MINI CORSO DI MICROSOFT ACCESS - parte 6°
|
|
MINI CORSO DI MICROSOFT ACCESS - parte 6° |
|
Con il linguaggio SQL è possibile creare la struttura del nostro database ovvero le tabelle. I comandi di creazione sono fortemente legati alle caratteristiche e alle funzionalità offerte dal DB utilizzato. Le query di definizione, costruite per un certo ambiente, generalmente non risultano "portabili" ovvero non sono comprensibili da altri DB se non con l'apporto di opportune modifiche.
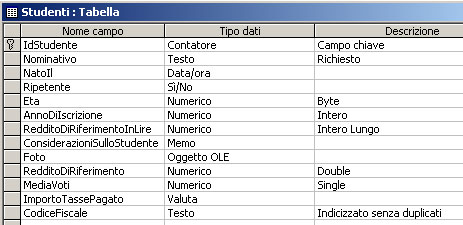
Esempio: la creazione della classica tabella studenti in SQL potrebbe essere ottenuta con questo comando:
CREATE TABLE Studenti
(
IdStudente COUNTER CONSTRAINT IdStudente PRIMARY KEY,
Nominativo TEXT(60) CONSTRAINT Nominativo NOT NULL,
NatoIl DATETIME,
Ripetente BIT,
Eta BYTE,
AnnoDiIscrizione SMALLINT,
RedditoDiRiferimentoInLire LONG,
ConsiderazioniSulloStudente LONGTEXT,
Foto LONGBINARY,
RedditoDiRiferimento DOUBLE,
MediaVoti SINGLE,
ImportoTassePagato CURRENCY,
CodiceFiscale TEXT(16) CONSTRAINT CodiceFiscale Unique
)
che genera la seguente struttura
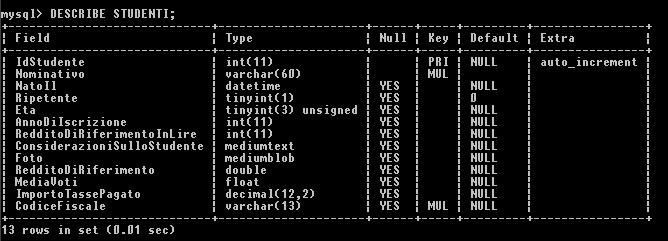
In MySQL il comando per generare la stessa tabella è:
CREATE TABLE Studenti
(
IdStudente INT
Auto_increment PRIMARY KEY,
Nominativo VARCHAR(60)
NOT NULL,
NatoIl DATETIME,
Ripetente BIT DEFAULT
0,
Eta TINYINT UNSIGNED,
AnnoDiIscrizione INT,
RedditoDiRiferimentoInLire INT,
ConsiderazioniSulloStudente MEDIUMTEXT,
Foto MEDIUMBLOB,
RedditoDiRiferimento DOUBLE,
MediaVoti FLOAT,
ImportoTassePagato DECIMAL(12,2),
CodiceFiscale CHAR(16)
UNIQUE,
FULLTEXT (Nominativo,
ConsiderazioniSulloStudente)
) ENGINE=MyISAM;
la sua esecuzione
determina la creazione di questa tabella
In MS SQL Server il comando per generare la stessa tabella è
CREATE TABLE Studenti
(
IdStudente INT IDENTITY (1, 1) NOT NULL PRIMARY KEY,
Nominativo CHAR(60) CONSTRAINT Nominativo NOT NULL,
NatoIl DATETIME,
Ripetente BIT,
Eta TINYINT,
AnnoDiIscrizione SMALLINT,
RedditoDiRiferimentoInLire INT,
ConsiderazioniSulloStudente TEXT,
Foto IMAGE,
RedditoDiRiferimento FLOAT,
MediaVoti REAL,
ImportoTassePagato MONEY,
CodiceFiscale CHAR(16) CONSTRAINT CodiceFiscale Unique
)
la sua esecuzione
determina la creazione di questa tabella
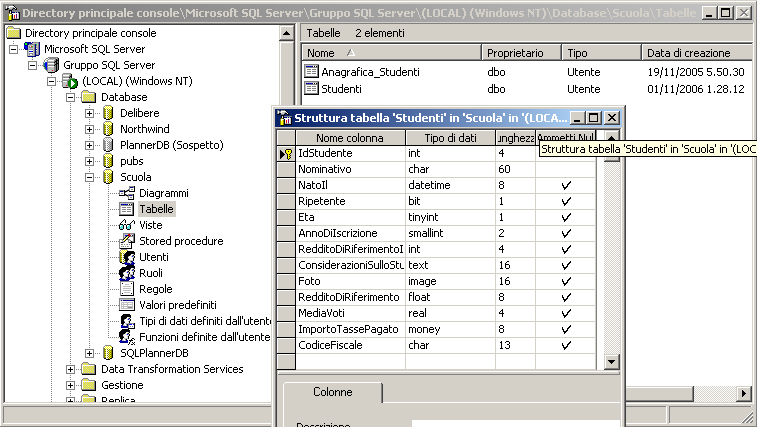
In ORACLE il comando per generare la stessa tabella è
-- ORACLE non supporta
il tipo AUTOINCREMENT se non
-- utilizzando meccanismi legati ai trigger
DROP TABLE Studente;
CREATE TABLE Studente
(
IdStudente ROWID CONSTRAINT IdStudente PRIMARY KEY,
Nominativo VARCHAR2(60) NOT NULL,
NatoIl DATE,
Ripetente NUMBER(1,0) CONSTRAINT BooleanValue CHECK (Ripetente IN
(1, 0, NULL)),
Eta NUMBER(3,0),
AnnoDiIscrizione NUMBER(5,0),
RedditoDiRiferimentoInLire NUMBER(11,0),
ConsiderazioniSulloStudente CLOB,
Foto BLOB,
RedditoDiRiferimento FLOAT(126),
MediaVoti FLOAT(126),
ImportoTassePagato NUMBER(15,4),
CodiceFiscale VARCHAR2(16) CONSTRAINT CodiceFiscale Unique
);
In generale la sintassi (semplificata!) di una query di creazione è la seguente:
CREATE TABLE NOMETABELLA
(
NomeCampo1 Tipo1[(dimensione1)] Vincoli1,
NomeCampo2 Tipo2[(dimensione2)] Vincoli2,
...
NomeCampoN TipoN[(dimensioneN)] VincoliN
)
dove il
TipoI
assume uno di questi valori
| Tipo SQL | Tipo in ACCESS | Sinonimi SQL |
| COUNTER | Contatore | Autoincrement |
| TEXT(n) | Testo con n caratteri | VarChar |
| LONGTEXT | Memo | |
| DATETIME | Data/ora | Timestamp |
| BIT | Boolean | Boolean, Logical |
| BYTE | Intero Byte | |
| SMALLINT | Intero | |
| LONG | Intero lungo | Integer |
| SINGLE | Precisione singola | Real |
| DOUBLE | Precisione doppia | Number |
| CURRENCY | Valuta | Money |
| LONGBINARY | Oggetto OLE |
Come indicato nella tabella alcuni dei tipi elencati presentano dei sinonimi: ad esempio al posto di DATETIME posso usare TIMESTAMP. Per quanto riguarda l'elenco dei sinonimi la tabella fornita non è esaustiva.
I VincoliI sono invece clausole inerenti all'indicizzazione. La tabella sottostante propone alcuni esempi
| istruzione di constraint SQL | Tipo di vincolo |
| NOMECAMPO TIPO CONSTRAINT Nome PRIMARY KEY | Definisce il campo "NOMECAMPO" come campo chiave |
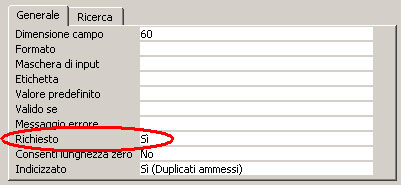
| NOMECAMPO TIPO CONSTRAINT Nome NOT NULL | Impone il campo "NOMECAMPO"
obbligatorio. Equivale a porre a "Si" la proprietà del campo qui sotto
evidenziata
|
| NOMECAMPO TIPO CONSTRAINT Nome Unique | Mette nel campo "NOMECAMPO" un indice senza duplicati |
La
definizione degli indici con SQL è realizzata mediante il comando
CREATE INDEX.
Esempio 1°: per creare un indice con duplicati sul campo
NOMINATIVO
che impedisca la sua non compilazione utilizzo il seguente
comando SQL
CREATE INDEX
NominativoIDX
ON Studenti (Nominativo)
WITH DISALLOW NULL
Esempio 2°: per indicizzare con duplicati il campo NATOIL permettendo che possa essere lasciato vuoto (i record con NATOIL a NULL non verranno inclusi nell'indice) eseguo questo SQL:
CREATE INDEX NatoIlIDX
ON Studenti (NatoIl)
WITH IGNORE NULL
L'esecuzione dei due comandi appena visti determinerà, in Microsoft Access, la creazione dei due indici evidenziati nella figura qui sotto:
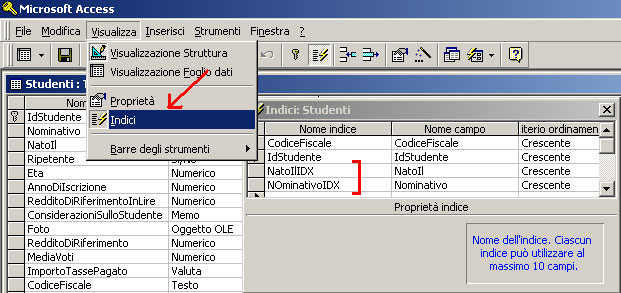
In MySQL la creazione di due indici equivalenti all'esempio 1° e 2° può essere realizzata mediante questi due comandi SQL:
DROP INDEX NominativoIDX
ON Studenti;
CREATE INDEX NominativoIDX ON Studenti(Nominativo);
DROP INDEX NatoIlIDX ON
Studenti;
CREATE INDEX NatoIlIDX ON Studenti(NatoIl);
In generale la sintassi (semplificata!) del comando CREATE INDEX è la seguente:
CREATE [UNIQUE] INDEX NOMEINDICE
ON NOMETABELLA(NOMECAMPO)
[WITH { PRIMARY | DISALLOW NULL | IGNORE NULL }]
dove le parole evidenziate hanno questo significato:
| Parola riservata | Tipo di indice |
| UNIQUE | Indice senza duplicati |
| WITH PRIMARY | definisce un campo chiave - posso omettere la parola riservata UNIQUE - E' equivalente a: CONSTRAINT Nome PRIMARY KEY |
| WITH DISALLOW NULL | Impedisce valori NULL nel campo indicizzato |
| WITH IGNORE NULL | Esclude dall'indicizzazione i valori NULL |
Si osservi che le parole messe tra parentesi quadre sono dei parametri facoltativi mentre quelle tra parentesi graffe, separate dalla pipe |, rappresentano delle istruzioni tra loro alternative.
L'SQL consente anche di modificare la struttura del database. Il comando che realizza questo scopo è ALTER TABLE la cui sintassi (semplificata!) è:
ALTER TABLE Nometabella
{
ADD COLUMN NomeCampoNuovo Tipo[(dimensione)] Vincolo |
ALTER COLUMN NomeCampo TipoNuovo[(dimensione)] NuovoVincolo |
DROP COLUMN NomeCampo
}
Esempio 1°: per inserire il campo nuovo classe devo eseguire questo comando SQL:
ALTER TABLE Studenti ADD COLUMN Classe TEXT(3);
Esempio 2°: per eliminare dalla tabella studenti il campo relativo al reddito in lire eseguo questo comando SQL:
ALTER TABLE Studenti DROP COLUMN RedditoDiRiferimentoInLire
Esempio 3°: per modificare le dimensioni del campo relativo alla classe eseguo questo comando SQL (non è supportato da access 97)
ALTER TABLE Studenti ALTER COLUMN Classe TEXT(5)
In MySQL i comandi equivalenti potrebbero essere:
ALTER TABLE Studenti ADD COLUMN Classe VARCHAR(3) FIRST;
ALTER TABLE Studenti MODIFY COLUMN Classe VARCHAR(5) AFTER NOMINATIVO;
ALTER TABLE Studenti DROP COLUMN RedditoDiRiferimentoInLire;
Addirittura con MySQL è possibile rinominare
i campi e la tabella stessa
ALTER TABLE Studenti CHANGE COLUMN Classe Sezione VARCHAR(6);
ALTER TABLE Studenti ALTER Sezione SET DEFAULT '4N';
ALTER TABLE Studenti RENAME TO Alunni;
L'esecuzione di tutti questi comandi produce il risultato finale evidenziato in figura:
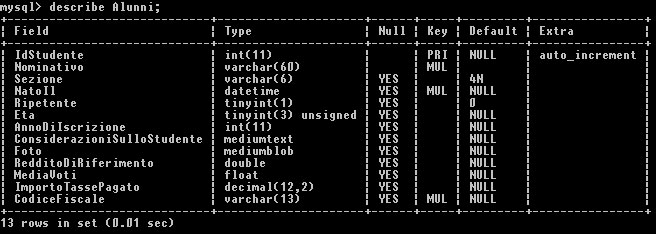
Una tabella può essere eliminata con tutti i suoi dati utilizzando il comando DROP TABLE
DROP TABLE Studenti
Anche un indice può essere eliminato. Si usa il comando DROP INDEX
La sintassi è:
DROP INDEX NomeIndice ON Nometabella
Esempio:
DROP INDEX NominativoIDX ON Studenti;
La parola chiave
CONSTRAINT è utilizzata anche per definire le relazioni 1-->1, 1-->N.
Esempio: Supponiamo di dover
gestire i dati riservati degli studenti di una scuola e le loro assenze.
I comandi SQL che consentono di creare le tabelle minimali necessarie ai nostri
scopi potrebbero essere i seguenti:
CREATE TABLE Studenti
(
IdStudente COUNTER CONSTRAINT IdStudente PRIMARY KEY,
Nominativo TEXT(60) CONSTRAINT Nominativo NOT NULL,
Classe TEXT(3)
)
CREATE TABLE StudentiRiservato
(
IdStudente LONG CONSTRAINT IdStudente PRIMARY KEY,
NoteRiservateSulloStudente LONGTEXT,
RedditoDiRiferimento DOUBLE
)
CREATE TABLE Assenze
(
IdAssenza COUNTER CONSTRAINT IdAssenza PRIMARY KEY,
idStudente LONG CONSTRAINT IdStudente NOT NULL,
AssenzaDel DATETIME
)
Per realizzare la relazione 1-->N che lega la tabella
Studenti
alla tabella Assenze
utilizzo questo SQL:
ALTER TABLE Assenze
ADD CONSTRAINT StudentiAssenze1aN
FOREIGN KEY (IdStudente)
REFERENCES Studenti (IDStudente);
Per realizzare la relazione 1-->1 che lega la tabella Studenti alla tabella StudentiRiservato uso un comando del tutto analogo:
ALTER TABLE
StudentiRiservato
ADD CONSTRAINT StudentiStudentiRis1a1
FOREIGN KEY (IdStudente)
REFERENCES Studenti (IDStudente);
In MySQL i comandi equivalenti potrebbero essere (ps: il simbolo ` ha codice ascii 96):
ALTER TABLE Assenze DROP
FOREIGN KEY StudentiAssenze1aN;
ALTER TABLE StudentiRiservato DROP FOREIGN KEY StudentiStudentiRis1a1;
DROP TABLE IF EXISTS `Studenti`;
DROP TABLE IF EXISTS `StudentiRiservato`;
DROP TABLE IF EXISTS `Assenze`;
CREATE TABLE Studenti
(
IdStudente INT Auto_increment PRIMARY KEY,
Nominativo VARCHAR(60) NOT NULL,
Classe CHAR(3)
);
CREATE TABLE StudentiRiservato
(
IdStudente INT Auto_increment PRIMARY KEY,
NoteRiservateSulloStudente MEDIUMTEXT,
RedditoDiRiferimento DOUBLE
);
CREATE TABLE Assenze
(
IdAssenza INT Auto_increment PRIMARY KEY,
idStudente INT NOT NULL,
AssenzaDel DATETIME
);
ALTER TABLE Assenze ADD CONSTRAINT StudentiAssenze1aN
FOREIGN KEY (IdStudente) REFERENCES Studenti (IDStudente);
ALTER TABLE StudentiRiservato ADD CONSTRAINT StudentiStudentiRis1a1
FOREIGN KEY (IdStudente) REFERENCES Studenti (IDStudente);
In generale la sintassi (semplificata!) per indicare una relazione tra due tabelle è:
ALTER TABLE NometabellaSlave
ADD CONSTRAINT NomeIndice
FOREIGN KEY
(CampoSlaveCollegato)
REFERENCES
NomeTabellaMaster(NomeCampoChiaveMaster)
I comandi SQL di selezione o di raggruppamento mostrano il loro risultato a video. In alternativa è possibile registrare le righe di una query all'interno del nostro database.
Per eseguire i comandi MySQL elencati negli esempi successivi occorre eseguire queste operazioni preliminari:
DROP TABLE Vocabolario;
CREATE TABLE Vocabolario
(
Italiana VARCHAR(255) NOT NULL,
Spagnolo VARCHAR(255),
Tedesco VARCHAR(255),
Inglese VARCHAR(255),
Francese VARCHAR(255),
Olandese VARCHAR(255)
) Engine=MyISAM;
LOAD DATA INFILE 'c:\\vocabolario.txt'
IGNORE
INTO TABLE Vocabolario
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
(Italiana, Spagnolo, Tedesco, Inglese, Francese, Olandese );
Il risultato di una query può essere salvato all'interno di una nuova tabella utilizzando la parola riservata INTO. La sintassi generica è identica a quella delle query di selezione con l'aggiunta della sola clausola INTO:
SELECT {campo1, campo2, ... | * }
INTO NUOVATABELLA [IN NOMEDBESTERNO.MDB]
FROM Tabella1 [, Tabella2 ...]
WHERE Condizioni
GROUP BY Elenco campi da raggruppare
ORDER BY Elenco campi da ordinare
Esempio: Partendo dalla tabella vocabolario, usata nell'esercitazione, possiamo creare una nuova tabella contenente tutte i caratteri dell'Alfabeto. La query che realizza il nostro scopo è:
SELECT UCASE(Left(Italiana,1))
AS Lettera
INTO Alfabeto
FROM Vocabolario
WHERE
( Asc(UCase(Left(Italiana,1)))<=Asc('Z') And
Asc(UCase(Left(Italiana,1)))>=Asc('A') )
GROUP BY UCASE(Left(Italiana,1))
ORDER BY UCASE(Left(Italiana,1))
In MySQL il comando equivalente è:
DROP TABLE Alfabeto;
CREATE TABLE Alfabeto
SELECT UCASE(SUBSTRING(Italiana,1,1)) AS Lettera FROM Vocabolario
WHERE ( Ascii(UCase(SUBSTRING(Italiana,1,1)))<=Ascii('Z') And
Ascii(UCase(SUBSTRING(Italiana,1,1)))>=Ascii('A')
)
GROUP BY UCASE(SUBSTRING(Italiana,1,1))
ORDER BY UCASE(SUBSTRING(Italiana,1,1));
Il risultato di una query può essere anche accodato ad una tabella preesistente. I dati inseriti devono risultare compatibili sia con il tipo dei campi che vengono alimentati sia con i vincoli fissati dagli indici definiti sulla tabella di destinazione. In caso contrario, durante l'esecuzione della query di accodamento, viene visualizzato il seguente avviso:
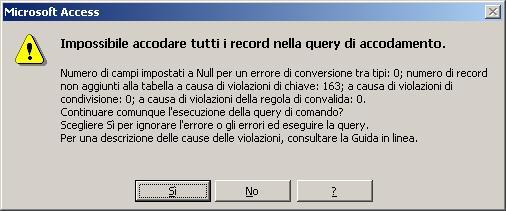
La generica
sintassi è:
INSERT INTO TabellaDestinazione
{( TabellaDestinazione.Campo1,
TabellaDestinazione.Campo2,
...
) | *
}
SELECT {campo1, campo2, ... | * }
FROM Tabella1 [, Tabella2 ...]
WHERE Condizioni
GROUP BY Elenco campi da raggruppare
ORDER BY Elenco campi da ordinare
Esempio: per aggiungere nella tabella [ITA-UK] i valori dei campi Inglese e Italiana presi dalla tabella Vocabolario devo scrivere:
INSERT INTO [ITA-UK] (
Italiana, Inglese )
SELECT Italiana, Inglese
FROM Vocabolario;
La tabella
[ITA-UK]
può essere creata con questo
comando SQL:
CREATE
TABLE [ITA-UK] (Italiana TEXT(255), Inglese TEXT(255))
In MySQL il comando equivalente è:
CREATE TABLE `ITA-UK` (Italiana VARCHAR(255), Inglese VARCHAR(255));
INSERT INTO `ITA-UK` (
Italiana, Inglese )
SELECT Italiana, Inglese FROM Vocabolario;
Si noti che per poter utilizzare nei nomi delle tabelle (o dei campi) dei caratteri speciali (esempio il meno) devo racchiuderli con il carattere ` (ascii 96). Il carattere` equivale in MySQL alle parentesi quadre [] di Access.
La clausola INSERT INTO è utilizzata anche per aggiungere un singolo record ad una tabella. In questo caso nel comando vengono specificati il nome e il valore di ciascun campo del record da aggiornare. È necessario specificare tutti i campi del record a cui si intende assegnare un valore e deve essere specificato un valore per ognuno di questi campi. Quando non vengono specificati tutti i campi della tabella, per le colonne mancanti viene inserito il valore predefinito o il valore NULL. I record vengono aggiunti alla fine della tabella. La sintassi della query di accodamento a record singolo è:
INSERT INTO TabellaDestinazione
(Campo1, Campo2, ...)
VALUES (valore1, Valore2, ...)
Esempio: per inserire nella tabella [ITA-UK] un nuovo record contenete le parole "casa" e "home" uso questo comando SQL
INSERT INTO [ITA-UK]
(Italiana, Inglese)
VALUES ('Casa', 'home')
In MySQL il comando equivalente è identico:
INSERT INTO `ITA-UK` (
Italiana, Inglese )
VALUES ('Casa','home');
QUERY DI ELIMINAZIONE
La clausola WHERE è utilizzata anche per eliminare dei record contenuti in una tabella. I record eliminati sono quelli per i quali la clausola WHERE risulta vera. La sintassi generica è:
DELETE FROM NomeTabella
WHERE Condizioni
Esempio: La query seguente elimina dal vocabolario le parole che non iniziano per una lettera alfabetica
DELETE FROM [ITA-UK]
WHERE
( Asc(UCase(Left(Italiana,1)))>Asc('Z') OR
Asc(UCase(Left(Italiana,1)))<Asc('A') )
In MySQL il comando equivalente è:
DELETE FROM `ITA-UK`
WHERE
( Ascii(UCase(SUBSTRING(Italiana,1,1)))>Ascii('Z') Or
Ascii(UCase(SUBSTRING(Italiana,1,1)))<Ascii('A') )
La clausola WHERE è utilizzata anche per aggiornare dei record. La sintassi è:
UPDATE NomeTabella
SET Campo1=valore1 [, campo2=valore2, ...]
WHERE Condizioni
Senza clausola WHERE la query aggiornerà tutti i record della tabella.
Esempio: La query seguente elimina gli spazi iniziali e finali dai campi Italiana e Inglese:
UPDATE [ITA-UK] SET Italiana=Trim(Italiana), Inglese=Trim(Inglese)
In MySQL il comando equivalente è identico:
UPDATE `ITA-UK`SET
Italiana=Trim(Italiana), Inglese=Trim(Inglese);
QUERY DI UNIONE
E' possibile unire il risultato di più query di selezione in un'unica query mediante la parola chiave UNION. Tutte le query presenti nella UNION devono restituire lo stesso numero di campi; questi tuttavia, non devono essere delle stesse dimensioni o dello stesso tipo. In base all'impostazione predefinita, quando si utilizza l'operazione UNION non vengono restituiti record duplicati. Il predicato ALL assicura che vengano restituiti tutti i record (anche i duplicati). Le query con il predicato ALL sono più rapide poichè access non deve effettuare ricerche. L'uso dell'alias va fatto solo nella prima istruzione di SELECT poichè i successivi vengono ignorati. La proposizione ORDER BY utilizza i nomi dei campi assegnati nella prima istruzione di SELECT. La sintassi generica è:
{ TABLE NomeTabella1 | QueryDiSelezione1 }
UNION [ALL]
{ TABLE NomeTabella2 | QueryDiSelezione2 }
UNION [ALL]
...
UNION [ALL]
{ TABLE NomeTabellaN | QueryDiSelezioneN }
Esempio: per ottenere un elenco contenente tutte le parole Italiane ed inglesi eseguo questa query:
SELECT ITALIANA AS PAROLA FROM [ITA-UK] UNION ALL SELECT INGLESE FROM [ITA-UK] ORDER BY PAROLA
In MySQL il comando equivalente è:
SELECT ITALIANA AS
PAROLA FROM `ITA-UK` UNION ALL SELECT INGLESE FROM `ITA-UK` ORDER BY PAROLA;
Si tratta di un'istruzione SELECT nidificata all'interno di un'altra istruzione SELECT . Per creare una sottoquery, è possibile utilizzare una delle tre sintassi:
1) QueryPrincipale WHERE confronto [ANY o SOME | ALL] (SottoQuery)
Il predicato ANY o SOME (che sono sinonimi) estrae tutti i record della query principale che soddisfano il confronto con almeno uno dei record recuperati dalla SottoQuery. Il predicato ALL recupera solo quei record della query principale che soddisfano il confronto con tutti i record recuperati dalla SottoQuery.
Esempio 1°: Elenco delle parole che iniziano con un carattere alfabetico
SELECT ITALIANA FROM VOCABOLARIO WHERE LEFT(ITALIANA,1)= ANY (SELECT LETTERA FROM ALFABETO)
In MySQL il comando è identico ma è supportato solo dalla versione 4.1.
La query successiva (errata!) mi da un risultato privo di righe (non può essere l'iniziale di una parola uguale a tutte le lettere dell'alfabeto!):
SELECT ITALIANA FROM VOCABOLARIO WHERE LEFT(ITALIANA,1)= ALL (SELECT LETTERA FROM ALFABETO)
Esempio 2°: Elenco delle parole che non iniziano con un carattere alfabetico
SELECT ITALIANA FROM VOCABOLARIO WHERE LEFT(ITALIANA,1)<> ALL (SELECT LETTERA FROM ALFABETO)
In MySQL il comando è identico ma è supportato solo dalla versione 4.1.
2) QueryPrincipale WHERE espressione [NOT] IN (SottoQuery)
Il predicato [NOT] IN estrae tutti i record della query principale dove l'espressione [non] è tra i valori restituiti dalla SottoQuery.
Esempio 3°: Lettere che non sono caratteri finali nel vocabolario italiano
SELECT
Lettera
FROM Alfabeto
WHERE LETTERA NOT IN (SELECT RIGHT(Italiana,1) FROM Vocabolario);
In MySQL il comando è identico ma è supportato solo dalla versione 4.1.
3) QueryPrincipale WHERE [NOT] EXISTS (SottoQuery)
Il predicato EXISTS estrae tutti i record della query principale per i quali la SottoQuery restituisce almeno un record. Con la parola riservata NOT (opzionale) verranno estratti dalla query principale quei record per cui la SottoQuery non restituisce nessun record.
Esempio 4°: Parole che non iniziano con caratteri alfabetici
SELECT
ITALIANA FROM VOCABOLARIO WHERE NOT EXISTS (SELECT Lettera FROM ALFABETO WHERE
Left(Italiana,1)=Lettera)
In MySQL il comando è identico ma è supportato solo dalla versione 4.1.
QUERY FULLTEXT
Una ricerca fulltext è una ricerca su tutti i campi del record. In Access questa tipologia di query non è pienamente supportata ovvero non è previsto un tipo di indicizzazione adatto a questo tipo di ricerche trasversali. Per implementare la ricerca fulltext devo costruire una clausola WHERE che replichi la condizione di filtro per ogni campo che intendo analizzare.
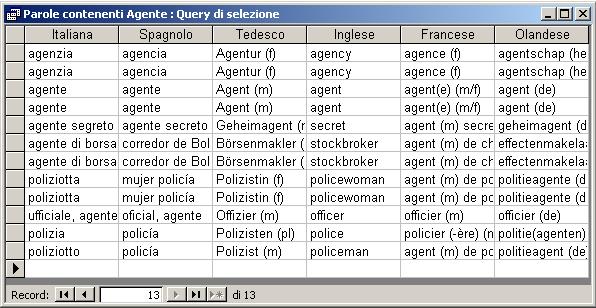
Esempio: per cercare le righe che contengono, in almeno un idioma, la sottostringa "agent" devo scrivere:
SELECT * FROM Vocabolario WHERE
(Italiana Like "*AGENT*") OR (Spagnolo Like "*AGENT*") OR
(Tedesco Like "*AGENT*") OR (Inglese Like "*AGENT*") OR
(Olandese Like "*AGENT*") OR (Francese Like "*AGENT*")
L'esecuzione presenta questo risultato:
In MySQL la ricerca FULLTEXT è supportata. Per creare un indice FULLTEXT su tutti i campi del vocabolario scrivo questo comando:
DROP INDEX
RicercoOvunque ON VOCABOLARIO;
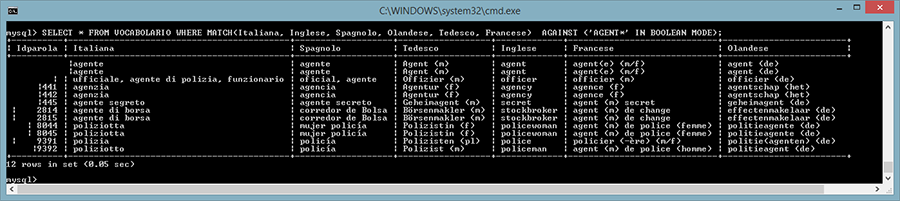
CREATE FULLTEXT INDEX RicercoOvunque ON VOCABOLARIO
(Italiana, Spagnolo, Tedesco, Inglese, Francese, Olandese);
La ricerca è fatta
con un comando di questo tipo:
SELECT * FROM VOCABOLARIO WHERE MATCH(Italiana, Inglese, Spagnolo, Olandese,
Tedesco, Francese) AGAINST ('AGENT*' IN BOOLEAN MODE);
La ricerca appena mostrata visualizza l'elenco delle righe che contengono in uno dei campi indicizzati almeno una parola che inizia con la sequenza "agent".
Oltre alla stringa di ricerca, AGAINST può contenere al suo interno un search_modifier tra quelli che MySql rende disponibili:
search_modifier:
{
| IN BOOLEAN MODE
| IN
NATURAL LANGUAGE MODE
| IN NATURAL LANGUAGE MODE WITH QUERY
EXPANSION
| WITH QUERY EXPANSION
}
La peculiarità del
BOOLEAN MODE è la possibilità di utilizzare i seguenti operatori
per affinare le ricerche:
+: La parola deve esistere in ogni
riga.
-:
La parola non dev’essere presente. Attenzione: una stringa di ricerca
contenente solo parole precedute dal ‘-‘ ritornerà sempre un risultato vuoto.
Infatti non è valida la logica ‘ritorna tutte le righe escluse quelle che
presentano i termini contrassegnati dal -‘.
*:
L’asterisco funge da carattere jolly. Viene posto in fondo per indicare che si
intende estrarre tutte le
righe che contengono parole che iniziano con la parola cercata scritta sinistra di
*.
():
le parentesi servono per creare delle espressioni. Si possono includere
parentesi all’interno di altre parentesi.
> <
: maggiore e minore. Questi operatori servono per aumentare o diminuire il
contributo alla rilevanza di una specifica parola. L’operatore
>
aumenta la
rilevanza mentre
<
la diminuisce.
~
: il carattere tilde funge come operatore negativo, in quanto una parola
preceduta da esso, se individuata nella riga, contribuirà ad abbassare la
rilevanza. Da non confondersi con l’operatore -, in quanto la tilde diminuisce la
rilevanza ma non esclude la riga dal risultato.
"
: doppio apice. Questo operatore serve ad eseguire la query cercando
letteralmente quello che è contenuto al suo interno
I seguenti esempi dovrebbero chiarire le spiegazioni del pezzo precedente:
| 'apple banana' | :Trova delle righe che contengano almeno una di queste parole. |
| '+apple +juice' | Trova righe che contengano entrambe le parole. |
| '+apple macintosh' | Trova righe che contengano la parola ‘apple’ la cui importanza sale se contengono anche ‘macintosh’. |
| '+apple -macintosh' | Trova righe che contengono ‘apple’ E che NON contengono ‘macintosh’. |
| '+apple ~macintosh' | Trova righe che contengono “apple”, e che in caso contengano la parola “macintosh”, diminuisce la loro rilevanza rispetto ai risultati che non la contengono. Questo è un metodo meno di impatto della ricerca ‘+apple -macintosh’, in quanto la presenza di “macintosh” fa in modo che la riga non sia affatto nel risultato. |
| '+apple +(>turnover <strudel )' | Trova delle righe che contengono “apple” e “turnover”, o “apple” e “strudel” (in qualsiasi ordine), ma da maggiore rilevanza a “apple turnover” piuttosto che “apple strudel”. |
| 'apple*' | Trova righe che contengono parole come “apple”, “apples”, “applesauce”, or “applet”. |
| "Una frase" | Trova righe che contengono l’esatta frase “una frase” (ad esempio, la riga potrebbe contenere “una frase bella” ma non “una bella frase”). |
QUERY INCROCIATE
Rappresentano l'equivalente del menu "Report tabelle pivot ..." di Excel.
La sintassi generica è:
TRANSFORM FunzioneStatistica(campo)
IstruzioneSQLDiSelezione
PIVOT CampoPivot [IN (Valori da visualizzare in colonna)]
I valori restituiti in CampoPivot vengono utilizzati come intestazioni di colonna nel set dei risultati della query.
Le query incrociate vengono utilizzate quando si vuole porre in evidenza la relazione che intercorre tra due grandezze.
Esempio 1°: per visualizzare il numero di assenze distinto per classe e per mese:
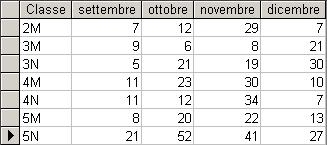
uso la query:
TRANSFORM Count(*) AS Nr
SELECT Classe FROM Assenze GROUP BY Classe
PIVOT Format([DataAssenza],"mmmm");
La stessa informazione poteva essere ottenuta anche con una query di raggruppamento ma in una forma decisamente meno leggibile:
SELECT Classe, Format(DataAssenza,"mmmm")
AS Mese,
Count(*) AS Nr FROM Assenze
GROUP BY Classe, Format([DataAssenza],"mmmm")
ORDER BY Classe;
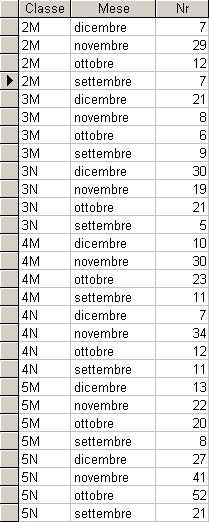
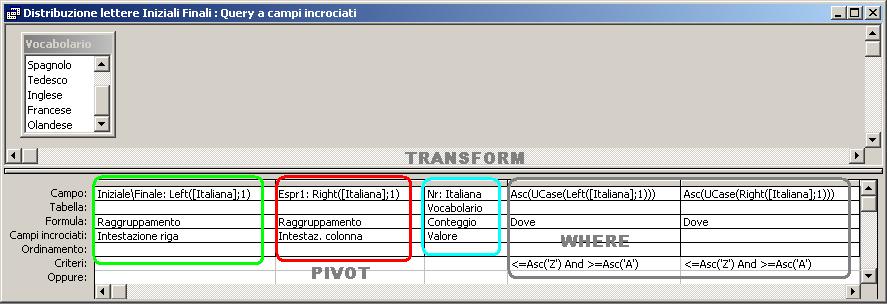
Esempio 2°: Per visualizzare la distribuzione, nel vocabolario italiano, delle lettere iniziali rispetto a quelle finali posso utilizzare questo comando SQL
TRANSFORM Count(Vocabolario.Italiana) AS
Nr
SELECT Left([Italiana],1) AS
[Iniziale\Finale]
FROM Vocabolario
WHERE
Asc(UCase(Left(Italiana,1)))<=Asc('Z') AND Asc(UCase(Left(Italiana,1)))>=Asc('A')
AND Asc(UCase(Right(Italiana,1)))<=Asc('Z') AND
Asc(UCase(Right(Italiana,1)))>=Asc('A')
GROUP BY Left([Italiana],1)
PIVOT Right([Italiana],1);
che fornisce questo risultato:
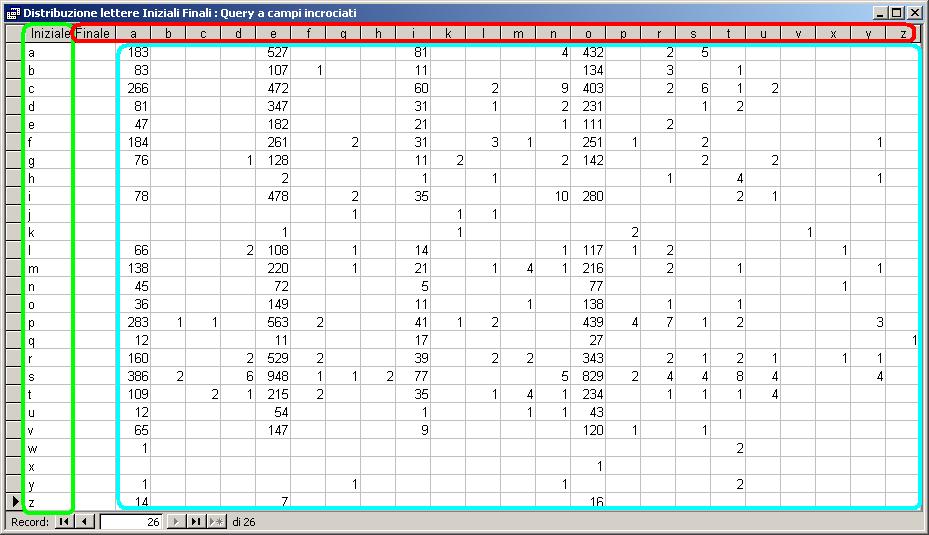
Nel generatore di query di ACCESS la query analizzato si presenta così: