usualmente è la directory di lavoro corrente. Sono ora
introdotte due directory speciali:
. la directory corrente
.. la directory padre della directory corrente
Quindi se si è in /home/miket e si desidera specificare un path nel modo
relativo si può usare:
../faisal/mysubdirectory/file1
Questo indica che si deve prima salire di un livello di directory, quindi
passare attraverso la directory faisal, seguire la directory mysubdirectory e quindi xntp.
Ogni directory e ogni file sono inclusi nella loro directory padre. Nel caso
della directory root, la directory padre è se stessa. Una directory, come già
precisato, è un file
contenente una tabella che elenca i file contenuti nella directory stessa, dove
ai nomi dei file in lista vengono assegnati i corrispondenti numeri di inode. Un
inode è un file speciale, progettato per essere letto dal kernel al fine di
conoscere alcune informazioni su ciascun file. Un inode specifica i permessi del
file, il proprietario del file, la data di creazione, quella dell'ultimo accesso
e quella dell'ultima modifica del file e la posizione fisica dei blocchi di dati
sul disco che contengono il file.
Il sistema unix non richiede qualche struttura particolare per i dati contenuti nel
file. Il file può essere ASCII o binario o una combinazione di questi e può
rappresentare dati testuali, uno script di shell, un codice oggetto compilato
per un programma, una tabella di directory, robaccia o qualunque cosa si voglia.
Non c'è un'intestazione, una traccia, un'etichetta o il carattere EOF come parte
del file.
AVVIO DELLA SESSIONE UNIX
Per collegarsi ad un sistema UNIX (in modalità testuale) si utilizza il comando
TELNET
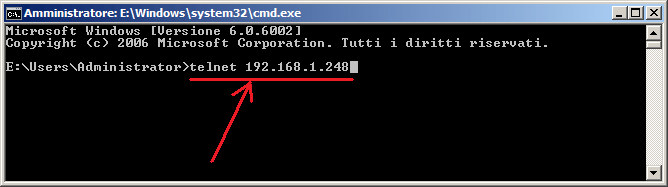
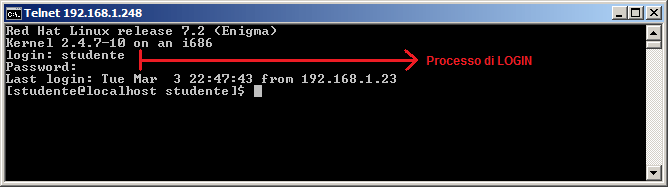
Una volta che l'utente si è collegato a un sistema
Unix (solitamente tramite un telnet), gli viene chiesto di inserire una login (username
- nome utente) e una
password (codice segreto). La login è il nome univoco dell'utente sul
sistema. La password è un codice segreto conosciuto solo dall'utente. Alla
richiesta di login, l'utente deve inserire il suo username e poi la
password.
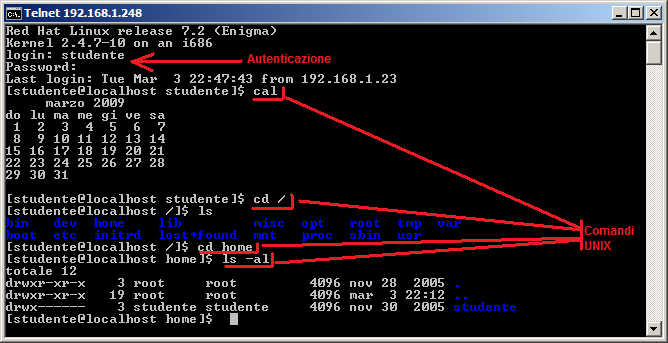
Una volta connessi è possibile digitare i comandi
testuali necessari per i nostri scopi
I tasti di controllo sono usati per realizzare
speciali funzioni sulla linea di comando o all'interno di un editor. Queste
funzioni possono essere generate premendo contemporaneamente il tasto control e
alcuni altri tasti. Questa combinazione è generalmente indicata con Ctrl+Tasto
(oppure ^Tasto). Control+S può essere scritto come Ctrl+S (oppure ^S). Con i
tasti di controllo le lettere maiuscole e minuscole sono la stessa cosa, così Ctrl+S è lo stesso di Ctrl+s. Questo particolare esempio (Ctrl+S) è un segnale
di stop e dice al terminale di non accettare più input. Il terminale rimarrà
sospeso finchè un segnale di start Ctrl+Q non sarà generato.
Ctrl+U è normalmente il segnale di “cancellazione di linea” per il proprio
terminale. Quando lo si digita, l'intera linea di input viene cancellata.
La definizione dei tasti di controllo può essere gestita tramite il comando
stty che mostra o configura le
opzioni di controllo del terminale. L'abbreviazione “tty” risale fino ai giorni
dei “teletypewriter”, che erano associati alla trasmissione di messaggi
telegrafici ed erano primitivi modelli di terminali di computer.
L'uso principale del comando stty riguarda l'assegnazione della funzione
di “cancellazione di linea” ad un tasto specifico per i loro terminali. Per i
programmatori di sistema o per chi scrive script di shell, il comando stty
fornisce uno strumento prezioso per la configurazione di molti aspetti legati al
controllo di I/O di un dispositivo specifico, inclusi i seguenti:
- carattere di erase (eliminazione carattere) e di line-kill (eliminazione
linea);
- velocità di trasmissione dati;
- controllo di parità sulla trasmissione dati;
- controllo del flusso hardware;
- carattere di nuova linea (<NL>), di return (<CR>) e di alimentazione linea (<LF>);
- interpretazione del carattere tab;
- trasformazione di lettere minuscole in lettere maiuscole.
Ecco un esempio di utilizzo di tale comando
[studente@localhost
home]$ stty
-a
speed 9600 baud; rows 26; columns 80; line = 0;
intr = ^C; quit = ^\;
erase = ^H; kill = ^U; eof = ^D; eol = <undef>;
eol2 = <undef>; start = ^Q; stop = ^S; susp = ^Z; rprnt = ^R; werase =
^W;
lnext = ^V; flush = ^O; min = 1; time = 0;
-parenb -parodd cs8 -hupcl -cstopb cread -clocal -crtscts
-ignbrk -brkint -ignpar -parmrk -inpck -istrip -inlcr -igncr icrnl ixon
-ixoff
-iuclc -ixany -imaxbel
opost -olcuc -ocrnl onlcr -onocr -onlret -ofill -ofdel nl0 cr0 tab0 bs0
vt0 ff0
isig icanon iexten echo echoe echok -echonl -noflsh -xcase -tostop
-echoprt
echoctl echoke |
Per cambiare i settaggi usando
stty, ad esempio per cambiare il carattere di erase da Ctrl+? (il tasto
elimina) a Ctrl+H:
stty erase ^H
PROMPT
Il prompt è la scritta che si vede nello schermo quando si avvia la sessione
UNIX. Quando appare il prompt significa
che il sistema è pronto per ricevere il comando che deve essere digitato
dall’utente. Un esempio di prompt è il seguente (set
PS1=$'[\\u@\\h \\W]\\$ ')
[NomeUtente@Localhost NomeCartellaCorrente]$
Il NomeCartellaCorrente indica la directory
corrente, quella cioè in cui si sta lavorando, il simbolo $ separa il prompt dal comando
che scriverà l’utente. NomeUtente è invece il nome dell'utente che si è
collegato. La forma del prompt è modificabile impostando la variabile d'ambiente
(nella shell bash) PS1
[studente@localhost
studente]$ declare PS1='Comanda e io eseguirò-->: '
Comanda e io eseguirò-->: declare PS1=$'[\\u@\\h \\W]\\$ '
[studente@localhost studente]$ |
Il prompt è seguito da un cursore lampeggiante (una I che appare e scompare
continuamente) che indica la posizione in cui verrà digitato il comando.
Impostare in modo opportuno il testo del prompt aiuta ad evidenziare sempre
con quale utente stiamo eseguendo un comando (considerate che è possibile
cambiare l'utente attivo mediante il comando su) e quale sia la cartella corrente
su cui stiamo operando. È
necessario abituarsi a leggere e capire il prompt, per evitare errore
sull'esecuzione dei comandi.
SINTASSI GENERALE DEI COMANDI
Un comando è un programma che svolge un determinato compito e fa parte del sistema Unix. Un
comando ha la forma:
comando [opzioni]
[argomenti]
dove gli argomenti indicano su cosa il comando deve realizzare la sua azione (generalmente un file o una serie di file). Un'opzione modifica il
comportamento predefinito di un comando,
cambiandone il modo di esecuzione.
I comandi UNIX (contrariamente a quelli DOS) sono case sensitive (sensibili alle lettere maiuscole e minuscole).
Quindi comando e
Comando non sono la stessa cosa.
Le opzioni sono generalmente precedute da un trattino (-) e per molti comandi,
più opzioni possono essere messe insieme nella forma:
comando
-[opzione][opzione][opzione]
ad
esempio:
ls -alR
che mostrerà un listato lungo di tutti i file che si trovano nella directory
corrente e ricorsivamente anche quelli che si trovano in tutte le
sotto-directory.
In molti comandi si possono separare le opzioni, facendole precedere ognuna da
un trattino, esempio:
comando -opzione1
-opzione2 -opzione3
come in:
ls -a -l -R
Alcuni comandi hanno opzioni che richiedono dei parametri. Le opzioni che richiedono
parametri sono di solito specificate separatamente dalle altre, esempio:
lpr -Pprinter3 -#2
file
I
parametri e gli argomenti sono di solito nomi di file o di directory, per esempio:
ls /home
È
molto importante l’utilizzo degli spazi. Gli spazi non possono essere omessi
(nella maggior parte dei casi), altrimenti il comando potrebbe essere
interpretato male, o anche potrebbe non essere riconosciuto.
Ogni comando si intende eseguito nella cartella corrente, la directory corrente
è quella in cui si lavora. Per sapere qual è la cartella corrente si deve
semplicemente leggere il nome nel prompt (se impostato con tale scopo!) oppure digitare il comando
pwd
LA
SHELL
La shell, che sta tra l'utente e il sistema
operativo, opera come un interprete di comandi. Legge l'input dal terminale e
traduce i comandi in azioni che vengono intraprese dal sistema. La shell
è simile al command.com in DOS. Una volta effettuato il login nel sistema, viene
assegnata la shell di default. La shell, al suo avvio, legge i suoi file di
inizializzazione e può settare: alcune variabili di ambiente, i path di ricerca
dei comandi, gli alias dei comandi ed eseguire qualche comando specificato in
questi file.
La prima shell è stata la shell Bourne, sh. Ogni piattaforma Unix dispone
della shell Bourne o di una shell Bourne compatibile. Questa shell ha molte
buone caratteristiche per controllare l'input e l'output, ma non è molto adatta
all'utente interattivo. Per andare incontro a quest'ultimo è stata scritta la
shell C, csh, presente ora in molti, ma non tutti, i sistemi Unix. Questa shell usa una sorta di sintassi C, il linguaggio con cui Unix è stato scritto,
ma ha molte scomode implementazioni dell'input/output. La C-shell ha il
controllo dei job, quindi può mandare un job eseguito in background (“sotto shell”)
o in foreground (“in shell corrente”). Inoltre possiede la funzione di history
(storia dei comandi) che permette di modificare e ripetere comandi eseguiti
precedentemente.
Il prompt di default per la shell Bourne è $ (o # per l'utente root). Il
prompt
di default per la shell C è %.
Sono disponibili in rete molte altre shell. Quasi tutte sono basate sulla shell
sh o csh con opportune estensioni. Alcune di queste shell potrebbero essere sul
vostro amato sistema Unix: la shell korn, ksh, di David Korn e la shell Bourne Again, bash, dal progetto
GNU Free Software Foundations, entrambe basate su sh. In seguito si
descriveranno alcune delle caratteristiche di sh e csh, così per iniziare.
La shell ha alcuni comandi built-in, chiamati anche comandi nativi. Questi
comandi sono eseguiti direttamente dalla shell (sono inclusi nel suo stesso
codice binario) e non chiamano nessun altro
programma su disco per essere eseguiti. Questi comandi built-in possono essere diversi
tra le varie shell. Vengono citati qui i comandi più comuni:
| |
case |
condizionale case |
solo sh |
| |
cd |
cambia la directory di lavoro ($HOME
di default) |
sh, csh |
| |
echo |
scrive una stringa su standard output |
sh, csh |
| |
eval |
valuta l'argomento specificato e ritorna il risultato alla shell |
sh, csh |
| |
exec |
esegue il comando specificato rimpiazzando la shell corrente |
sh, csh |
| |
exit |
esce dalla shell corrente |
sh, csh |
| |
for |
condizionale di ciclo for |
solo sh |
| |
foreach |
condizionale di ciclo for |
solo csh |
| |
if |
condizionale if |
sh, csh |
| |
repeat |
ripete un comando il numero di volte specificato |
solo csh |
| |
set |
setta le variabili di shell |
sh, csh |
| |
switch |
condizionale switch |
solo csh |
| |
test |
valuta un'espressione come vera o falsa |
solo sh |
| |
umask |
setta la maschera di default relativa ai permessi da impostare per i
nuovi file |
sh, csh |
| |
unset |
resetta le variabili di shell |
sh, csh |
| |
wait |
attente che un specifico processo termini |
sh, csh |
| |
while |
condizionale di ciclo while |
sh, csh |
L'HELP ON
LINE
Il manuale di Unix, usualmente
chiamato man page (pagine man), è disponibile per spiegare l'uso del sistema
Unix e dei suoi comandi. Per servirsi di una pagina man digitare il comando
man al prompt di sistema seguito dal comando di cui si necessitano
informazioni.
Sintassi
man [opzioni]
nome_comando
le opzioni disponibili sono visibili richiamando il comando
man --help
oppure
man man
Esempi:
Si può usare man per ottenere una elenco dei comandi che
contengono una determinata parola specificata con l'opzione -k, ad esempio per
cercare la parola login, si digita:
|
[studente@localhost etc]$
man -k login
chsh (1) - change your
login shell
faillog (5) - Login failure logging file
faillog (8) - examine faillog and set
login failure limits
login (1) - sign on
logname (1) - print user's login name
nologin (8) - politely refuse a login
rlogin (1) - remote login
rlogind (8) - remote login server
rlogind [in] (8) - remote login server
ssh (1) - OpenSSH
SSH client (remote login program)
ssh [slogin] (1) - OpenSSH SSH client (remote login program) |
Il numero in parentesi indica la sezione delle pagine man dove sono stati
trovati i riferimenti. Si può accedere a quella pagina man (di default si fa
riferimento al numero di sezione più basso, ma si può usare un'opzione su linea
di comando per specificarne uno differente) digitando man seguito dal comando
del quale si vuole avere l'help:
[studente@localhost
home]$
man passwd
PASSWD USER COMMANDS PASSWD
NOME
passwd - cambia password
SINTASSI
passwd [ -e login_shell ] [ username ]
DESCRIZIONE
passwd cambia (o setta) la password di un utente.
passwd chiede per due volte la nuova password, senza mostrarla.
Questo per prendere in considerazione la possibilità di digitare errori.
Solamente l'utente stesso e il super-user possono cambiare la password
di un utente.
OPZIONI
-e Cambia la shell di login dell'utente. |
Qui l'output è stato parafrasato e troncato per una questione di spazio e di
copyright.
COMANDI DI NAVIGAZIONE
E CONTROLLO DELLE DIRECTORY
Il file system di Unix è organizzato come la struttura ramificata di un albero a
partire da root. La directory root
del sistema è rappresentata dal carattere di slash in avanti (/).
Le directory di sistema e quelle degli utenti sono organizzate sotto la
directory root. In Unix
esiste una sola root e quindi l'utente non ha una sua root. Generalmente dopo il login gli utenti
vengono posizionati nella loro directory
home. Gli utenti possono creare altre directory
sotto la loro directory home.
Generalmente, su quasi
ogni sistema Unix, sono presenti alcune directory che rivestono una certa
importanza all'interno del sistema e che hanno quasi sempre lo stesso nome. A
titolo di esempio consideriamo la seguente struttura ad albero che rappresenta
parte di un ipotetico filesystem (assai ridotto, per la verità):
\ ---+-- bin
|
+-- dev
|
+-- etc
|
+-- home --+-- elisa
| |
| +-- marco
| |
| +-- root
+-- lib
|
+-- proc
|
+-- tmp
|
+-- usr --+-- X11
|
+-- bin
|
+-- include
|
+-- lib
|
+-- local --+-- bin
| |
| +-- etc
| |
| +-- lib
+-- man
|
+-- spool
Diamo una rapidissima
scorsa al contenuto delle directory elencate:
| |
/bin
|
Contiene molti files
binari (eseguibili) del SO (esempio date, kill, ps, ls, ln, more, ...) |
| |
/dev |
E' una directory molto
importante che contiene i device drivers delle unità hardware installate
sul nostro sistema. Si tratta di estensioni del kernel che
permettono al sistema di gestire le unità ad esso collegate. Ad esempio
il file /dev/tty gestisce l'input/output attraverso il primo
terminale collegato al sistema,
il file /dev/console gestisce la console del sistema.
/dev/fd0 gestisce l'accesso al floppy
/dev/cdrom gestisce l'accesso al cdrom
/dev/hda gestisce il disco master attaccato al primo controller
IDE (ie disco fisso principale)
/dev/sda a grandi linee gestisce il primo disco attaccato
alla catena del controller SCSI /SATA primario
/dev/null è l'unità nulla, che risulta assai utile in alcune
situazioni, come vedremo più dettagliatamente in seguito. |
| |
/etc |
Contiene una serie di file
che non trovano collocazione migliore in altre directory; sono per lo
più file di configurazione del sistema come host.allow, httpd/conf/httpd.conf
php.ini ... |
| |
/home |
Contiene le home directory
degli utenti del sistema. |
| |
/lib |
Contiene le shared
libraries, dei file che contengono parte di codice eseguibile e che
vengono condivisi da più applicazioni. Inserire delle librerie con parti
di codice comuni a più applicazioni consente di ridurre la dimensione
dei programmi. |
| |
/proc |
E una directory piuttosto
particolare: i file che contiene non sono memorizzati su disco, ma
direttamente nella memoria dell'elaboratore; contengono i riferimenti ai
vari processi attivi nel sistema e le informazioni utili per potervi
accedere. |
| |
/tmp |
E la directory temporanea
di default. Spesso le applicazioni devono scrivere dei dati su un file
temporaneo, che al termine dell'esecuzione verrà cancellato; in questi
casi spesso usano la directory /tmp, che è sempre presente sui sistemi
Unix. |
| |
/usr |
Contiene numerose
sottodirectory molto importanti per il sistema: nulla di ciò che è
contenuto sotto la directory /usr è di vitale importanza per il
funzionamento della macchina, ma spesso è proprio sotto /usr che vengono
collocate tutte quelle cose che rendono utile il sistema.
| /usr/X11 |
Contiene tutto ciò che
riguarda l'interfaccia grafica X-Window |
| /usr/bin |
Altri eseguibili (file
binari). |
| /usr/include |
Contiene i file include per i
programmi in linguaggio C. |
| /usr/lib |
Altre librerie a collegamento
dinamico (shared libraries). |
| /usr/local |
Contiene le applicazioni
installate successivamente al sistema operativo. |
| /usr/man |
Contiene le pagine di manuale
(il sistema di help on-line del sistema Unix). |
| /usr/spool |
Contiene i files in attesa di
essere elaborati da altri programmi, ad esempio contiene la coda
di stampa ed i messaggi di posta elettronica giacenti e non
ancora letti dai rispettivi destinatari. |
|
In questa sezione
vengono presentati alcuni comandi per la navigazione tra directory
PWD
In ogni momento si può
determinare in che punto si è nella gerarchia del file system mostrando la
directory di lavoro con il comando pwd, esempio:
% pwd
/home/frank/src
LS
Il comando per visualizzare le
proprie directory ed i propri file è ls. È possibile ottenere, attraverso
le opzioni, informazioni circa la dimensione, il tipo, i permessi, la data di
creazione, di modifica e di accesso del file.
Sintassi
ls [opzioni]
[argomenti]
Quando non viene usato nessun argomento, viene mostrato il contenuto della
directory corrente. Ci sono molte utili opzioni per il comando ls. Segue una
lista di alcune di queste. Quando si usa il comando con più opzioni
contemporaneamente queste vanno scritte in sequenza facendole precedere da un
singolo trattino (-).
Opzioni generali
-a mostra tutti i file, inclusi quelli che iniziano con un punto (.)
- i visualizza l'i-node di ogni file
-d mostra solo i nomi delle directory, non i file nella directory
-F indica il tipo di elemento terminandolo con un simbolo:
directory /
socket =
link simbolico @
eseguibile *
-L se il file è un link simbolico mostra le informazioni del file o della
directory a cui il link si riferisce e non quelle del link stesso
-l listato lungo: mostra quindi i modi di accesso, informazioni di link, il proprietario, la
dimensione, la data dell'ultima modifica del file.
Se il file è un link simbolico, una freccia (-->) precede il percorso del file
collegato.
L'opzione -l visualizza all'inizio una sequenza di simboli composta da 10 caratteri.
Tale sequenza mostra il tipo e le modalità di accesso al file. Il primo
carattere di tale sequenza può essere:
| |
d |
directory |
| |
- |
file ordinario |
| |
b
|
file speciale per
dispositivi a blocchi
(device relativi a memorie di massa) |
| |
c |
file speciale per
dispositivi a caratteri
(device come stampanti e terminali) |
| |
l |
link simbolico |
| |
p |
named pipe
Quando due processi devono comunicare tra loro con
una pipe ma sono del tutto separati (ovvero non hanno modo di scambiarsi
tra loro dei descrittori di file o HANDLE), è possibile creare nel file
system un file speciale detto FIFO o named pipe, che funge da punto di
accesso alla pipe: scrivendo su questo file speciale si inviano dati
alla pipe, mentre leggendolo si possono prelevare. È da sottolineare che
i dati scambiati non sono memorizzati temporaneamente nel file system,
ma transitano da un processo all'altro tramite un buffer. In questo
modo, un processo può offrire un servizio ad altri processi aprendo una
named pipe in una posizione nota del file system. Nei sistemi operativi
Unix e Unix-like si può creare una named pipe tramite il comando mknod
consente la creazione di dispositivi
mknod /tmp/prova
p
crea una named pipe di nome prova - Lo stesso
risultato era ottenibile con questo comando
mkfifo /tmp/prova |
| |
s |
socket
Nei sistemi operativi moderni, un socket è
un'astrazione software progettata per poter utilizzare delle API
standard e condivise per la trasmissione e la ricezione di dati
attraverso una rete. È il punto in cui il codice applicativo di un
processo accede al canale di comunicazione per mezzo di una porta,
ottenendo una comunicazione tra processi che lavorano su due macchine
fisicamente separate. |
I 9 caratteri successivi sono raggruppati in 3 blocchi di 3 caratteri ciascuno.
Indicano i permessi di accesso al file: i primi 3 caratteri si riferiscono ai
permessi del proprietario del file, i successivi 3 ai permessi degli utenti del
gruppo Unix assegnato al file e gli ultimi 3 caratteri ai permessi degl'altri
utenti sul sistema. Possono assumere i seguenti simboli:
r permesso di lettura
w permesso di scrittura
x permesso di esecuzione
- permesso negato
Esempi:
Per mostrare i file della directory corrente
%
ls
demofiles frank linda
Per mostrare tutti i file in una directory, inclusi i file
nascosti (iniziano con un punto):
%
ls -a /home
. .cshrc .history .plan .rhosts frank
.. .emacs .login .profile demofiles linda
Per avere un listato lungo:
%
ls -al
total 24
drwxr-sr-x 5 workshop acs 512 Jun 7 11:12 .
drwxr-xr-x
6 root sys 512 May 29 09:59 ..
-rwxr-xr-x
1 workshop acs 532 May 20 15:31 .cshrc
lrwxrwxrwx
1 root root 10 nov 28 2005 rc0.d -> rc.d/rc0.d
crw--w----
1 root root 4 mar 3 22:12 tty0
brw-rw---- 1 root
floppy 2 ago 30 2001 fd0
-rwxr-xr-x 1 workshop acs 413 May 14 09:36 .profile
prw-r--r--
1 root root 0 nov 24 13:54 prova
drwx------ 2 workshop acs 512 May 21 10:48 frank
drwx------ 3 workshop acs 512 May 24 10:59 linda
CD
cd è l’abbreviazione di Change Directory, cambia cartella, e serve appunto per
cambiare la directory corrente, ossia per lavorare in un’altra cartella.
cd accetta sia pathname
(percorsi) assoluti sia pathname relativi.
Sintassi
cd [directory]
Esempi:
| |
cd (oppure
chdir in alcune shell) |
cambia directory |
| |
cd |
si posiziona nella directory
home dell'utente |
| |
cd / |
si posiziona nella directory
di sistema root (/) |
| |
cd .. |
sale di un livello di
directory |
| |
cd ../.. |
sale di due livelli di
directory |
| |
cd
/completo/path/name/da/root |
cambia directory rispetto a
un pathname assoluto (notare lo slash iniziale) |
| |
cd
path/da/posizione/corrente |
cambia directory rispetto a
un pathname relativo alla posizione corrente (no slash
iniziale) |
| |
cd
~ |
cambia directory rispetto
alla directory home dell'utente collegato (il carattere ~
non è valido nella shell Bourne sh). |
MKDIR
La gerarchia della propria directory home si estende creando sotto-directory
all'interno di essa. Questo è possibile con il comando mkdir, crea
directory. Di nuovo si può specificare un pathname assoluto o relativo per la
directory che si vuole creare.
Sintassi
mkdir [opzioni]
directory
Esempi:
% mkdir /home/frank/data
oppure se la directory di lavoro corrente è /home/frank, il
seguente comando è equivalente:
% mkdir data
RMDIR
Per rimuovere una directory è necessario che questa sia vuota. Altrimenti
bisogna prima rimuovere i file contenuti in essa. Inoltre, non si può rimuovere
una directory se questa è la directory di lavoro corrente, bisogna prima uscire
da quest'ultima.
Sintassi
rmdir directory
Esempi:
Per rimuovere la directory vuota /home/frank/data mentre si è in /home/frank
usare:
% rmdir data
oppure
% rmdir /home/frank/data
Per rimuovere una directory non vuota occorre utilizzare il
comando rm con l'opzione -r.
TREE
Il comando accetta come argomento una directory
(se omessa usa la cartella corrente) . Mostra l'albero gerarchico delle cartelle/file
sottese alla cartella indicata come argomento.
Esempio:
[studente@localhost
home]$ tree
.
`-- studente
|-- caio
|-- pippo
|-- pluto
| |-- caio
| |-- paperoga
| | |-- caio
| | |-- pippo
| | |-- typescript
| | |-- users
| | |-- users.lnk
| | `-- users2
| |-- pippo
| |-- typescript
| |-- users
| |-- users.lnk
| `-- users2
|-- typescript
|-- users
|-- users.lnk -> users
`-- users2
3 directories, 18 files |
COMANDI DI GESTIONE
PER I FILES
CP
Il
comando cp copia il contenuto di un file in un altro file.
Sintassi
cp [opzioni]
filename1 filename2
Opzioni generali
-i interattivo (chiede conferma prima di procedere)
-r copia ricorsivamente una directory
Esempi:
% cp filename1 filename2
Con questo comando si hanno due copie del file, ognuna con un identico contenuto. Questi file sono
completamente indipendenti tra loro e possono essere editati e modificati
entrambi quando necessario. Ciascuno di essi ha il proprio inode, i propri
blocchi di dati e il proprio elemento nella tabella di directory.
MV
Il comando mv rinomina (sposta) un file/directory.
Sintassi
mv [opzioni]
vecchio_file nuovo_file
Opzioni generali
-i interattivo (chiede conferma prima di procedere)
-f non chiede la conferma quando si sovrascrive un file esistente (ignora -i)
Esempi:
% mv vecchio_file
nuovo_file
Il file nuovo_file sostituisce vecchio_file. In realtà tutto
quello che è stato fatto è aver aggiornato l'elemento della tabella di directory
attribuendo al file un nuovo nome. Il contenuto del file rimane come era
prima della rinominazione.
RM
Il comando rm elimina un file.
Sintassi
rm [opzioni]
filename
Opzioni generali
-i interattivo (chiede conferma prima di procedere)
-r rimuove una directory ricorsivamente, rimuovendo prima i file e le directory
sottostanti
-f non chiede conferma prima di procedere (ignora -i)
Esempi:
% rm filename
Visualizzando il contento della directory si vedrà che quel file
non esiste più. In realtà tutto quello che è stato fatto è aver rimosso
l'elemento dalla tabella di directory e marcato l'inode come “non usato”. Il
contenuto del file è ancora sul disco, ma ora il sistema non ha più modo di
identificare quei blocchi di dati con il nome del file eliminato. Non c'è un
comando per “riprendere” un file che è stato eliminato in questo modo. Per
questa ragione molti utenti alle prime armi effettuano un alias del comando di
eliminazione in rm -i dove l'opzione -i chiede di confermare prima di rimuovere
il file. Simili alias sono generalmente messi nel file .cshrc per la shell C (csh).
COMANDI DI GESTIONE
DEI PERMESSI SUI FILES/DIRECTORY
Ciascun file e directory ha permessi che
stabiliscono chi può leggerlo, scriverlo e/o eseguirlo. Per scoprire i permessi
assegnati ad un file, può essere usato il comando ls con l'opzione -l.
Quando si usa il comando
ls -l su un file l'output mostrato
sarà come il
seguente:
-rwxr-x--- user Unixgroup size Month nn
hh:mm filename
La zona dedicata ai caratteri e trattini (-rwxr-x---) è la zona che mostra il
tipo di file e i permessi del file, come spiegato nella precedente sezione.
Quindi la stringa di permessi dell'esempio, -rwxr-x---, permette al proprietario
user del file di leggerlo, modificarlo ed eseguirlo; gli utenti del gruppo
Unixgroup del file possono leggerlo ed eseguirlo; gli altri utenti del sistema
non possono accedere in alcun modo al file.
CHMOD
Il comando per cambiare i permessi ad un elemento
(file, directory, ecc.) è chmod (cambio dei modi). La sintassi richiede l'uso
di un opzione a tre cifre (rappresentanti i permessi del proprietario (u),
i permessi del gruppo (g) e i permessi degli altri utenti (o))
seguite da un argomento (che può essere un nome di un file o una lista di file e
directory). Esiste una sintassi alternativa che usa una rappresentazione simbolica dei
permessi, indicando a quale utenza questi vanno applicati.
Ogni tipo di permesso è rappresentato dal proprio numero equivalente:
lettura=4, scrittura=2, esecuzione=1
o da singoli caratteri:
lettura=r, scrittura=w, esecuzione=x
Il permesso 4 o r specifica il permesso di lettura. Se i permessi desiderati
sono lettura e scrittura, il 4 (rappresentante la lettura) e il 2
(rappresentante la scrittura) sono addizionati per ottenere il permesso 6.
Quindi, un permesso settato a 6 vorrà concedere un permesso di lettura e di
scrittura.
Nella notazione simbolica si usa un carattere
rappresentativo per l'utenza a cui ci si riferisce, uno per il permesso e uno
per l'operazione, dove l'operazione può essere:
+ aggiunge permessi
- rimuove permessi
= setta permessi
Quindi per settare i permessi di lettura e di scrittura per il proprietario del
file si usa nella notazione simbolica l'opzione u=rw.
Sintassi
chmod nnn [lista
argomenti] modalità numerica
dove nnn sono i tre numeri rappresentanti i permessi del
proprietario, del gruppo e degli altri utenti; oppure
chmod [chi][op][perm] [lista argomenti]
modalità simbolica
[chi] può essere u,g,o (user, group,
others) oppure a (all),
[op] è l'operazione e può essere: +,-,=
(aggiunge/rimuove/setta) i permessi
[perm] può
essere r,w,x.
Nella notazione simbolica si può separare la specifica dei
permessi con una virgola, come mostrato nel prossimo esempio.
Opzioni generali
-f forza (nessun messaggio di errore viene generato se la modifica non ha avuto
successo)
-R discesa ricorsiva attraverso la struttura delle directory e cambio dei modi
Esempi:
Se i permessi desiderati per il file1 sono: proprietario: lettura, scrittura ed
esecuzione; gruppo: lettura ed esecuzione; altri: lettura ed esecuzione; il
comando da usare è:
chmod 755 file1
oppure
chmod u=rwx,go=rx
file1
Ecco uno schema riassuntivo che illustra il
significato dei permessi relativamente ai files:
|
0 |
- |
nessuna abilitazione |
|
1 |
x |
permesso di esecuzione del file |
|
2 |
w |
permesso di modifica del file |
|
4 |
r |
permesso di lettura del file |
Nel caso di directory i permessi rwx
assumono i seguenti significati:
|
0 |
- |
non è possibile accedere a tale cartella mediante il
comando cd. Non è possibile listare i contenuti ne creare ne
eliminare files
[studente@localhost home]$
whoami
studente
[studente@localhost home]$
ls -l
totale 24
drwxr-xr-x 2 root root 16384 nov 19 2004 lost+found
drwx------
2 root root 4096 apr 22 18:59
prova
drwx------ 11 studente studente 4096 apr 22 13:25 studente
[studente@localhost home]$
ls prova
ls: prova: Permission denied
[studente@localhost home]$
mkdir prova/caio
mkdir: cannot create directory `prova/caio': Permission denied
[studente@localhost home]$
cd prova
bash: cd: prova: Permission denied
|
|
1 |
x |
posso accedere alla cartella mediante il comando cd
[studente@localhost home]$
ls -l
totale 24
drwxr-xr-x 2 root root 16384 nov 19 2004 lost+found
drwx--x--x
2 root root 4096 apr 22 18:59
prova
drwx------ 11 studente studente 4096 apr 22 13:25 studente
[studente@localhost home]$
ls prova
ls: prova: Permission denied
[studente@localhost home]$
mkdir prova/caio
mkdir: cannot create directory `prova/caio': Permission denied
[studente@localhost home]$ cd
prova
[studente@localhost prova]$ |
|
2 |
w |
creare o eliminare dei files/cartelle (devo avere
abilitato x)
[studente@localhost home]$
ls -al
totale 29
drwxr-xr-x 5 root root 4096 apr 22 18:59 .
drwxr-xr-x 19 root root 1024 apr 22 12:42 ..
drwxr-xr-x 2 root root 16384 nov 19 2004 lost+found
drwx--x-wx
2 root root 4096 apr 22 19:14
prova
drwx------ 11 studente studente 4096 apr 22 13:25 studente
[studente@localhost home]$ ls
-l prova
ls: prova: Permission denied
[studente@localhost home]$
mkdir prova/caio
[studente@localhost home]$ cd
prova
[studente@localhost prova]$
|
|
4 |
r |
Posso elencare i contenuti della cartella. Posso accedere
ai files per nome
[studente@localhost
home]$
ls -l
totale 24
drwxr-xr-x 2 root root 16384 nov 19 2004 lost+found
drwx--xr--
3 root root 4096 apr 22 19:14
prova
drwx------ 11 studente studente 4096 apr 22 13:25 studente
[studente@localhost home]$ ls
-l prova
ls: prova/caio: Permission denied
totale 0
[studente@localhost home]$ ls
prova
caio
[studente@localhost home]$
mkdir prova/pluto
mkdir: cannot create directory `prova/pluto': Permission denied
[studente@localhost
home]$ cd
prova
bash: cd: prova: Permission denied |
CHOWN
Il proprietario di un file può essere cambiato con il comando chown. Su
molte versioni Unix questo può essere utilizzato solo dal super-user, ad
esempio, un utente normale non può attribuire i suoi file ad altri proprietari.
chown è usato come qui sotto, dove # rappresenta il prompt di shell per il
super-user.
Sintassi
# chown [opzioni]
utente[:gruppo] file (SysVR4)
#
chown [opzioni] utente[.gruppo] file
(BSD)
Opzioni generali
-R discende ricorsivamente attraverso la struttura della directory
-f forza, non riporta errori
Esempi:
%
chown nuovo_proprietario file
CHGRP
Con il comando chgrp tutti possono cambiare il gruppo dei propri file
in un altro gruppo di appartenenza.
Sintassi
chgrp [opzioni]
gruppo file
Opzioni generali
-R discende ricorsivamente attraverso la struttura della directory
-f forza, non riporta errori
Esempi:
% chgrp
nuovo_gruppo file
COMANDI DI
VISUALIZZAZIONE
Ci sono alcuni comandi che si possono usare per visualizzare o esaminare un
file. Alcuni di questi sono editor che verranno trattati più avanti. Qui si
illustreranno alcuni comandi normalmente usati per visualizzare variabili e
contenuti di un file.
ECHO
Il comando echo viene utilizzato per ripetere l'argomento assegnato al
comando stesso nel dispositivo standard di uscita. Normalmente l'argomento termina con
un carattere di fine linea, ma si può specificare un'opzione per
impedirlo.
Sintassi
echo [stringa]
Esempi:
% echo Hello Class
% echo $USER
oppure
% echo "Hello
Class"
Per impedire il carattere di fine linea (dopo la visualizzazione
non va a capo):
% echo -n Hello
Class
CAT
Il comando cat visualizza il contenuto di un file.
Sintassi
cat [opzioni]
[file]
Opzioni generali
-n precede ogni linea con un numero
-v visualizza i caratteri non stampabili, eccetto tab, new-line e form-feed
-e visualizza $ alla fine di ogni linea (prima di new-line) (quando usato con
l'opzione -v)
Esempi:
% cat filename
Si possono specificare una serie di file su linea di comando e cat li
concatenerà ciascuno a turno, seguendo lo stesso ordine di immissione, esempio:
% cat file1 file2
file3
MORE
more permette di visualizzare il contenuto di un file una schermata (pagina)
alla volta. Inoltre permette di ritornare sulla precedente pagina, di cercare
parole, ecc.
Sintassi
more [opzioni]
[filename]
Opzioni
-c pulisce lo schermo prima di visualizzare
-i ignora differenza tra maiuscole e minuscole
-linee (numero di) linee di avanzamento
Controlli interni del comando more
<spazio> per vedere la schermata successiva
<return>o<CR> per avanzare di una linea
q per uscire
h help
b torna alla schermata precedente
/parola cerca parola nel resto del file
vedere le pagine man per le altre opzioni
HEAD
Il comando head visualizza l'inizio di un file.
Sintassi
head [opzioni]
file
Opzioni generali
-n numero di linee da visualizzare partendo dall'inizio del file
Esempi:
Di default head mostra le prime 10 linee del file. Si possono
visualizzare più (o meno) linee con l'opzione -n numero o -numero, ad esempio,
per visualizzare le prime 40 linee:
% head -40
filename
oppure
% head -n 40
filename
TAIL
Il comando tail visualizza la fine di un file.
Sintassi
tail [opzioni]
file
Opzioni generali
-numero numero di linee da visualizzare, partendo dalla fine del file
Esempi:
Di default tail mostra le ultime 10 linee del file, ma si può specificare un
numero differente di linee o di byte, o un differente punto di inizio
all'interno del file. Per visualizzare le ultime 30 linee di un file, usare
l'opzione -numero:
% tail -30
filename
COMANDI UTILI SUI
FILES
Questa tabella descrive brevemente ulteriori comandi che possono risultare utili
nell'esaminare e manipolare il contenuto dei propri file.
| |
Comando |
sintassi |
| |
cmp [opzioni] |
confronta due file e mostra dove avvengono le differenze
(file di testo e file binari) |
| |
cut [opzioni]
[file] |
taglia specifici campi/caratteri dalle linee di un file.
ad esempio
cut -c 1-4
file =>
estrae le prime 4 colonne di caratteri del file. |
| |
diff [opzioni]
file1 file2 |
confronta due file e mostra le differenze (solamente
file di testo) |
| |
file [opzioni]
file |
classifica il tipo di file
[studente@localhost studente]$
file *
caio: ASCII text
typescript: ASCII text, with CRLF, LF line terminators
users: ASCII text
users.lnk: symbolic link to users
pippo: fifo (named pipe)
users2: ASCII text |
| |
find directory
[opzioni] [azioni] |
cerca un file basandosi sul tipo
(non è lo stesso visibile con il comando file) o su uno schema
[root@localhost studente]# find
. -name 'us*'
./users2
./users
./users.lnk
[studente@localhost studente]$ find . -type l
./users.lnk |
| |
ln [opzioni]
sorgente
destinazione |
Il comando ln crea un
“link” (collegamento) o un modo aggiuntivo per accedere (attribuisce un
nome addizionale) ad un file.
[root@localhost
studente]# ln -s users users.lnk
[root@localhost studente]# ls -al
totale 48
drwx------ 3 studente studente 4096 mar 4 07:44 .
drwxr-xr-x 3 root root
4096 nov 28 2005 ..
-rw-r--r-- 2 root root
159 mar 4 07:25 users
lrwxrwxrwx 1 root root
5 mar 4 07:44 users.lnk -> users |
| |
sort [opzioni]
file |
riordina le linee di un file in accordo con le opzioni
specificate |
| |
tee [opzioni]
file |
copia standard output in uno o più file
- equivale a
cat > file |
| |
touch [opzioni]
[data/ora]
file |
crea un file vuoto o aggiorna la data di accesso di un
file esistente |
| |
tr [opzioni]
stringa1 stringa2 |
traduce i caratteri di
stringa1
provenienti da standard input in quelli di
stringa2
per standard output
[root@localhost studente]# tr
abcd 1234
ciao sono marco sechi
3i1o sono m1r3o se3hi |
| |
uniq [opzioni]
file |
rimuove le linee ripetute in un file |
| |
wc [opzioni]
[file] |
mostra il numero di parole (o di caratteri o di linee)
di un file |
| |
tar [opzioni]
[file] |
utile per il backup -
riferirsi alle pagine man per i dettagli su come creare, visualizzare ed
estrarre un archivio di file. I file tar possono essere memorizzati su
nastro o su disco. |
| |
gzip/gunzip/zcat
[opzioni]
file[.gz] |
comprime o decomprime un
file. I file compressi sono memorizzati con l'estensione
.gz |
COMANDI RELATIVI ALLE
RISORSE DI SISTEMA
DF
Il comando df è usato per riportare il numero di blocchi del disco e di
inode liberi e usati per ogni file system. Il formato dell'output e le valide
opzioni dipendono dal sistema operativo e dalla versione del
programma in uso.
Sintassi
df [opzioni]
[risorsa]
Opzioni generali
-k riporta in kilobyte (SVR4)
Esempio:
[root@localhost tmp]# df
Filesystem 1k-blocks Used Available Use% Mounted on
/dev/sda2 3700100 832076 2680064 24% /
/dev/sda1 46636 6064 38164 14% /boot
none 256652 0 256652 0% /dev/shm |
DU
Il comando du (disk usage) riporta la quantità di spazio di disco usato per i file o
per le directory specificate.
Sintassi
du [opzioni]
[directory o file]
Opzioni generali
-a mostra l'uso del disco per ogni file, non solo per le sotto-directory
-s mostra solo la somma totale
-k riporta in kilobyte (SVR4)
Esempi:
du -a .
4 ./studente/.kde/Autostart/.directory
8 ./studente/.kde/Autostart
12 ./studente/.kde
4 ./studente/.screenrc
4 ./studente/.bash_logout
4 ./studente/.bash_profile
4 ./studente/.bashrc
4 ./studente/.bash_history
36 ./studente
40 .
[studente@localhost home]$
du .
8 ./studente/.kde/Autostart
12 ./studente/.kde
36 ./studenteudente |
PS
Il comando ps è usato per mostrare i processi correntemente eseguiti sul
sistema. Il formato dell'output e le valide opzioni dipendono molto dal sistema
operativo e dalla versione del programma in uso.
Sintassi
ps [opzioni]
Opzioni generali
-e tutti i processi di tutti gli utenti
-l formato lungo
-u relazione dettagliata specifica di un utente
-e anche i processi non eseguiti da terminali
-f lista completa
Nota: Poiché il comando ps è molto dipendente dal sistema, si raccomanda di
consultare le pagine man del proprio sistema per i dettagli delle opzioni e per
l'interpretazione dell'output di ps.
Esempi:
ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY
TIME CMD
100 S 500 5057 5056 0 78 0 - 610 wait4 pts/1
00:00:00 bash
000 R 500 5368 5057 0 79 0 - 766 -
pts/1 00:00:00 ps
[studente@localhost home]$
ps -u
USER PID %CPU %MEM VSZ RSS TTY
STAT START TIME COMMAND
studente 5057 0.0 0.2 2440 1284 pts/1 S
Mar03 0:00 -bash
studente 5369 0.0 0.1 2636 728 pts/1 R
02:41 0:00 ps -u
[studente@localhost home]$
ps -f
UID PID PPID C STIME TTY
TIME CMD
studente 5057 5056 0 Mar03 pts/1 00:00:00 -bash
studente 5372 5057 0 02:43 pts/1 00:00:00 ps -f |
In questo esempio è illustrata la catena
padre-figlio che dalla shell corrente permette di risalire fino al processo
iniziale init
[studente@localhost studente]$ ps -f
UID PID PPID C STIME TTY TIME CMD
studente 7444 7443 0 Nov23 pts/0 00:00:00 -bash
...
[studente@localhost studente]$ ps -ef |grep 7443
root 7443 7442 0 Nov23 pts/0 00:00:00 login -- studente
[studente@localhost studente]$ ps -ef |grep 7442
root 7442 871 0 Nov23 ? 00:00:01 in.telnetd: 192.168.1.23
...
[studente@localhost studente]$ ps -ef |grep 871
root 871 1 0 Nov23 ? 00:00:00 xinetd -stayalive -reuse -pidfil
...
[studente@localhost studente]$ ps -ef |grep 1
root 1 0 0 Nov23 ? 00:00:04 init
... |
KILL
Il comando kill manda un segnale a un processo, generalmente per
terminarlo.
Sintassi
kill [-SEGNALE]
id-processo
Opzioni generali
-l visualizza i segnali disponibili per kill
Esempi:
[studente@localhost
home]$ kill -l
1) SIGHUP 2) SIGINT
3) SIGQUIT 4) SIGILL
5) SIGTRAP 6) SIGABRT
7) SIGBUS 8) SIGFPE
9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2
13) SIGPIPE 14) SIGALRM
15) SIGTERM 17) SIGCHLD
18) SIGCONT 19) SIGSTOP
20) SIGTSTP 21) SIGTTIN
22) SIGTTOU 23) SIGURG
24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28)
SIGWINCH 29) SIGIO
30) SIGPWR 31) SIGSYS
32) SIGRTMIN 33) SIGRTMIN+1
34) SIGRTMIN+2 35) SIGRTMIN+3 36) SIGRTMIN+4
37) SIGRTMIN+5TMIN+5
38) SIGRTMIN+6 39) SIGRTMIN+7 40) SIGRTMIN+8
41) SIGRTMIN+9
42) SIGRTMIN+10 43) SIGRTMIN+11 44) SIGRTMIN+12 45)
SIGRTMIN+13
46) SIGRTMIN+14 47) SIGRTMIN+15 48) SIGRTMAX-15 49)
SIGRTMAX-14
50) SIGRTMAX-13 51) SIGRTMAX-12 52) SIGRTMAX-11 53)
SIGRTMAX-10
54) SIGRTMAX-9 55) SIGRTMAX-8 56) SIGRTMAX-7
57) SIGRTMAX-6
62) SIGRTMAX-1 63) SIGRTMAX
[root@localhost studente]#
ps -ef | grep studente
root 4979 4978 0 Mar03 pts/0 00:00:00 login --
studente
studente 4980 4979 0 Mar03 pts/0 00:00:00 -bash
root 5056 5055 0 Mar03 pts/1 00:00:00 login --
studente
studente 5057 5056 0 Mar03 pts/1 00:00:00 -bash
studente 5379 5057 0 02:47 pts/1 00:00:00 more
studente 5380
5057 1 02:48 pts/1 00:00:02 yes
[root@localhost studente]#
kill -9 5380
[2]- Killed yes
[studente@localhost studente]$ |
Con la shell C, csh e molte altre nuove
shell, si possono mettere i job in background apponendo & in fondo al comando, così come
succede per la shell sh. Questo può anche essere fatto, una volta
lanciato il comando, premendo Control+Z (segnale 19) per sospendere il job e quindi
bg <numero> per metterlo in background. Per riportarlo in foreground si digita
fg <numero>.
[studente@localhost studente]$ yes >/dev/null &
[1] 6875
[studente@localhost studente]$ ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
100 S 500 6825 6824 0 75 0 - 609 wait4 pts/2 00:00:00 bash
000 R 500 6875 6825 99 77 0 - 410 - pts/2 00:00:02 yes
000 R 500 6876 6825 0 75 0 - 766 - pts/2 00:00:00 ps
[studente@localhost studente]$ fg 1
yes >/dev/null
^Z
[1]+ Stopped yes >/dev/null
[studente@localhost studente]$ ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
100 S 500 6825 6824 0 75 0 - 609 wait4 pts/2 00:00:00 bash
000 T 500 6875 6825 87 74 0 - 410 do_sig pts/2 00:00:57 yes
000 R 500 6877 6825 0 77 0 - 766 - pts/2 00:00:00 ps
[studente@localhost studente]$ bg 1
[1]+ yes >/dev/null &
[studente@localhost studente]$ ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
100 S 500 6825 6824 0 75 0 - 609 wait4 pts/2 00:00:00 bash
000 R 500 6875 6825 78 80 0 - 410 - pts/2 00:01:03 yes
000 R 500 6878 6825 0 76 0 - 766 - pts/2 00:00:00 ps
[studente@localhost studente]$ kill -19 6875
[studente@localhost studente]$
[1]+ Stopped yes >/dev/null
[studente@localhost studente]$ ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
100 S 500 6825 6824 0 75 0 - 609 wait4 pts/2 00:00:00 bash
000 T 500 6875 6825 93 75 0 - 410 do_sig pts/2 00:06:09 yes
000 R 500 6886 6825 0 76 0 - 766 - pts/2 00:00:00 ps
[studente@localhost studente]$ kill -18 6875
[studente@localhost studente]$ ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
100 S 500 6825 6824 0 75 0 - 609 wait4 pts/2 00:00:00 bash
000 R 500 6875 6825 78 80 0 - 410 - pts/2 00:01:03 yes
000 R 500 6878 6825 0 76 0 - 766 - pts/2 00:00:00 ps
[studente@localhost studente]$
|
Si possono avere molti job eseguiti in background. Quando questi sono in
background, non sono connessi alla tastiera per l'input, ma possono tuttavia
mostrare l'output nel terminale che finisce per mischiarsi disordinatamente con qualsiasi cosa sia
digitata o mostrata del job corrente. Si può avere la necessità di ridirigere I/O in o da un file per un job in background. La tastiera è
connessa solo con il corrente job in foreground.
Il comando built-in jobs permette di elencare i propri job in background.
Si può usare il comando kill per terminare un job in background. In
questi comandi, con la notazione %n ci si riferisce all'n-esimo job in
background, rimpiazzando n con il numero di job visualizzato nell'output di
jobs.
Quindi si termina il secondo job in background con kill %2 e si riprende il
terzo job in foreground con fg %3.
[studente@localhost studente]$ yes >/dev/null &
[1] 6919
[studente@localhost studente]$ yes >/dev/null &
[2] 6920
[studente@localhost studente]$ yes >/dev/null &
[3] 6921
[studente@localhost studente]$ yes >/dev/null &
[4] 6922
[studente@localhost studente]$ yes >/dev/null &
[4] 6923
[studente@localhost studente]$ jobs
[1] Running yes >/dev/null &
[2] Running yes >/dev/null &
[3] Running yes >/dev/null &
[4]- Running yes >/dev/null &
[5]+ Running yes >/dev/null &
[studente@localhost studente]$ fg 3
yes >/dev/null
^s
[3]+ Stopped yes >/dev/null
[studente@localhost studente]$ kill -10 %1
[studente@localhost studente]$ kill -13 %2
[studente@localhost studente]$ kill -3 %4
[studente@localhost studente]$ kill -1 %5
[studente@localhost studente]$ jobs
[1] User defined signal 1 yes >/dev/null
[2] Broken pipe yes >/dev/null
[3] Stopped yes >/dev/null
[4] Quit yes >/dev/null
[5]- Hangup yes >/dev/null
[studente@localhost studente]$ bg 3
[3]+ yes >/dev/null &
[studente@localhost studente]$ jobs
[3]+ Running yes >/dev/null &
|
WHO
Il comando who riporta chi è correntemente “loggato” nel sistema.
Sintassi
who [am i]
Esempio:
[studente@localhost
home]$ who
studente pts/1 Mar 3 22:57 (192.168.1.23)
studente pts/0 Mar 3 22:47 (192.168.1.23)
[studente@localhost home]$
whoami
studente
[studente@localhost studente]$
who am i
localhost.localdomain!studente pts/2 Mar 4 10:32 (192.168.1.23) |
WHEREIS
Il comando whereis riporta le locazioni del file sorgente, di quello
binario e del file delle pagine man associate al comando.
Sintassi
whereis [opzioni]
comando
esempio
[studente@localhost studente]$ whereis
ls
ls: /bin/ls /usr/share/man/man1/ls.1.gz
WHICH
Il comando which riporta il nome del file che sarà eseguito quando il comando
specificato viene invocato. Questo può essere un pathname assoluto o il primo
alias trovato nel proprio path.
Sintassi
which comando
esempio
[studente@localhost studente]$ which ls
alias ls='ls --color=tty'
/bin/ls
HOSTNAME
Il comando hostname (oppure uname -n) riporta il
nome host della macchina nella quale l'utente è “loggato”, esempio:
[root@localhost
studente]# hostname
localhost.localdomain
[root@localhost studente]# uname -n
localhost.localdomain
SCRIPT
Il comando script crea una documentazione della
propria sessione di I/O. Usando il comando script si possono catturare tutti i
dati trasmessi da e per il proprio terminale visuale fino all'uscita (con exit)
del programma stesso. Può essere utile durante un processo di debugging, per
documentare le azioni che si stanno sperimentando o per avere una copia
stampabile per una attenta lettura successiva.
Sintassi
script [-a] [file]
<...> exit
Opzioni generali
-a appende l'output al file passato come argomento
Di default, typescript è il nome del file usato dal comando script.
Ci si deve ricordare di digitare exit per terminare la propria sessione script e
chiudere così il file typescript (attenzione ai diritti di accesso alla cartella
corrente!).
Esempio:
[studente@localhost
home]$ pwd
/home
[studente@localhost home]$
script
typescript:
Permission denied
Terminated
[studente@localhost home]$
cd studente
[studente@localhost studente]$
script
Script iniziato, il file è typescript
[studente@localhost studente]$
whoami
studente
[studente@localhost studente]$
exitScript
effettuato, il file è typescript
[studente@localhost studente]$
cat typescript
Script iniziato
su Wed Mar 4 03:04:43 2009
[studente@localhost studente]$ whoami
studente
[studente@localhost studente]$ exit
Script effettuato su Wed Mar 4 03:04:52 2009
[studente@localhost studente]$
su root
Password:
[root@localhost studente]#
date -s "17:16:00
2009-11-23"
lun nov 23 17:16:00 CET 2009 |
DATE
Il comando date mostra la data e l'ora
corrente. Un super-user può modificare la data e l'ora.
Sintassi
date [opzioni] [+formato]
Opzioni generali
-u usa Universal Time (o Greenwich Mean Time)
+formato specifica il formato di output
%a abbreviazione giorni, da Sabato a Domenica
%h abbreviazione mesi, da Gennaio a Dicembre
%j giorno dell'anno, da 001 a 366
%n new-line
%t tab
%y ultime due cifre dell'anno, da 00 a 99
%D formato data MM/DD/YY
%H ora, da 00 a 23
%M minuti, da 00 a 59
%S secondi, da 00 a 59
%T formato ora HH:MM:SS
%s secondi dal 1/1/1970
esempi:
[studente@localhost
studente]$ su
root
Password:
[root@localhost studente]#
date -s "17:16:00
2009-11-24"
lun nov 23 17:16:00 CET 2009
[studente@localhost home]$
date +%D
11/24/09
[studente@localhost home]$
date
mar nov 4 17:16:35 CET 2009
[studente@localhost home]$
date -u
mar nov 4 17:16:41 UTC 2009
[studente@localhost home]$
date +%s
1259081037 |
LPR - LPSTAT - LPRM
Il comando lp o lpr sottopone il file specificato o lo standard
input al demone di stampa per essere stampato. Ad ogni job viene assegnato un
unico id di richiesta che può essere usato in seguito per verificare o
cancellare il job mentre è nella coda di stampa.
Sintassi
lp [opzioni]
filename
lpr [opzioni] filename
I file che iniziano (come contenuto!) con i simboli %! sono considerati file
contenenti comandi PostScript.
Esempi:
Per stampare il file ssh.ps:
% lp ssh.ps
request id is lp-153 (1 file(s))
Questo sottopone il job nella coda della stampante di default lp, con l'id di
richiesta lp-153.
Si può verificare lo stato del proprio job di stampa con il comando lpstat
o lpq.
Generalmente gli utenti possono cancellare solamente i loro job di stampa.
Sintassi
cancel [id-richiesta]
[stampante]
lprm [opzioni] [job#] [username]
PR
Il comando pr stampa l'intestazione e le informazioni traccia che
circoscrivono il file formattato. Si può specificare il numero di pagine da
stampare, le linee per pagina, le colonne, le linee bianche, si può specificare
la larghezza di pagina, l'intestazione e le informazioni traccia e in che modo
trattare il carattere tab.
Sintassi
pr [opzioni] file
Opzioni generali
+numero_pagina inizia a stampare al numero di pagina specificato
-colonne numero di colonne
-h stringa_intestazione intestazione per ogni pagina
-l linee linee per pagina
-t non stampa l'intestazione e la traccia per ogni pagina
-w larghezza larghezza di pagina
CARATTERISTICHE
PARTICOLARI: PIPE E RIDIREZIONE DELL'I/O
Uno
dei più importanti contributi che Unix ha dato ai sistemi operativi è stato
quello di fornire molti strumenti per creare lavori ordinari e per ottenere le
informazioni che si desiderano. Un altro è rappresentato dal modo standard con
cui i dati sono memorizzati e trasmessi in un sistema Unix. Questo permette di
trasferire i dati in un file, a video o nell'input di un programma, oppure da un
file, dalla tastiera o da un programma in un modo uniforme. Il
trattamento standardizzato dei dati supporta due importanti caratteristiche di
Unix: la ridirezione di I/O e il piping.
Con la ridirezione l'output di un comando viene ridiretto su un
file invece che sul terminale video. Sempre tramite la ridirezione l'input
di un comando può essere preso da un file piuttosto che dalla tastiera. Sono
possibili altre tecniche di ridirezione dell'input e dell'output come si vedrà
in seguito. Con il piping, l'output di un comando può essere usato come input di
un comando successivo. In questo capitolo si discuterà di alcune delle
caratteristiche e degli strumenti disponibili per gli utenti Unix.
Ci sono 3 descrittori di file standard:
| |
stdin |
0 |
Standard input per il programma
|
| |
stdout |
1 |
Standard output dal programma |
| |
stderr
|
2 |
Standard error (output) dal programma |
Normalmente l'input viene preso dalla tastiera o da un file. Analogamente
l'output, sia stdout che stderr, scorre sul terminale, ma può essere ridiretto,
uno o entrambi, su uno o più file.
RIDIREZIONE
La
ridirezione dell'output prende l'output di un comando e lo posiziona nel file
specificato. La ridirezione dell'input legge il file specificato come input per
un comando. La tabella che segue sintetizza le possibili modalità di ridirezione.
| SIMBOLO |
RIDIREZIONE |
| > |
ridirezione dell'output |
| >! |
come sopra, ma non tiene conto dell'opzione
noclobber per
csh (quindi se il
file di destinazione esiste lo sostituisce) |
| >> |
appende l'output |
| >>! |
come sopra, ma non tiene conto dell'opzione
noclobber su
csh
e crea il file se non esiste |
| | |
incanala (pipe) l'output nell'input di un altro comando |
| < |
ridirezione dell'input |
| <<Stringa |
legge da standard input fino a quando incontra una linea contenente
solo la parola
Stringa.
[root@localhost studente]# cat
<<fine
> ciao sono marco
> e abito a brescia
> fine
ciao sono marco
e abito a brescia |
Un esempio di ridirezione dell'output è:
cat file1 file2 >
file3
Il precedente comando concatena file1 e file2 e ridirige (manda) l'output in
file3. Se file3 non esiste, viene creato. Se esiste, verrà troncato a lunghezza
zero prima che il nuovo contenuto sia inserito, oppure, se l'opzione noclobber
della shell csh è abilitata, il comando verrà rifiutato. I file originali file1 e file2 rimarranno come erano prima
dell'esecuzione del comando, ossia due entità separate.
L'output viene appeso a un file con la forma:
cat file1 >> file2
Questo comando appende il contenuto di file1 alla fine dell'esistente file2
(file2 non viene soprascritto).
L'input è ridiretto (preso) da un file con la forma:
programma < file
Questo comando prende come input per il programma il contenuto del file.
Nella
shell csh la ridirezione verso file particolari è così definita:
|
comando >& file |
ridirige stdout e
stderr assieme in file |
|
comando >>& file |
appende stdout e
stderr in file |
|
(comando > out_file) >& err_file |
ridirige lo stdout e
lo stderr in due file separati: out_file e err_file |
Nella bourne shell sh la ridirezione verso file particolari è così
definita:
| comando 2>
file |
ridirige stderr
in file |
| comando >
file 2>&1 |
ridirige stdout
e stderr in file |
| comando >>
file 2>&1 |
appende stdout e
stderr in file |
|
comando 1> out_file 2>
err_file |
ridirige lo stdout e
lo stderr in due file separati: out_file e err_file |
esempio:
[studente@localhost /]$ find /etc/httpd 1> /dev/null
find: /etc/httpd/conf/ssl.crl: Permission denied
find: /etc/httpd/conf/ssl.crt: Permission denied
find: /etc/httpd/conf/ssl.csr: Permission denied
find: /etc/httpd/conf/ssl.key: Permission denied
find: /etc/httpd/conf/ssl.prm: Permission denied
[studente@localhost /]$ find /etc/httpd 2> /dev/null
/etc/httpd
/etc/httpd/conf
/etc/httpd/conf/ssl.crl
/etc/httpd/conf/access.conf
/etc/httpd/conf/httpd.conf
/etc/httpd/conf/magic
/etc/httpd/conf/srm.conf
/etc/httpd/conf/Makefile
/etc/httpd/conf/ssl.crt
/etc/httpd/conf/ssl.csr
/etc/httpd/conf/ssl.key
/etc/httpd/conf/ssl.prm
/etc/httpd/logs
/etc/httpd/modules
[studente@localhost studente]$ find /etc/httpd
/etc/httpd
/etc/httpd/conf
/etc/httpd/conf/ssl.crl
find: /etc/httpd/conf/ssl.crl: Permission denied
/etc/httpd/conf/access.conf
/etc/httpd/conf/httpd.conf
/etc/httpd/conf/magic
/etc/httpd/conf/srm.conf
/etc/httpd/conf/Makefile
/etc/httpd/conf/ssl.crt
find: /etc/httpd/conf/ssl.crt: Permission denied
/etc/httpd/conf/ssl.csr
find: /etc/httpd/conf/ssl.csr: Permission denied
/etc/httpd/conf/ssl.key
find: /etc/httpd/conf/ssl.key: Permission denied
/etc/httpd/conf/ssl.prm
find: /etc/httpd/conf/ssl.prm: Permission denied
/etc/httpd/logs
/etc/httpd/modules
[studente@localhost studente]$ find /etc/httpd >/dev/null 2>&1
[studente@localhost studente]$ find /etc/httpd >/dev/null 2>/dev/null
[studente@localhost studente]$ |
Con la shell Bourne si possono specificare altri descrittori di file (da 3 a 9)
e ridirigere l'output attraverso questi. Questo può essere fatto con la forma:
n>&m
ridirige il descrittore di file
n sul descrittore di file
m
Questo meccanismo viene utilizzato per mandare stderr nello stesso posto di
stdout, 2>&1, quando si vuole avere i messaggi di errore e i normali messaggi in
un file piuttosto che sul terminale. Se si vuole che solamente i messaggi di
errore vadano nel file, si può usare un descrittore di file di supporto, 3. Si
ridirige prima 3 su 2, quindi 2 su 1 e in fine si ridirige 1 su 3.
$ (comando 3>&2
2>&1 1>&3) > file
Questo manda stderr in 1 e stdout in 3 che è ridiretto su 2. In
questo modo, in effetti, si ribaltano i normali significati dei descrittori di
file 1 e 2.
Si può sperimentare tutto questo con l'esempio seguente:
$ (cat file 3>&2
2>&1 1>&3) > errfile
Quindi se file è letto, l'informazione è scartata dall'output del comando, ma se
file non può essere letto, i messaggi di errore sono messi nel file errfile per
usi futuri.
I descrittori di file che sono stati creati possono essere chiusi con:
| |
m<&- |
chiude un descrittore
(m) di file di input |
| |
<&- |
chiude stdin |
| |
m>&- |
chiude un descrittore
(m) di file di output |
| |
>&- |
chiude stdout |
PIPING
Per incanalare (pipe) l'output di un programma nell'input di un altro programma
si usa la forma:
comando1|comando2
Questo comando assegna l'output del primo comando all'input del secondo comando.
Nella
shell csh la pipe con file particolari è così definita:
| |&
comando |
crea una pipe tra
stdout-stderr e il comando |
Nella
bourne shell sh la pipe con file particolari è così definita:
| 2>&1|
comando |
crea una pipe tra stdout-stderr e il
comando |
Esempio
[studente@localhost /]$ find /etc/httpd | wc
find: /etc/httpd/conf/ssl.crl: Permission denied
find: /etc/httpd/conf/ssl.crt: Permission denied
find: /etc/httpd/conf/ssl.csr: Permission denied
find: /etc/httpd/conf/ssl.key: Permission denied
find: /etc/httpd/conf/ssl.prm: Permission denied
14 14 309
[studente@localhost /]$ find /etc/httpd 2>&1| wc
19 34 554 |
SIMBOLI SPECIALI
Oltre
ai simboli di ridirezione dei file ci sono altri simboli speciali che si possono
usare su linea di comando. Alcuni di questi sono
| |
; |
separatore di comandi |
| |
& |
esegue un comando in background |
| |
&& |
esegue il comando seguente (a questo simbolo) solamente se il
comando precedente (a questo simbolo) è stato completato con successo,
esempio:
grep
stringa
file && cat
file |
| |
|| |
esegue il comando seguente (a questo simbolo) solamente se il
comando precedente (a questo simbolo) non è stato completato con
successo, esempio:
grep
stringa file || echo "Stringa non trovata." |
| |
( ) |
i comandi tra parentesi sono eseguiti in una sotto-shell. L'output
della sotto-shell può essere manipolato come specificato nelle
precedenti sezioni. |
| |
' ' |
segni di quoting letterali. All'interno di questi segni di quoting
non viene permesso ad alcuni caratteri di assumere significati speciali. |
| |
\ |
considera il prossimo carattere letteralmente (escape)
- permette anche di impostare un comando su più linee |
| |
" " |
segni di quoting regolari. All'interno di questi segni di quoting
sono permesse sostituzioni di variabili e di comando (non disattivano $
e \ all'interno della stringa). |
| |
`comando` |
prende l'output del comando e lo sostituisce nell'argomento su linea
di comando (il simbolo `
può essere inserito tenendo premuto il tasto ALT e premendo poi in
successione 0096)
[studente@localhost /]$ ls `echo
$HOME`
caio pippo typescript users users2 users.lnk |
| |
# |
ogni cosa che lo segue fino a un newline è un commento |
LA MANIPOLAZIONE DEL
TESTO
Alcuni programmi di manipolazione del testo come grep, egrep, sed,
awk e vi
consentono di ricercare uno schema (pattern) piuttosto che una stringa fissa.
Questi schemi testuali sono conosciuti come espressioni regolari. Si può formare
un'espressione regolare combinando caratteri normali con caratteri speciali,
anche conosciuti come meta-caratteri, secondo le successive regole.
SIMBOLI SPECIALI O METACARATTERI
Usati nei nomi di file questi meta-caratteri
assumono diversi significati. Ecco degli esempi:
| |
? |
indica un singolo
carattere alla posizione indicata |
| |
* |
indica una stringa di zero
o più caratteri |
| |
[abc...] |
indica un carattere tra
quelli racchiusi |
| |
[a-e] |
indica un carattere tra
quelli nel range a, b, c, d, e |
| |
[!def] |
indica un carattere tra
quelli non inclusi in parentesi, solamente
sh |
| |
~ |
indica la directory home
dell'utente corrente, solamente
csh |
| |
~user |
csh |
E sui simboli speciali che si basano le espressioni regolari.
Si presentano in tre
diverse forme:
Ancoraggi : legano lo schema a una posizione sulla linea
Serie di caratteri : indicano un carattere in una singola posizione
Modificatori : specificano quante volte ripetere l'espressione precedente
Alcuni esempi di espressioni regolari comuni sono
GREP
Questa sezione fornisce un'introduzione all'uso delle espressioni regolari con
grep.
L'utility grep viene usata per ricercare espressioni regolari comuni che
si presentano nei file Unix. Le espressioni regolari, come quelle viste in
precedenza, sono meglio specificate all'interno di apostrofi (o caratteri di
quoting singoli) quando usate con l'utility grep. L'utility egrep
fornisce una capacità di ricerca attraverso un set esteso di meta-caratteri. La
sintassi dell'utility grep, alcune delle possibili opzioni e alcuni
semplici esempi sono mostrati di seguito.
Sintassi
grep [opzioni]
expreg [file]
Opzioni generali
-i ignora la differenza tra caratteri maiuscoli e minuscoli
-c riporta solamente la somma del numero di linee contenenti le corrispondenze,
non le corrispondenze stesse
-v inverte la ricerca, visualizzando solo le linee senza corrispondenza
-n mostra un numero di linea insieme alla linea su cui è stata trovata una
corrispondenza
-s lavora in silenzio, riportando solo lo stato finale:
0, per corrispondenze trovate
1, per nessuna corrispondenza
2, per errori
-l elenca i nomi dei file, ma non le linee, nei quali sono state trovate
corrispondenze
COMANDI REMOTI
rlogin è un
servizio di login remoto che è stato in passato un'esclusiva dello Unix BSD 4.3
di Berkeley. Essenzialmente, offre le stesse funzionalità di telnet,
eccetto che rlogin lascia passare al computer remoto le informazioni
dell'ambiente di login dell'utente. Le macchine possono essere configurate per
permettere connessioni da fidati host senza richiedere la password dell'utente.
Una versione più sicura di questo protocollo è la Sicura SHell SSH,
software scritto da Tatu Ylonen.
Il comando finger
mostra il file .plan di un utente specifico o riporta chi è attualmente
“loggato” su una specifica macchina. L'utente deve permettere i permessi di
lettura generale sul file .plan.
Sintassi
finger [opzioni] [user[@nomehost]]
esempio
[root@localhost
studente]#
finger
Login Name Tty
Idle Login Time Office Office Phone
studente studente pts/2 2:19 Mar 4 04:59 (192.168.1.23)
studente studente pts/0 Mar 4 07:00
(192.168.1.23)
[root@localhost studente]#
finger studente
Login: studente Name: studente
Directory: /home/studente Shell: /bin/bash
On since Wed Mar 4 04:59 (CET) on pts/2 from 192.168.1.23
2 hours 26 minutes idle
On since Wed Mar 4 07:00 (CET) on pts/0 from 192.168.1.23
No mail.
No Plan. |
Il comando rsh fornisce la possibilità di
invocare una shell Unix su un host remoto della rete locale con lo scopo di
eseguirci comandi di shell. Questa capacità è simile alla funzione shell escape
disponibile generalmente all'interno di un software di sistema Unix come editor
ed email.
Il comando rcp fornisce la possibilità di copiare file dall'host locale ad un
host remoto della rete locale.
rsh [-l username] host_remoto [comando]
rcp [[user1]@host1:]file_sorgente [[user2]@host2:]file_destinazione
LE VARIABILI
D'AMBIENTE E LOCALI
Le variabili di ambiente sono
usate per fornire informazioni e supporto ai programmi che si utilizzano.
Si possono avere sia variabili globali di ambiente sia variabili
locali di shell. Le variabili globali di ambiente sono
inizializzate attraverso la propria shell di login e i nuovi
programmi e le nuove shell ereditano l'ambiente della shell
genitore. Le variabili locali di shell sono usate solamente
dalla shell corrente e non sono passate ad altri processi. Un
processo figlio non può passare una variabile al suo processo
padre.
Le variabili di ambiente correnti sono visualizzabili con i
comandi env, declare -x oppure printenv.
Ecco alcune variabili comuni:
| |
DISPLAY |
Il display grafico da usare,
esempio nyssa:0.0 |
| |
EDITOR |
Il path (percorso) del proprio
editor di default, esempio
/usr/bin/vi |
| |
GROUP |
Il proprio gruppo di login, esempio
staff |
| |
HOME |
Il path della propria home
directory, esempio
/home/frank |
| |
HOSTNAME |
Il nome host del proprio sistema |
| |
IFS |
I separatori di campo interni,
generalmente alcuni spazi bianchi (tab, spazio e
new-line di default) |
| |
LOGNAME |
Il nome del proprio login, esempio
frank |
| |
PATH |
I path per ricercare i comandi,
esempio /usr/bin:/usr/ucb:/usr/local/bin |
| |
PS1 |
La stringa del prompt primario,
solamente shell Bourne ($
di default) |
| |
PS2 |
La stringa del prompt secondario,
solamente shell Bourne (> di default) |
| |
SHELL |
La propria shell di login, esempio
/usr/bin/csh |
| |
TERM |
Il proprio tipo di terminale,
esempio xterm |
| |
USER |
Il proprio username, esempio
frank |
[root@localhost
studente]# env
PWD=/home/studente
REMOTEHOST=192.168.1.23
HOSTNAME=localhost.localdomain
LESSOPEN=|/usr/bin/lesspipe.sh %s
KDEDIR=/usr
USER=studente
LS_COLORS=
MACHTYPE=i386-redhat-linux-gnu
MAIL=/var/spool/mail/studente
INPUTRC=/etc/inputrc
LANG=it_IT@euro
LOGNAME=studente
SHLVL=2
SHELL=/bin/bash
HOSTTYPE=i386
OSTYPE=linux-gnu
HISTSIZE=1000
TERM=ansi
HOME=/root
PATH=/usr/local/bin:/bin:/usr/bin:/usr/X11R6/bin:/home/studente/bin
_=/usr/bin/env
[studente@localhost
studente]$
declare -x
declare -x HISTSIZE="1000"
declare -x HOME="/home/studente"
declare -x HOSTNAME="localhost.localdomain"
declare -x HOSTTYPE="i386"
declare -x INPUTRC="/etc/inputrc"
declare -x KDEDIR="/usr"
declare -x LANG="it_IT@euro"
declare -x LESSOPEN="|/usr/bin/lesspipe.sh %s"
declare -x LOGNAME="studente"
declare -x LS_COLORS=""
declare -x MACHTYPE="i386-redhat-linux-gnu"
declare -x MAIL="/var/spool/mail/studente"
declare -x OSTYPE="linux-gnu"
declare -x PATH="/usr/local/bin:/bin:/usr/bin:/usr/X11R6/bin:/home/studente/bin"
declare -x PWD="/home/studente"
declare -x REMOTEHOST="192.168.1.23"
declare -x SHELL="/bin/bash"
declare -x SHLVL="1"
declare -x TERM="ansi"
declare -x USER="studente" |
Molte variabili di ambiente sono
inizializzate automaticamente quando si effettua il login.
Queste possono essere modificate e si possono definire altre
variabili nei file di inizializzazione o in qualunque
momento all'interno della shell stessa. La variabile PATH specifica le directory nelle quali saranno automaticamente
cercati i comandi richiesti. Alcuni esempi sono nello script di
inizializzazione di shell spiegato più avanti.
Per visualizzare le variabili
locali si utilizza il comando set oppure declare
[studente@localhost
studente]$ set
BASH=/bin/bash
BASH_VERSINFO=([0]="2" [1]="05" [2]="8" [3]="1" [4]="release"
[5]="i386-redhat-linux-gnu")
BASH_VERSION=$'2.05.8-release'
COLORS=/etc/DIR_COLORS
COLUMNS=80
DIRSTACK=()
EUID=500
GROUPS=()
HISTFILE=/home/studente/.bash_history
HISTFILESIZE=1000
HISTSIZE=1000
HOME=/home/studente
HOSTNAME=localhost.localdomain
HOSTTYPE=i386
IFS=$' \t\n'
INPUTRC=/etc/inputrc
KDEDIR=/usr
LANG=it_IT@euro
LESSOPEN=$'|/usr/bin/lesspipe.sh %s'
LINES=60
LOGNAME=studente
LS_COLORS=
MACHTYPE=i386-redhat-linux-gnu
MAIL=/var/spool/mail/studente
MAILCHECK=60
OPTERR=1
OPTIND=1
OSTYPE=linux-gnu
PATH=/usr/local/bin:/bin:/usr/bin:/usr/X11R6/bin:/home/studente/bin
PIPESTATUS=([0]="0")
PPID=5562
PS1=$'[\\u@\\h \\W]\\$ '
PS2=$'> '
PS4=$'+ '
PWD=/home/studente
REMOTEHOST=192.168.1.23
SHELL=/bin/bash
SHELLOPTS=braceexpand:hashall:histexpand:monitor:history:interactive-comments:emacs
SHLVL=1
SUPPORTED=it_IT@euro:it_IT:it
TERM=ansi
UID=500
USER=studente
_=clear
langfile=/home/studente/.i18n
sourced=1 |
Per inizializzare una variabile
locale possiamo usare il comando declare. Per
visualizzare il valore di una singola variabile si può
utilizzare il comando
echo seguito dal nome della variabile
preceduta dal carattere $
esempio:
[studente@localhost
studente]$
declare
cognome="sechi"
[studente@localhost studente]$
echo $cognome
sechi |
La shell sh usa il file di inizializzazione
.profile posto
nella home directory dell'utente (la shell bash usa .bash_profile). Inoltre può esserci un file di
inizializzazione globale del sistema, esempio /etc/profile
(eseguito durante le operazioni di bootstrap). Quindi il file globale del sistema sarà eseguito prima di
quello locale.
Un semplice file .profile potrebbe essere il seguente:
PATH=/usr/bin:/usr/ucb:/usr/local/bin:.
# setta il PATH
export PATH
# rende disponibile PATH
# per le sotto-shell
PS1="{`hostname` `whoami`} "
# setta il prompt,
# $ di default
# definizioni di funzioni
ls() { /bin/ls -sbF "$@";}
ll() { ls -al "$@";}
# setta il tipo di terminale
stty erase ^H
# setta Control-H come
tasto
# di cancellazione
umask 077 |
Ogni volta che si incontra il
simbolo #, il resto di quella linea viene trattato come un
commento. Nella variabile PATH ogni directory è separata da due
punti (:) mentre il punto finale specifica che la directory corrente è
nel proprio path. Se il punto non è nel proprio path,
per eseguire un programma nella directory corrente occorre
indicare ./ prima del comando:
./programma
Non è una buona idea avere il
punto (.) nel proprio PATH, poiché è possibile che si esegua
inavvertitamente un programma senza averne l'intenzione.
Una variabile settata in .profile rimane valida solo nel
contesto della shell di login, a meno che la si esporti con
export o si esegua .profile in un'altra shell.
Nell'esempio precedente la variabile PATH viene esportato per le sotto-shell.
Si possono creare anche delle proprie funzioni. Nell'esempio precedente la
funzione
ll, (che corrisponde a ls -al) lavora su un specifico file o
directory.
Con stty il carattere di cancellazione viene settato a
Control+H, che corrisponde al tasto di Backspace.
L'ultima linea nell'esempio
richiama il comando umask, facendo in modo che i file e
le directory create non abbiano i permessi di
lettura-scrittura-esecuzione per l'utenza gruppo e altri.
Per altre informazioni su sh, digitare man sh al
prompt di shell.
La shell C, csh, usa invece come file di inizializzazione .cshrc e
.login. Un esempio è il seguente
|
set path=(/usr/bin
/usr/ucb /usr/local/bin ~/bin . ) # setta il path
set prompt = "{`hostname` `whoami` !}"
# setta il promt primario ;
# % di default
set noclobber
# non ridirige l'output
# su file esistenti
set ignoreeof
# ignora EOF (Ctrl+D) in
# questa shell
set history=100 savehist=50
# mantiene una lista history
# di comandi e la memorizza
# tra vari (50) login
# -----------------------------------------------------
# alias
#
-----------------------------------------------------
alias h history
# alias h per history
alias ls "/usr/bin/ls -sbF"
# alias ls per ls -sbF
alias ll ls -al
# alias ll per ls -sbFal
# (combina queste opzioni
# con quelle di ls sopra citate)
alias cd 'cd \!*;pwd'
# alias cd per stampare la
# directory di lavoro corrente
# dopo aver cambiato directory
umask 077 |
Un alias permette di usare uno specifico nome alias
al posto del comando completo. Nell'esempio precedente, il
risultato di digitare ls sarà quello di eseguire
/usr/bin/ls
-sbF.
Se si effettuano cambiamenti al proprio file di
inizializzazione, questi possono essere attivati eseguendo il
file modificato. Per la shell csh questo è possibile
anche attraverso
il comando built-in source, esempio:
source .cshrc
Ecco ora un esempio sulla visibilità delle
variabili
[studente@localhost studente]$ ps -f
UID PID PPID C STIME TTY TIME CMD
studente 7444 7443 0 Nov23 pts/0 00:00:00 -bash
studente 8648 7444 0 12:22 pts/0 00:00:00 ps -f
[studente@localhost studente]$ declare cognome="sechi"
[studente@localhost studente]$ echo $cognome
sechi
[studente@localhost studente]$ bash
[studente@localhost studente]$ ps -f
UID PID PPID C STIME TTY TIME CMD
studente 7444 7443 0 Nov23 pts/0 00:00:00 -bash
studente 8649 7444 0 12:23 pts/0 00:00:00 bash
studente 8674 8649 0 12:24 pts/0 00:00:00 ps -f
[studente@localhost studente]$ echo $cognome
[studente@localhost studente]$ exit
exit
[studente@localhost studente]$ export cognome
[studente@localhost studente]$ bash
[studente@localhost studente]$ echo $cognome
sechi |
COMANDI EQUIVALENTI IN
DOS E UNIX
Ecco un elenco di
alcuni comandi equivalenti in ambito UNIX/DOS
| Funzione del Comando |
MS-DOS |
Linux |
Esempi base di Linux |
| Copiare un file |
copy |
cp |
cp questofile.txt /home/questadirectory |
| Spostare file |
move |
mv |
mv thisfile.txt /home/questadirectory |
| Elencare file |
dir |
ls |
ls |
| Cancellare una schermata |
cls |
clear |
clear |
| Chiudere una shell |
exit |
exit |
exit |
| Visualizzare o impostare la
data |
date |
date |
date |
| Cancellare file |
del |
rm |
rm questofile.txt |
| Copiare l'output sullo schermo |
echo |
echo |
echo questo
messaggio |
| Modificare un file con un
editor di testi semplice |
edit |
vi |
vi questofile.txt |
| Paragonare il contenuto dei
file |
fc |
diff |
diff file1 file2 |
| Trovare una stringa di testo
in un file |
find |
grep |
grep questa
parola o frase questofile.txt |
| Formattare un dischetto |
format a: (se
il dischetto è in A:) |
mke2fs o mformat |
/sbin/mke2fs
/dev/fd0 (/dev/fd0 è
l'equivalente Linux di A:) |
| Visualizzare l'help di un
comando |
comando /?
help |
man |
man comando |
| Creare una directory |
mkdir |
mkdir |
mkdir directory |
| Visualizzare un file |
more |
less |
less questofile.txt |
| Rinominare un file |
ren |
mv |
mv questofile.txt quelfile.txt |
| Visualizzare la propria
posizione nel filesystem |
chdir |
pwd |
pwd |
| Cambiare directory con un
percorso specifico (absolute path) |
cd nomedelpath |
cd nomedelpath |
cd /directory/directory |
| Cambiare directory con un percorso
relativo |
cd .. |
cd .. |
cd .. |
| Visualizzare l'ora |
time |
date |
date |
| Mostrare la quantità di RAM
utilizzata |
mem |
free |
free |