MINI CORSO DI MICROSOFT ACCESS - parte 1°
|
MINI CORSO DI MICROSOFT ACCESS - parte 1° |
(revisione del 5 ottobre 2009)
INTRODUZIONE
Access è composto da diversi pannelli (nelle immagini i diversi pannelli delle diverse versioni di Access):
| Access 97 | |
|
|
|
| Access 2000 | Access XP | Access 2003 |
|
|
|
|
 |
 |
 |
| ACCESS 2007 | |
 |
|
| ACCESS 2010 | |
 |
|
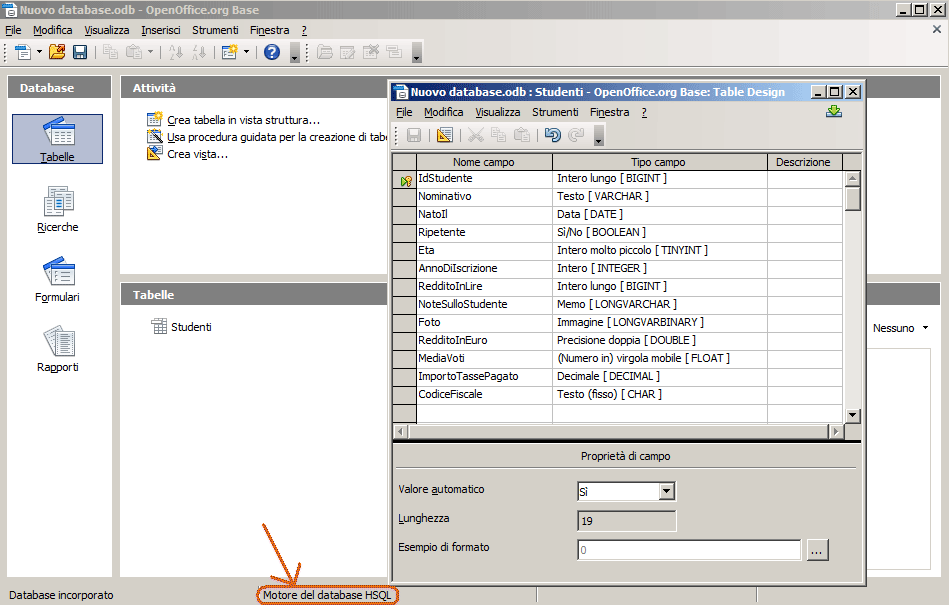
| OPEN BASE 3.3 | |
 |
|
TABELLE:
Viene utilizzato per la definizione degli archivi (modalità struttura) oppure
per inserire i dati (modalità inserimento)
QUERY:
viene utilizzato per le interrogazioni ovvero le ricerche
I primi 2 pannelli rappresentano il livello utente dell’applicativo e consentono l’analisi dei dati (statistiche ed ordinamenti).
Es.
riclassificazioni di bilancio.
MASCHERE:
In questo pannello definisco le videate (FORM) dove gli utenti possono inserire
i dati in maniera controllata e semplificata.
REPORT:
Qui vengono definite le reportistiche sui dati analizzati. Al contrario delle
maschere (FORM) nei report non è possibile inserire dei dati. I report sono
molto usati nei resoconti o nella modulistica.
MACRO
E MODULI: Il 3 e il 4 pannello consentono la programmazione di Access.
Permettono la creazione di veri e propri applicativi.
Creazione di una tabella:
Dopo aver cliccato sul pulsante “NUOVO” selezioniamo la voce “Visualizza Struttura” nella finestra di dialogo che compare.
Prima di procedere alla definizione di una tabella è necessario presentare i tipi di dato disponibili in Access.
Immaginiamo
di dover definire un archivio clienti.
La griglia di definizione dei campi, oltre a i nomi contiene la definizione del tipo dei campi.
Vi ricordo che un campo in una tabella rappresenta una delle voci presenti all'interno della sua struttura.
I
tipi disponibili sono:
| CONTATORE: |
I campi di questo tipo vengono automaticamente inizializzati con valori unici (rispetto alla stessa tabella).
Ogni tipo di dato ha un elenco di proprietà aggiuntive visibili in basso.
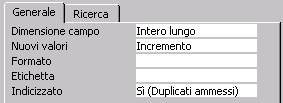
Le proprietà aggiuntive salienti per il tipo contatore sono:
Nuovi Valori:
I possibili valori sono: Incremento: I
valori di questo campo verranno incrementati partendo dal valore iniziale 1. Ad
ogni nuova scheda verrà generato il numero successivo. Casuale:
I valori vengono sparati a casaccio chiaramente senza duplicati
Indicizzato:
Può assumere come valori: ”NO”,
“SI (Duplicati ammessi)”, “SI (Duplicati non
ammessi).
L’indicizzazione
è una delle proprietà + importanti.
Un
campo indicizzato è sostanzialmente un campo al quale viene affiancata una
struttura dati che velocizza le ricerche e gli ordinamenti. Il rovescio della
medaglia per l'indicizzazione è rappresentato da una minor velocità di
registrazione di una nuova scheda poichè oltre all'informazione occorre
aggiornare tutta la struttura dati associata (indici). Un esempio pratico
di indicizzazione è l’elenco telefonico. Il campo indicizzato in questo caso è
il cognome (all'interno della stessa località!). Un campo non indicizzato
può essere consultato solo in maniera sequenziale. Ricercare, sull’elenco, una
persona tramite il numero di telefono comporta una ricerca
sequenziale ovvero parto dal primo e li leggo tutti, uno per uno, fino a che
non lo trovo.
Esercizio: Calcolare il numero di letture medio necessarie per trovare un nominativo in un archivio sequenziale di N schede.
Soluzione: quando consulto un archivio quello che maggiormente influisce sulla velocità è il numero di letture. Il numero medio di letture quindi fornisce un valido parametro sulla bontà del metodo utilizzato per ricercare una determinata scheda (record) all'interno di un tabella. La ricerca sequenziale consiste nello scorrere un archivio una scheda dopo l'altra. Con N schede la casistica di letture necessarie a trovare il nostro nominativo è:
1 lettura (primo colpo), 2 letture (al secondo colpo), ... ,N letture (il nominativo è l'ultimo dell'archivio)
Tutte queste situazioni sono equiprobabili e pertanto la loro media rappresenta la soluzione al nostro problema
1+2+3+
.... N
N
per induzione possiamo dimostrare che
1+2+3+...N=N*(N+1)/2
per cui il numero medio di letture è (N+1)/2. La formula indica quindi che il numero medio di letture cresce linearmente al crescere dell'archivio rendendo la ricerca sequenziale improponibile in archivi anche di piccole dimensioni. In altre parole in un archivio di 1.000.000 sono necessari in media circa 500.000 confronti prima di estrarre il valore cercato.
In
un archivio indicizzato invece la media scende a logm
N
L'algoritmo è simile al metodo usato per trovare una parola sul dizionario:
sapendo che il vocabolario è ordinato alfabeticamente, l'idea è quella di
iniziare la ricerca non dal primo elemento, ma da quello centrale, cioè a metà
del dizionario. Si confronta questo elemento con quello cercato:
- se corrisponde, la ricerca termina indicando che l'elemento è stato trovato;
- se è inferiore, la ricerca viene ripetuta sugli elementi precedenti (ovvero
sulla prima metà del dizionario), scartando quelli successivi;
- se invece è superiore, la ricerca viene ripetuta sugli elementi successivi
(ovvero sulla seconda metà del dizionario), scartando quelli precedenti.
Quando tutti gli elementi sono stati scartati, la ricerca termina indicando che
il valore non è stato trovato.
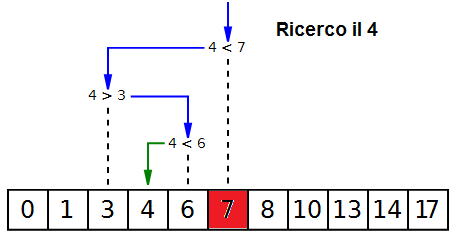
Scarica il file di excel che contiene l'animazione per la ricerca dicotomica
“NO”: Il campo non viene indicizzato e pertanto le ricerche
saranno lente (sequenziali). Selezioniamo questa proprietà per campi che difficilmente
utilizzerò per ricerche o ordinamenti.
“SI (Duplicati ammessi)”: Si tratta di campi soggetti a ricerca ma
che all'interno della tabella presentano valori ripetuti.. Ad esempio la
Ragione Sociale, Nominativo etc.
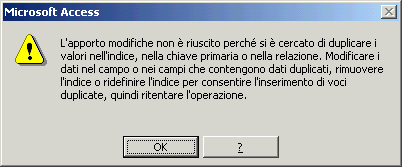
“SI (Duplicati non ammessi): E’ l’indicizzazione tipica dei campi
chiave (Valori unici all'interno della tabella stessa). Con questa proprietà
"settata" non sarà possibile creare 2 schede in quella tabella con valori uguali
in quel campo.
Formato: Questa proprietà equivale a "Formato Celle" di EXCEL.
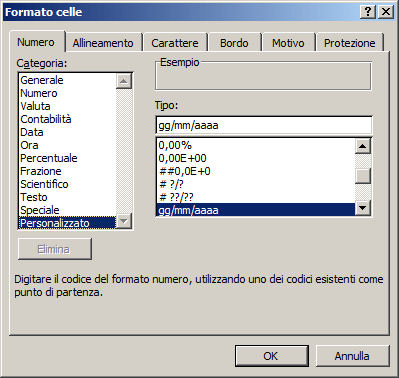
Consente di
visualizzare un dato in modo differente rispetto al suo valore reale registrato
in archivio. Ad esempio, è tramite questa proprietà che risulta possibile
visualizzare il numero 12340 come Lit. 12.340.
Tale proprietà verrà analizzata in dettaglio a seconda del tipo di dato.
Per quanto riguarda il tipo contatore una maschera di formato utile
| Maschera | Valore | Risultato: |
| 000000 | 123 | 000123 |
|
TIPO TESTO:
|
Questo tipo viene utilizzato per campi di tipo testuale (es. Ragione sociale, nominativo, indirizzo). Attenzione, i campi contenenti numeri (vedi cap e telefono) dove non effettuo calcoli ma il cui contenuto è visto come semplice sequenza di caratteri (stringhe) è preferibile definirli come campi testuali.
Una definizione del campo testuale o numerico determina queste modifiche in fase di inserimento.
la stringa "00200" nel caso il campo sia numerico diventa 200
la stringa "030/2972626" in un campo numerico diventa 30 diviso 2972626
Le proprietà di questo tipo sono
Dimensione campo:
Indica il numero di caratteri: va da 1 a 255 (28)
Indicizzato: già visto
(vedi contatore)
Richiesto:
valori possibili solo “SI” o “NO”. Questa proprietà impedisce il
salvataggio del record se questo campo non viene compilato. Utile ad esempio per
evitare il salvataggio di una scheda cliente nella quale non ho digitato la
ragione sociale.
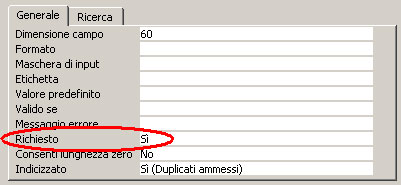
Valore predefinito:
è il valore che viene proposto al momento della creazione della scheda. Ad
esempio se il mio archivio dovrà contenere quasi tutti clienti di Brescia allora
imposto sul campo Provincia questa proprietà al valore: “Brescia”.
Durante l'inserimento di un cliente cambierò il valore solo a quei pochi che non
sono della nostra provincia.
Formato:
Come nel caso del tipo contatore consente di visualizzare un dato in modo differente
da come è stato realmente registrato.
| Maschera | Valore | Risultato: |
| > | "ciAO" | "CIAO" |
| < | "ciAO" | "ciao" |
| @@@@@@@ | "ciAO" | "ciAO " |
| !@@@@@@@ | "ciAO" | " ciAO" |
M
| Simbolo | Valori ammessi | vincoli |
| 0 | cifra 0 a 9 | obbligatoria |
| 9 | cifra 0 a 9 o spazio | facoltativa |
| # | cifra 0 a 9 o spazio, più e meno | facoltativa |
| L | Lettera da A a Z | obbligatoria |
| ? | Lettera da A a Z | facoltativa |
| A | Lettera da A a Z o cifra 0 a 9 | obbligatoria |
| a | Lettera da A a Z o cifra 0 a 9 | facoltativa |
| & | Qualsiasi carattere + lo spazio | obbligatoria |
| C | Qualsiasi carattere + lo spazio | facoltativa |
| Simbolo | Risultato |
| >L<????? |
primo carattere alfabetico obbligatorio reso maiuscolo con > - I restanti al massimo 5 caratteri resi minuscoli con < |
| "ISBN "00\-0000\-000\-0 |
Codice ISBN10 presente sul retro dei libri |
| >LLL\ LLL\ 00L00\ L000L | Codice fiscale in maiuscolo |
| TIPO NUMERICO: |
Questo tipo viene utilizzato per informazioni di tipo numerico.
Come tutti gli altri tipi dispone di una serie di proprietà che ne modificano
il comportamento
Dimensione campo:
per i campi numerici la dimensione non è misurata in caratteri ma in intervallo
di valori (RANGE) disponibile. I valori di dimensione sono:
·
Byte:
per campi il cui valore varia da 0 a 255 (per i voti può andare bene). I valori
sono solo interi (numeri decimali esclusi)
·
Intero: per interi da –32.768 a 32.767 (+/- 215)
·
Intero lungo: per interi da –2.147.483.648 a 2.147.483.647 (+/-
231) . Questa tipologia veniva utilizzata per gli importi in lire
·
Precisione
singola (o single): questo tipo con l’avvento dell’euro ha preso piede poiché
consente, al contrario dei precedenti, l’uso della virgola (numeri decimali)
·
Precisione
doppia: usata nel calcolo scientifico per l’estrema accuratezza dei
risultati.
Formato:
| Maschera | Valore | Risultato: |
| 0,00 | 0,679 | 0,68 |
| 0,631 | 0,63 | |
| 0,555 | 0,56 | |
| #,000 [Blu] | 0,67 | ,670 |
| 1220,67 | 1220,670 | |
| #.##0,00 | 1220,67 | 1.220,67 |
| 220,6 | 220,60 | |
| #.###,00 | 0,67 | ,67 |
| 0,00% | 0,512 | 51,20% |
| gg/mm/aaaa hh.nn.ss | 0,5 | "31/12/1899 12.00.00" |
| gg/mm/aaaa | -21 | "9/12/1899" |
E' possibile definire dei formati personalizzati suddivisi in 4 sezioni
separate dal punto e virgola (formato per i positivi;formato per i negativi; formato
per lo zero;
formato per il valore nullo).
Ad esempio la seguente maschera di formato:
"caldo "#,00 [Rosso];"sotto zero "#,00 [Blu];"Zero";"non pervenuta"
produce questo output:
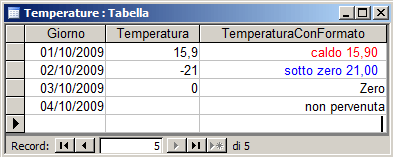
esistono inoltre alcune maschere di formato predefinite:
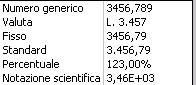
Posizione decimali: indica il numero di cifre decimali da visualizzare nelle maschere di formato predefinite (numero generico, fisso, etc).
Valore predefinito: già visto
Valido se: simile alla sintassi utilizzata in Excel con la funzione conta.se e il somma.se. Contiene i vincoli di controllo sull’esattezza del valore digitato in questo campo. Ad esempio, immaginando di utilizzare questa proprietà sul campo ETA, possiamo mettere “>=0” impedendo così l’inserimento di valori negativi.
Messaggio di errore: In questa proprietà si mette la frase di avviso che segnala all’utente il non rispetto delle regole definite nella proprietà “valido se”. La frase va tra doppi apici
| TIPO DATA/ORA: |
Questo tipo va utilizzato quando l’ordinamento cronologico risulta importante nella consultazione della mia tabella. Per questo campo non è prevista dimensione. Come in Excel, le date sono dei numeri dove la parte intera rappresenta il numero di giornate passate a partire dal 31/12/1899 ad oggi.
La parte decimale invece indica l'ora. Rappresenta la frazione del giorno. Es: 0,5 ==> 12:00
Come per i precedenti tipi esistono delle proprietà:
Formato: Simile a quello visto per i numeri ma adattato alle specifiche esigenze di un campo data. Anche in questo caso esistono dei formati predefiniti
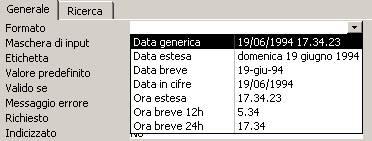
E’ il meccanismo della maschera di formato che trasforma la
visualizzazione della data 22/09/2002
in domenica, 22 settembre 2002.
La sintassi per definire il formato è
praticamente identica a quella di Excel
Vediamo in dettaglio alcuni esempi
| Maschera | Valore | Risultato: | Osservazioni |
| g | #02/28/2009 08.00.00# | 28 | |
| gg | 28 | ||
| ggg | sab | ||
| gggg | sabato | ||
| m | 2 | ||
| mm | 02 | mese con 0 iniziale se necessario | |
| mmm | feb | ||
| mmmm | febbraio | ||
| a | 59 | giorno dell'anno | |
| aa | 09 | ||
| aaaa | 2009 | ||
| i | 6 | numero giorno della settimana (1 lunedì) | |
| ii | 9 | numero della settimana | |
| q | 1 | trimestre | |
| h | 8 | ||
| hh | 08 | ||
| n | 0 | ||
| nn | 00 | ||
| s | 0 | ||
| ss | 00 | ||
| 0,00 | 39.872,33 | nr di giorni dal 31/12/1899 + 1/3 di giorno |
quindi combinando le sigle indicate nella precedente tabella otteniamo per il 6/2/2002:
gg/mm/aa è
06/02/02
g/mmm/aaaa è 6/feb/2002
gggg è
mercoledì
gggg,
g mmmm aaaa è
mercoledì, 6
febbraio 2002
L’ultimo esempio corrisponde al formato predefinito “Data
estesa”
Maschera di Input: impone dei vincoli sull’immissione dei dati. Le regole imposte da questa proprietà garantiscono omogeneità sui dati ovvero evitano inserimenti differenti del tipo 02/01/02 e 02-01-02 che per il computer possono rappresentare un informazione diversa. Questa proprietà può, ad esempio, obbligare l’utente ad inserire il secolo nella compilazione di una data (2002 e non 02). I simboli utilizzati con le maschere di input sono già stati presentati nell': Vediamo qui alcuni esempi di inserimento guidato, possibile utilizzando la maschera di input, applicabili alle date:
| Simboloo | Risultato |
| 00/00/0000 |
devo digitare tutti i caratteri che compongono una data completando eventualmente il giorno ed il mese con uno 0 iniziale qualora fosse necessario |
| ##/##/#### |
posso anche non compilare la data ed inserire degli spazi al posto degli 0 iniziali |
Valore predefinito:
ha lo stesso significato visto per i campi di tipo numerico. Se in questa
proprietà digito, ad esempio “=now()” il campo, quando creo una nuova scheda,
viene impostato con l'orario che corrisponde all'istante di creazione
della scheda stessa.
Questo esempio è comodo quando devo tener traccia dell'istante di
creazione della scheda.
| TIPO MEMO: |
Solitamente questo tipo è utilizzato per le note. Può contenere
fino a 64 mila caratteri (216). Questo campo, al contrario del tipo testo, non può
essere indicizzato e pertanto le ricerche al suo interno sono lente
(sequenziali).
Le
proprietà di questo tipo di campo sono + o meno le stesso del campo di tipo
testo a parte la dimensione e l’indicizzazione
|
TIPO Si/No (booleano) |
Viene
utilizzato per quei campi che devono mentenere nella tabella un’informazione
del tipo vero o falso.
Esempio: per distinguere in archivio i clienti esteri da quelli nazionali
creo un campo booleano che avrà il valore “Si” (vero) in
corrispondenza di quelli italiani, falso altrimenti.
Molte
volte questo tipo viene sostituito con un tipo numerico dove al valore 0 faccio
corrispondere il falso, al vero tutti gli altri valori.
| TIPO VALUTA: |
E’ un tipo numerico che utilizza le impostazione di valuta del sistema operativo (S.O.) ospitante (nel nostro caso quindi definito a livello di WINDOWS). Cambiando le impostazioni a livello di S.O. cambia di conseguenza il comportamento di questo tipo di dato. Se non si devono costruire applicazioni a diffuzione internazionali è del tutto inutile.
