![]()
![]()
MINI CORSO DI MICROSOFT
ACCESS/OPEN BASE
parte 1°
![]()
![]()
|
|
MINI CORSO DI MICROSOFT
ACCESS/OPEN BASE |
|
INTRODUZIONE
In questo manuale verranno illustrati i due principali software desktop relativi alla gestione degli archivi (database): Access (2003, 2007, 2010 e 2013) e OpenOffice Base (OOBase 4.0).
Access si presenta con diversi pannelli. Nelle immagini sottostanti i pannelli disponibili a seconde delle versioni di Access con vicino l'icona dell'applicazione:
| Access 97 | |
|
|
|
| Access 2000 | Access XP | Access 2003 |
|
|
|
|
 |
 |
 |
| ACCESS 2007 | |
 |
|
| ACCESS 2010 | |
 |
|
| ACCESS 2013 | |
 |
|
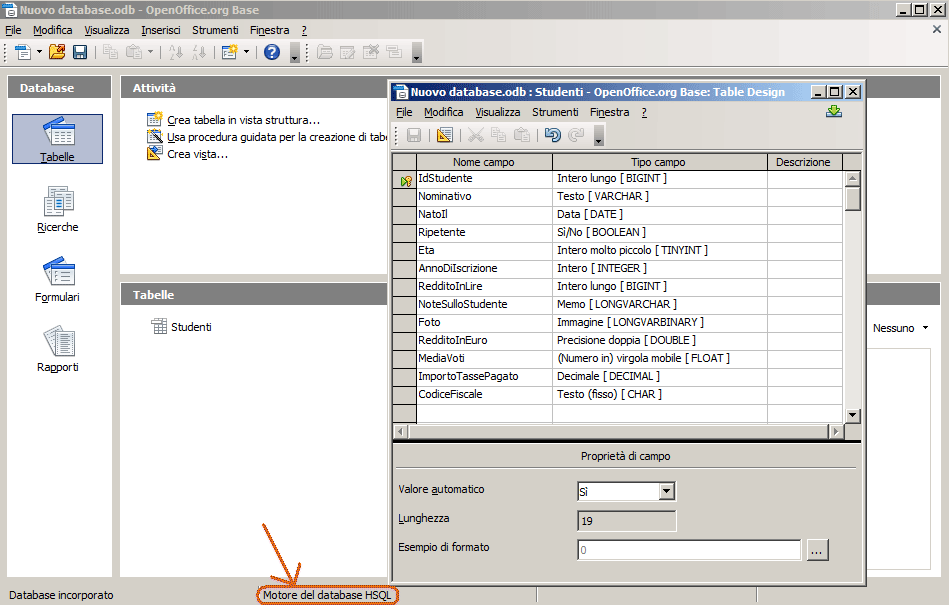
Open Base è anch'esso composto da diversi pannelli (visibili sul fianco sinistro della finestra iniziale): Tabelle, Ricerche, Formulari e Rapporti. Nella figura si noti l'indicazione relativa al motore db utilizzato: HSQL.
| OPEN BASE | |
 |
|
Analizziamo ora le principali funzioni di access. Nelle versioni di Access 97, Access 2000, Access XP e Access 2003 queste erano rappresentate da pannelli posizionati sulla parte sinistra della maschera di apertura. Nelle nuove versioni di Access (dal 2007 in poi) sono state trasferite all'interno del ribbon "Crea"
TABELLE:
Viene utilizzato per la definizione degli archivi (modalità "struttura tabella")
e
per inserire i dati (modalità "visualizzazione foglio dati")
QUERY
(in OOBase corrisponde a RICERCHE):
viene utilizzato per fare le ricerche all'interno della base dati. Il linguaggio
di interrogazione utilizzato è SQL
I primi 2 pannelli rappresentano il livello utente dell’applicativo e consentono di popolare l'archivio (input) e di realizzare l’analisi dei dati (statistiche ed ordinamenti).
MASCHERE
(in OOBase
corrisponde a
FORMULARI):
In questo pannello definisco le videate (Form o Maschere) dove gli utenti possono inserire
i dati in maniera controllata e semplificata.
REPORT
(in OOBase
corrisponde a
RAPPORTI):
Qui vengono definite le reportistiche disponibili sui dati. I report sono
molto usati nella rendicontazione e nella modulistica.
MACRO E MODULI (o CODICE) (in OOBase non esiste un pannello analogo ma è possibile ottenere la stessa funzionalità utilizzando la combinazione di tasti: ALT+F11): Questi pannelli sono relativi alla programmazione e consentono la costruzione di veri e propri applicativi.
Analizziamo ora le funzionalità presenti nel primo pannello
Il file (Mdb per access 2003, Accdb per access successivi e Odb in OOBase) rappresenta il contenitore (archivio) delle informazioni che descrivono il fenomeno che intendiamo registrare. Il nostro archivio può essere composto da dati non omogenei (ad esempio Alunni, Professori, Voti, Assenze, ...). Ogni gruppo di dati omogenei viene registrato all'interno di uno stesso contenitore detto tabella. Quindi un file di Access/OOBase può contenere una o più tabelle. Le proprietà che caratterizzano ogni singolo elemento (record) della stessa tabella vengono definite campi. In una rappresentazione tabellare le righe rappresentano i record mentre le colonne i campi. L'insieme delle descrizione dei campi (nome, dimensione, tipo ...) prende il nome di struttura della tabella.

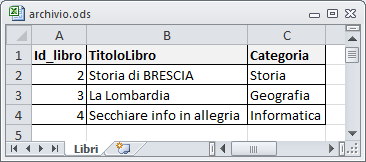
Un db composto da una sola tabella si dice monolitico. Per gestire un db monolitico possiamo utilizzare anche un foglio elettronico:
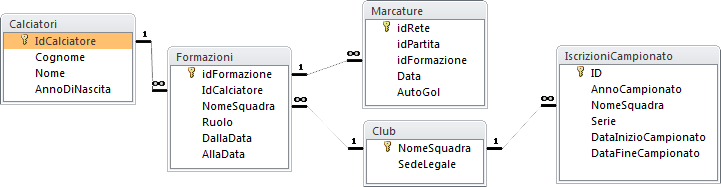
Un DB composto da diverse tabelle in relazione tra loro si dice Relazionale. Le relazioni tra le tabelle, permettono di manipolare i dati più facilmente e soprattutto evitano la ridondanza dei dati, ovvero la duplicazione delle informazioni che è inevitabile quando si opera con singole tabelle indipendenti. Un Diagramma Entità-Relazioni (ERD o Entity-Relationship Diagram) come quello sottostante evidenzia i collegamenti logici tra le tabelle del database.
Per creare una tabella dobbiamo procedere in questo modo:
>> ACCESS 2003: Richiamiamo il pannello Tabelle e poi clicchiamo sul bottone "Nuovo":
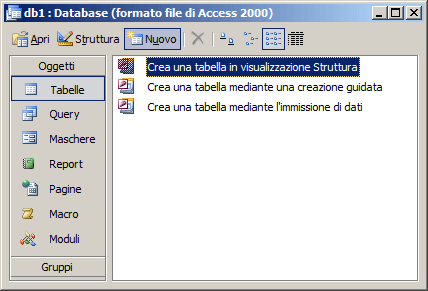
selezioniamo quindi la voce “Visualizzazione Struttura” presente nella finestra di dialogo
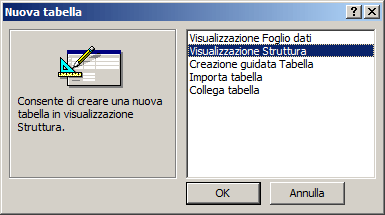
e confermiamo cliccando sul bottone "OK".
>> ACCESS 2007/2010/2013: Richiamiamo il pannello "Crea" sulla barra multifunzione e poi clicchiamo su "Struttura Tabella".
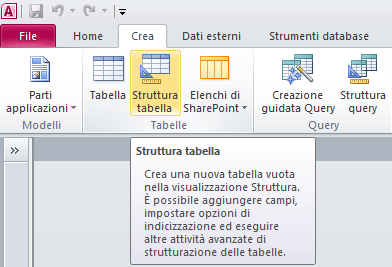
>> OOBase: Richiamiamo il pannello Tabelle e poi clicchiamo su "Crea tabella in vista struttura..."
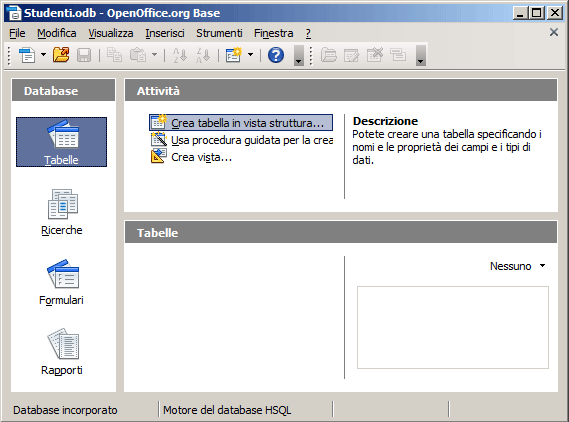
Nella griglia proposta dobbiamo definire la struttura della tabella ovvero
l'elenco dei campi che descrivono i dati che vogliamo registrare. La descrizione
dei campi comprende, oltre al nome, il tipo di dato, la dimensione e una serie
di proprietà specifiche, legate alla tipologia selezionata.
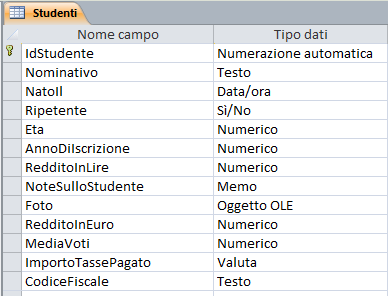
Un esempio di struttura
potrebbe essere la seguente (propone una ipotetica tabella "Studenti")
| ACCESS 2003 | ACCESS successivi | Script SQL per generare la tabella |
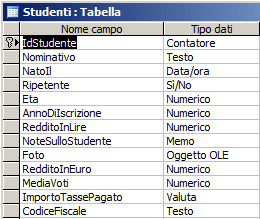 |
 |
CREATE TABLE
Studenti ( IdStudente COUNTER CONSTRAINT IdStudente PRIMARY KEY, Nominativo TEXT(60) CONSTRAINT Nominativo NOT NULL, NatoIl DATETIME, Ripetente BIT, Eta BYTE, AnnoDiIscrizione SMALLINT, RedditoInLire LONG, NoteSulloStudente LONGTEXT, Foto LONGBINARY, RedditoInEuro DOUBLE, MediaVoti SINGLE, ImportoTassePagato CURRENCY, CodiceFiscale TEXT(16) CONSTRAINT CodiceFiscale Unique ) |
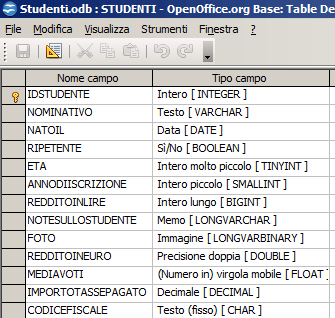
| OOBase | Script in HSQL (http://hsqldb.org/) per generare la tabella |
 |
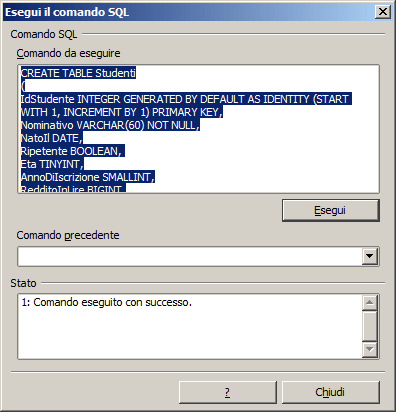
CREATE TABLE Studenti ( IdStudente INTEGER GENERATED BY DEFAULT AS IDENTITY (START WITH 1, INCREMENT BY 1) PRIMARY KEY, Nominativo VARCHAR(60) NOT NULL, NatoIl DATE, Ripetente BOOLEAN, Eta TINYINT, AnnoDiIscrizione SMALLINT, RedditoInLire BIGINT, NoteSulloStudente LONGVARCHAR, Foto LONGVARBINARY, RedditoInEuro DOUBLE, MediaVoti FLOAT, ImportoTassePagato DECIMAL, CodiceFiscale CHAR(16), CONSTRAINT CodiceFiscale UNIQUE(CodiceFiscale) ) |
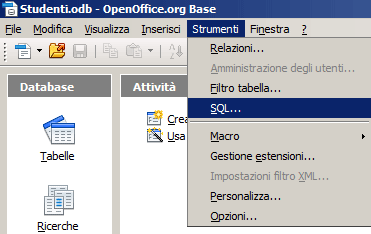
Per eseguire il comando SQL di creazione della tabella in OOBase occorre seguire questi passaggi:
| 1) Richiamare lo strumento SQL | 2) Incollare ed eseguire il comando SQL |
 |
 |
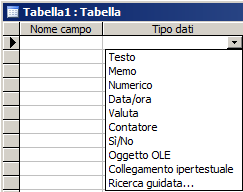
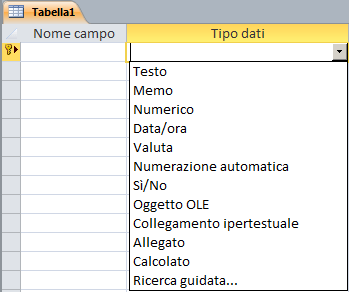
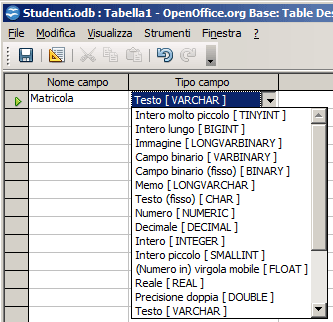
La definizione della struttura di una tabella richiede la conoscenza dei tipi di dato disponibili. L'elenco delle tipologie disponibili è visibile, in corrispondenza della colonna "Tipo Dati" ("Tipo Campo" in OOBase), quando espando il combobox nella griglia di definizione dei campi.
| ACCESS 2003 | ACCESS successivi | OpenBase |
 |
 |
 |
I
tipi disponibili sono:
| CONTATORE: |
I campi di questo tipo vengono automaticamente inizializzati con valori unici (ogni record della stessa tabella assume in questo campo un valore diverso).
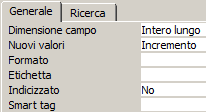
In Access 2007/2010/2013 questo campo si chiama "Numerazione automatica".Questo tipo di dato è caratterizzato dalle seguenti proprietà aggiuntive:
| ACCESS 2003 | ACCESS successivi |
 |
 |
Le proprietà aggiuntive più importanti per il tipo contatore sono:
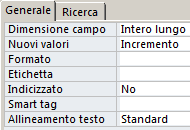
Dimensione Campo (Access):
I possibili valori sono:
- Intero lungo: I
valori generati sono degli interi a 32 bit.
- ID replica: I valori generati sono
dei GUID (Globally Unique Identifier).
Si tratta di valori a 128 bit (16 byte) che vengono rappresentati utilizzando 32 simboli esadecimali
(esempio
{12CE7B48-B3FA-4109-B561-FDAAB1C19049}). Gli ID replica sono progettati per
identificare in modo univoco i vari oggetti (tabelle, record, etc) contenuti nei database
assegnati ad
un particolare set di repliche. Un set di repliche è un insieme di
elementi appartenenti ad un gruppo di archivi (posizionati anche in zone remote tra loro) che devono
essere mantenuti allineati tra loro mediante un'operazione di sincronizzazione. Questo tipologia
di contatore risulta necessaria, nei processi di allineamento
tra db appartenenti allo stesso set di repliche, per evitare
che durante la sincronizzazione a record differenti venga assegnata la stessa chiave primaria.
La sincronizzazione è quindi un processo di aggiornamento, tra due o più archivi che si attua applicando le modifiche apportate a ciascun db a tutti gli altri membri appartenenti al medesimo set di repliche. Nelle figure sottostanti vengono mostrati i menu di access 2003 e 2007/2010/2013 che consentono di attivare questa funzionalità.
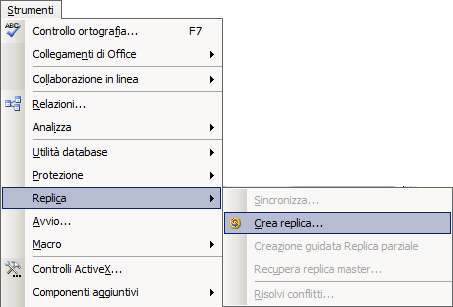
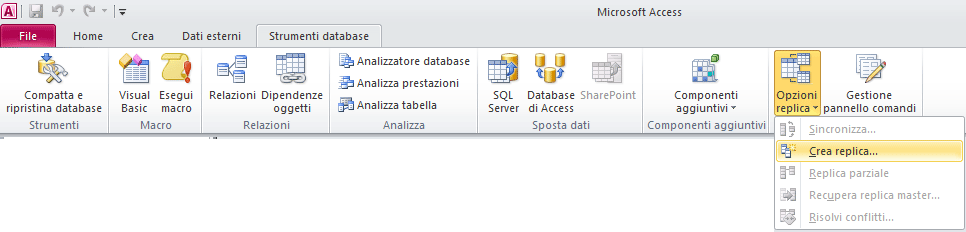
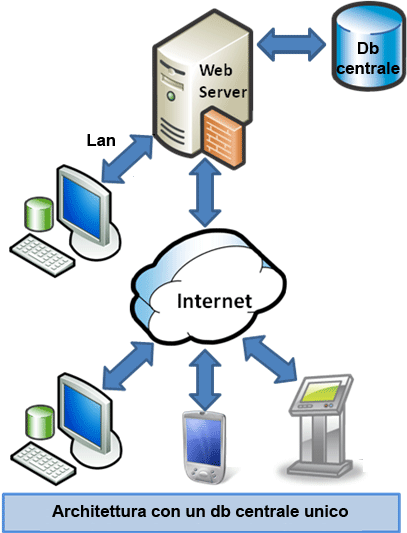
Quando si sviluppa un'applicazione multiutente
è preferibile avere un unico DB centrale. L'archivio viene alimentato da diversi client che
possono risiedere nella stessa LAN oppure essere connessi remotamente tramite
internet. I client remoti solitamente sono dei browser che comunicano con una WebApp
installata
sul server centrale oppure
sono delle applicazioni sviluppate secondo la logica Client/Server (parte del software è
sul client [interfaccia] e parte sul server [gestione dati]. Il modulo software
client e quello server comunicano tra loro mediante uno scambio di comandi
testuali).
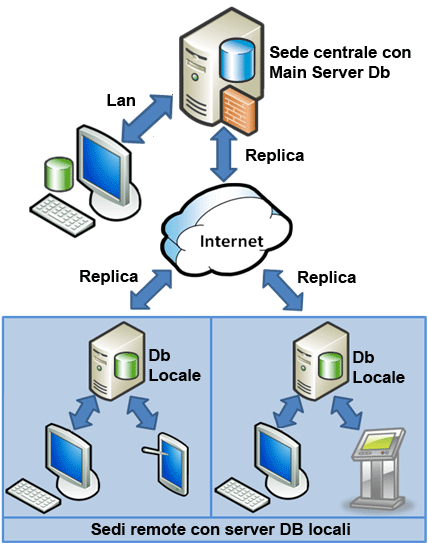
Non sempre però questa architettura è applicabile. Si pensi a situazioni dove
mancano
linee stabili oppure quando sono molto lente. La soluzione per questi casi è quella di creare diversi DB,
simili nella
struttura ma tra loro indipendenti, che ad intervalli prestabiliti si allineano mediante
meccanismi di sincronizzazione.
Ogni DB (presso la sede centrale e presso le sedi periferiche) lavora
separatamente
rispetto agli altri.
Questi archivi "indipendenti" vengono assegnati allo stesso set di repliche.
Ad intervalli di tempo stabiliti le modifiche
locali apportate a ciascun membro vengono applicate anche a tutti gli altri
mediante un'operazione di sincronizzazione. Al termine della sincronizzazione i
contenuti dei membri dello stesso set di repliche saranno uguali.
Se vengono modificati i dati di uno stesso record, presente in due DB diversi
dello
stesso set di repliche, è possibile che si verifichino conflitti per cui è
necessario definire delle regole gerarchiche tra i membri stessi.
 |
 |
Nuovi Valori (Access):
I possibili valori sono:
- Incremento: I
valori di questo campo verranno incrementati partendo dal valore iniziale 1. Ad
ogni nuova scheda verrà assegnato il numero successivo.
- Casuale:
I valori vengono sparati a casaccio chiaramente senza duplicati
Indicizzato
(Access):
Può assumere come valori: ”NO”,
“SI (Duplicati ammessi)”, “SI (Duplicati non
ammessi).
L’indicizzazione
è una delle funzionalità più importanti dei database
Un campo indicizzato è un campo al quale viene affiancata una struttura dati che permette di velocizzare le ricerche e gli ordinamenti.
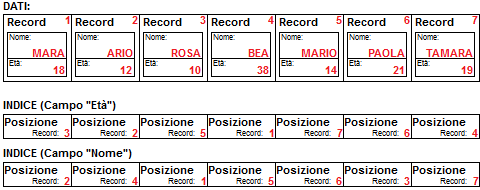
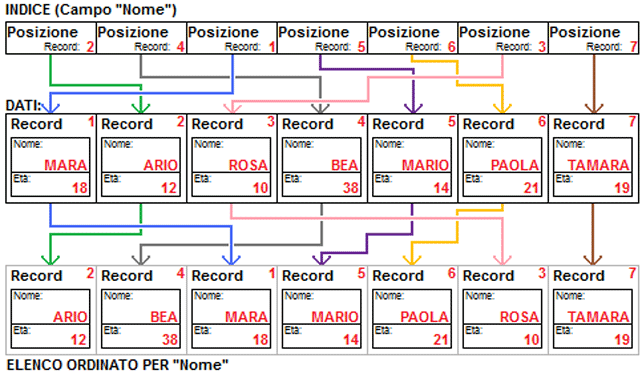
Se leggo l'archivio DATI seguendo le posizioni indicate dall'indice relativo all' "Età" ottengo un elenco ordinato rispetto a quel campo:
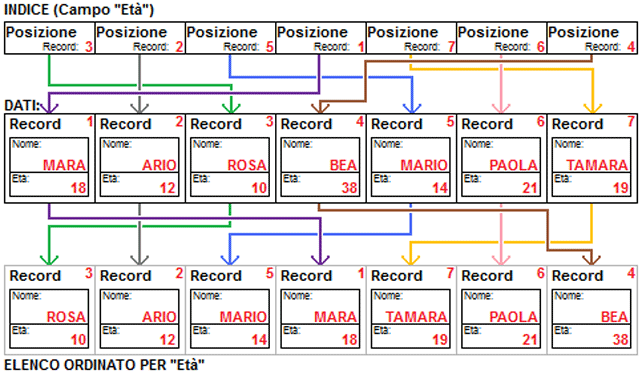
Se invece leggo l'archivio DATI seguendo le posizioni indicate dall'indice relativo al "Nome" ottengo un elenco ordinato alfabeticamente:
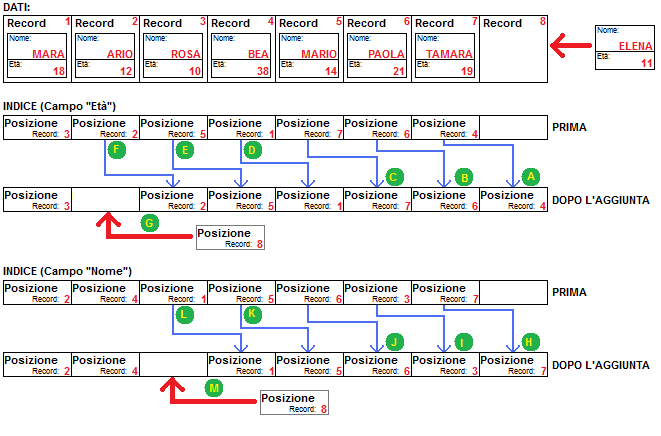
Il prezzo dell'indicizzazione è rappresentato da una minor velocità nelle operazioni di aggiornamento dell'archivio (aggiunta/modifica) poiché, oltre alle modifiche sui dati, occorre aggiornare tutti gli indici associati. Nella successiva figura viene mostrato come l'aggiunta di un nuovo record (posto in fondo all'elenco dei dati) determini una serie di operazioni aggiuntive sull'indice (A, B, C, ... , M) che hanno lo scopo di mantenerlo aggiornato.
Negli elenchi ordinati è possibile applicare una serie di algoritmi che abbattono i tempi di risposta nelle ricerche. In un elenco non ordinato l'unica ricerca possibile è quella sequenziale o casuale.
Esempio pratico: Consideriamo un elenco telefonico.
L'indice applicato è sul nominativo
(se considero solo una singola località!) per cui la localizzazione di un numero di
telefono in base al cognome risulta immediata. Immaginiamo ora di ricercare il nominativo della persona che risponde ad un determinato numero di
telefono. In questo caso l'indice non ci supporta per cui siamo costretti a
scorrere l'elenco, partendo dall'inizio, un numero dopo l'altro fino a che non
si arriva a quello richiesto (ricerca sequenziale). I tempi di risposta in
questo caso potrebbero essere anche molto lunghi.
Vediamo in dettaglio i due principali metodi (algoritmi) di ricerca:
Ricerca Sequenziale: Vediamo come calcolare il numero medio di letture necessarie per trovare un nominativo, utilizzando una ricerca sequenziale, in un elenco non ordinato di N schede (record).
Risposta: quando consulto un archivio quello che maggiormente influisce sulla velocità di ricerca è il numero di letture (confronti). Il numero medio di letture quindi è un valido parametro per misurare la bontà del metodo utilizzato nella ricerca. La ricerca sequenziale consiste nello scorrere un archivio partendo dal primo record e procedendo in avanti, una scheda dopo l'altra. Con N schede la casistica delle letture necessarie per trovare un nominativo è:
1 lettura (se lo trovo al primo colpo), 2 letture (se lo trovo al secondo colpo), ... ,N letture (se il nominativo cercato è in fondo all'archivio)
Tutte queste situazioni sono equiprobabili e pertanto la loro media rappresenta la soluzione al nostro problema
1+2+3+
.... N
N
per induzione possiamo dimostrare che
1+2+3+...N=N*(N+1)/2
da cui segue che il numero medio di letture è (N+1)/2. La formula ottenuta evidenzia come la media dei confronti (letture) aumenti linearmente al crescere dell'archivio rendendo la ricerca sequenziale improponibile in archivi di medie dimensioni. Ad esempio in un archivio di un 1.000.000 di record sono necessari, in media, circa 500.000 confronti prima di estrarre il valore cercato.
Ricerca con indice: In
un archivio indicizzato il numero
massimo di letture
scende a logm
N
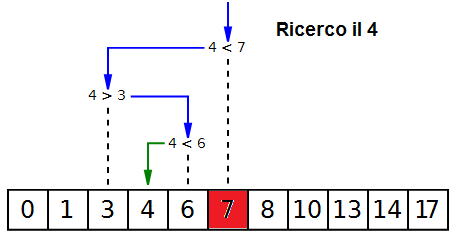
L'algoritmo dicotomico è simile al metodo usato per trovare una parola in un dizionario.
Sapendo che il vocabolario è ordinato alfabeticamente non inizio dal primo
elemento ma da quello centrale, cioè a metà
del dizionario. Si confronta questo elemento con quello cercato e ...
- se corrisponde, la ricerca termina indicando che l'elemento è stato trovato;
- se è inferiore, la tecnica di ricerca procede sugli elementi
precedenti (ovvero sulla prima metà del dizionario), ignorando la seconda metà.
- se invece è superiore, la ricerca procede sugli elementi successivi
(ovvero sulla seconda metà del dizionario), scartando la prima metà.
La ricerca continua partendo dal centro della metà presa in considerazione e
si ripete il metodo finché non trovo l'elemento cercato oppure quando tutti gli elementi sono stati scartati.
In questo caso la ricerca finisce indicando che
il valore non è stato trovato.
Scarica il file di excel che contiene l'animazione della ricerca dicotomica
“NO”: Il campo non viene indicizzato e pertanto le ricerche
saranno lente (sequenziali). Selezioniamo questa proprietà per i campi per i
quali non prevedo ricerche od ordinamenti.
“SI (Duplicati ammessi)”: Si tratta di campi soggetti a ricerca che all'interno della tabella accettano valori ripetuti. Si pensi ad esempio al campo Cognome di una ipotetica tabella Alunni: è probabile che vengano effettuate delle ricerche e che ci siano casi di omonimia.
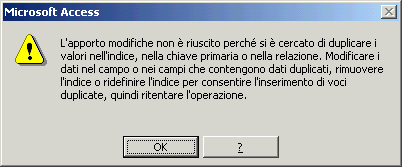
“SI (Duplicati non ammessi): E’ l’indicizzazione usata per i campi
chiave (valori unici all'interno della stessa tabella) e per quelli che non
devono presentare duplicati. Con questa proprietà
"settata" non sarà possibile creare 2 schede, nella stessa tabella,
che presentano valori uguali
in quel campo.
Il campo significativo è il campo utilizzato
dall'utente umano per identificare un record all'interno di una tabella (ad
esempio il campo Nominativo nella tabella ALUNNI). Il campo significativo
è soggetto a ricerche e solitamente presenta casi di omonimia (ad esempio
studenti con lo stesso nominativo!) per cui viene indicizzato con
duplicati.
Il campo chiave (primaria) è utilizzato (solitamente dalle procedure
eseguite sul computer) per individuare in modo univoco ogni singolo record
all'interno di una tabella, aggirando le difficoltà di identificazione derivanti
dai casi di omonimia che possiamo avere nel campo significativo. Il campo chiave è
soggetto a ricerche ed essendo univoco va indicizzato senza duplicati.
Per motivi di performance nelle query è preferibile (ma non obbligatorio!)
utilizzare come campi chiave quelli di tipo numerico.
Il campo chiave e il campo significativo sono i campi
fondamentali di una tabella e devono essere sempre presenti (talvolta
possono coincidere!). Quando progetto una tabella devo identificare
immediatamente quali sono le proprietà della realtà che sto modellando che
possono assumere il ruolo di campi fondamentali. Se non
identifico alcun campo chiave posso creare un campo fittizio ID di tipo
contatore che risulta perciò univoco altrimenti utilizzo quello suggerito dalla
realtà (ad esempio la Targa per la tabella AUTO). Se il campo significativo non presenta casi di omonimia lo posso utilizzare come
campo chiave. Non si tratta però di una scelta valida per 2 motivi:
- se il campo significativo è testuale le performance nelle query, come
campo chiave, sono inferiori rispetto a quelli di tipo numerico;
- il campo significativo, anche se univoco, può presentare valori che non
risultano immutabili nel tempo. Ad esempio la tabella SCUOLEBRESCIANE contiene
nomi di istituti scolastici univoci che però possono variare nel tempo (basti
pensare a: Liceo Scientifico Sperimentale Leonardo => Liceo Scientifico
Leonardo)
Un campo si dice chiave eleggibile se non presenta mai duplicati. Il
campo chiave è scelto tra l'insieme dei campi "chiave eleggibili". Ad
esempio, in un'ipotetica tabella STUDENTI, la Matricola e il Codice Fiscale sono
i campi chiave eleggibili. Tra i campi chiave eleggibili il
campo chiave viene scelto perché più adeguato agli scopi che ci prefiggiamo.
Ad esempio la Matricola risulta più adatta nella tabella STUDENTI di un registro
elettronico di un singolo docente poiché risulta più corta (e quindi più
"gestibile"!) rispetto al Codice Fiscale che richiede la scrittura di 16
caratteri e la raccolta di informazioni personali come la data e il luogo di
nascita. Se invece si considera la tabella di tutti gli STUDENTI italiani il
Codice Fiscale risulta preferibile poiché immediatamente ci suggerisce alcune
informazioni relative allo studente (data di nascita, luogo di nascita, etc)
senza che sia necessario leggere ulteriori campi nel record.
Una chiave multipla è un gruppo di campi che identifica in modo univoco
un record all'interno della stessa tabella. Ad esempio i campi
Nominativo+Telefono nella tabella AMICI rappresentano una chiave multipla.
Le chiavi multiple non vengono utilizzate come chiave nei record poiché
aumentano la complessità delle query a più tabelle (argomento del secondo
modulo). Vengono invece utilizzate per evitare inserimenti multipli dello stesso
dato. Si pensi alla tabella STUDENTI di una scuola: il campo Nominativo potrà
presentare dei duplicati (dovuti all'omonimia!) ma la terna
Nominativo+Classe+DataDiNascita no!
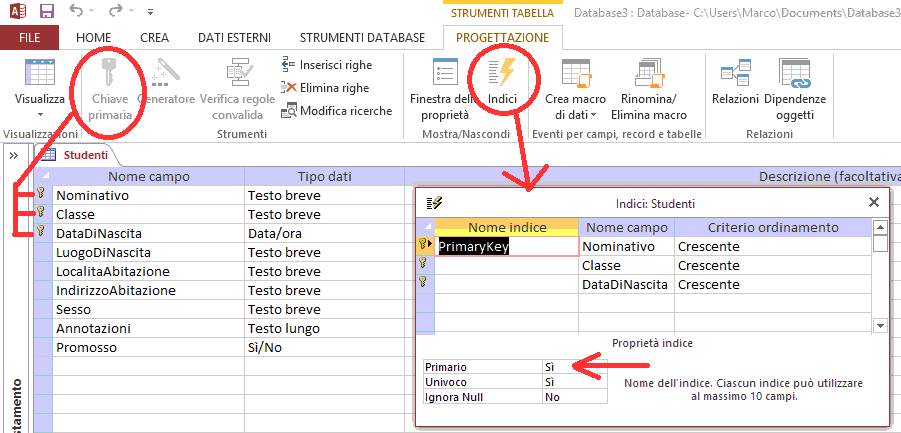
Se si verificasse la rarissima casistica di 2 distinti studenti con lo stesso nominativo, nati lo stesso giorno ed inseriti nella stessa classe sarà necessario ampliare la chiave multipla aggiungendo un ulteriore campo (ad esempio l'indirizzo della loro abitazione).
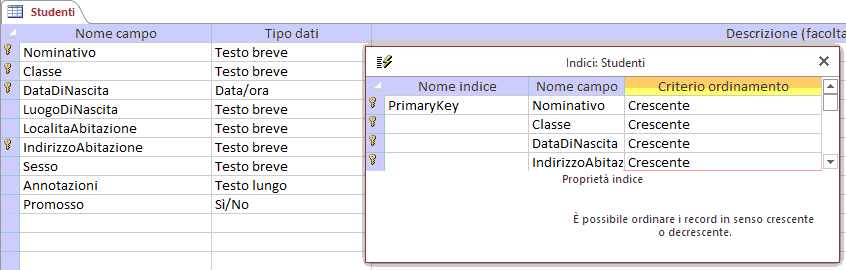
La soluzione ideale rimane la creazione di un opportuno campo chiave: ad esempio Matricola.
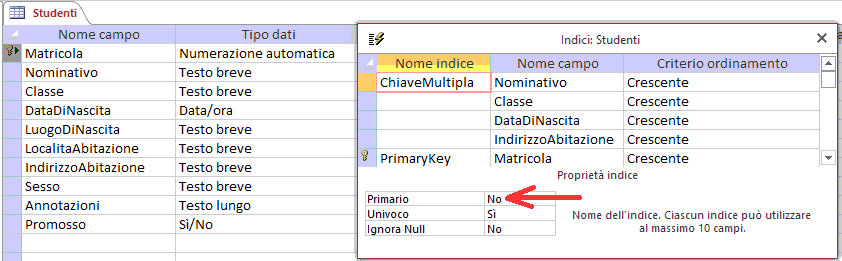
Un campo si definisce "codice parlante" quando, analizzando il suo
valore, possiamo dedurre una serie di informazioni relative al record. Ad
esempio il Codice Fiscale poiché da questo possiamo stabilire: la data di
nascita, la zona di nascita e il sesso. Anche il numero di telefono fisso è
parlante: i primi numeri identificano il distretto telefonico di appartenenza.
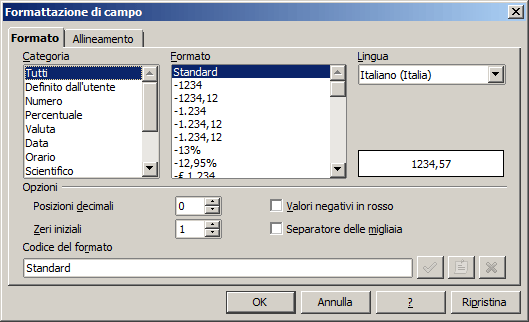
Formato (Access - OOBase): Questa proprietà è simile al "Formato Celle" di EXCEL.
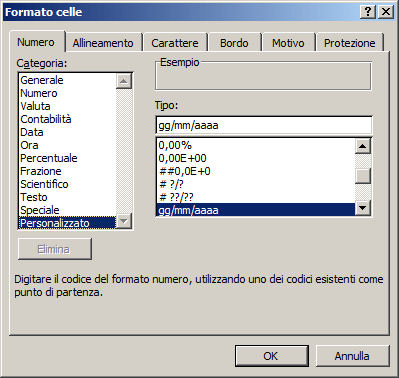
Consente di
visualizzare un dato in modo differente rispetto al suo valore reale, registrato
in archivio. Ad esempio, utilizzando il formato potremo
visualizzare il numero 12340 come "Lit. 12.340".
| Maschera | Valore | Risultato: |
| 000000 | 123 | 000123 |
In OOBase il tipo contatore viene creato selezionando il tipo di dato BIGINT o INTEGER ed impostando la proprietà "Valore automatico" a SI
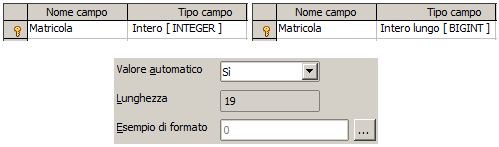
|
TIPO TESTO:
|
Questo tipo di dato viene utilizzato quando il contenuto del campo
è una sequenza di caratteri alfanumerici (stringa) priva di significati
temporali o numerici (es. Ragione sociale, nominativo, indirizzo, ...).
Un campo
contenente solo caratteri numerici e sul quale non effettuo calcoli
(esempio il CAP e il telefono), deve essere dichiarato come testuale!
Infatti se si imposta il tipo numerico al posto di quello
testuale le seguenti stringhe (digitate ad esempio da tastiera) verranno convertite in questo modo:
- Il CAP "00200" verrà registrato come numero 200.
- Il TELEFONO 030/2972626 verrà salvato come numero 30 diviso 29726266.
In OOBase questo tipo di dato viene creato selezionando il tipo CHAR o VARCHAR. La differenza tra CHAR e VARCHAR è che CHAR occupa realmente le dimensioni dichiarate poiché la parte inutilizzata viene riempita con spazi. CHAR va utilizzato solo quando sono sicuro che i caratteri dichiarati vengano tutti utilizzati (si pensi ad esempio al codice fiscale che è sempre lungo 16 caratteri). In OOBase il confronto sui contenuti testuali è case sensitive. Esiste perciò una particolare variante: VARCHAR_IGNORECASE che ignora le differenze tra maiuscolo e minuscolo.
![]()
![]()
![]()
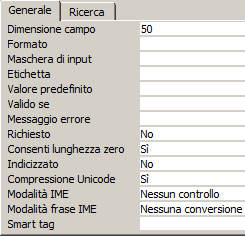
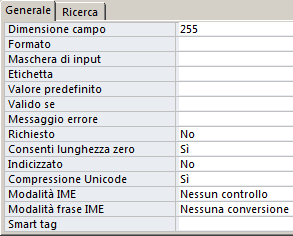
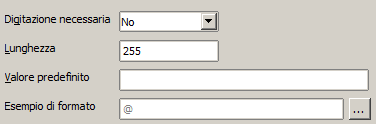
Il tipo testuale è caratterizzato dalle seguenti proprietà aggiuntive:
| ACCESS 2003 | ACCESS successivi | OPEN OFFICE BASE |
 |
 |
 |
Le proprietà aggiuntive più importanti sono:
Dimensione campo (Access -
Indicizzato (Access): già visto
(vedi contatore)
Richiesto (Access - OOBase)
: i valori possibili sono “SI” o “NO”. Questa proprietà impedisce il salvataggio del record quando il campo non risulta compilato. Esempio: evito di salvare una scheda STUDENTE se ho dimenticato di digitare il nominativo.
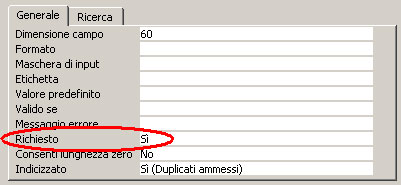
In OOBase questa obbligatorietà è indicata dalla proprietà "Digitazione necessaria". I valori possibili sono "Si" e "No".
Valore predefinito (Access - OOBase)
Formato
| Maschera | Valore | Risultato: | Supportato da: |
| > | "ciAO" | "CIAO" | Access |
| < | "ciAO" | "ciao" | Access |
| @@@@@@@ | "ciAO" | "ciAO " | Access |
| !@@@@@@@ | "ciAO" | " ciAO" | Access |
M
| Simbolo | Valori ammessi | vincoli |
| 0 | cifra 0 a 9 | obbligatoria |
| 9 | cifra 0 a 9 o spazio | facoltativa |
| # | cifra 0 a 9 o spazio, più e meno | facoltativa |
| L | Lettera da A a Z | obbligatoria |
| ? | Lettera da A a Z | facoltativa |
| A | Lettera da A a Z o cifra 0 a 9 | obbligatoria |
| a | Lettera da A a Z o cifra 0 a 9 | facoltativa |
| & | Qualsiasi carattere + lo spazio | obbligatoria |
| C | Qualsiasi carattere + lo spazio | facoltativa |
vediamo alcuni esempi utilizzabili in campi di tipo testo:
| Simbolo | Risultato |
| >L<????? |
primo carattere alfabetico obbligatorio reso maiuscolo con > - I restanti al massimo 5 caratteri resi minuscoli con < |
| "ISBN "00\-0000\-000\-0 |
Codice ISBN10 presente sul retro dei libri |
| >LLL\ LLL\ 00L00\ L000L | Codice fiscale in maiuscolo |
| TIPO NUMERICO: |
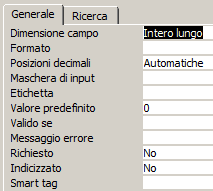
Questo tipo è utilizzato per informazioni di tipo numerico. Come tutti gli altri tipi dispone di una serie di proprietà che ne modificano le caratteristiche (visibili in basso):
| ACCESS 2003 | ACCESS successivi | OPEN OFFICE BASE |
 |
 |
 |
Le proprietà principali per il tipo numerico sono:
Dimensione campo (Access)
·
Byte:
usato per campi il cui
valore varia da 0 a 255 (per i voti può andare bene!). I valori ammessi sono interi
positivi
(i numeri con decimali sono esclusi)
·
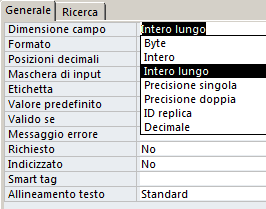
Intero: utile nel caso i valori ammessi siano interi da –32.768 a 32.767 (+/- 215).
·
Intero lungo: per interi da –2.147.483.648 a 2.147.483.647 (+/-
231) .
·
Precisione
singola (o single): questo tipo consente, al contrario dei precedenti, l’uso della virgola (numeri
con decimali)
·
Precisione
doppia: è adatta al calcolo scientifico per la sua estrema precisione.
·
ID replica: Risulta necessaria nei meccanismi di replica
(sincronizzazione).
·
Decimale: Nei file ADP (Un file ADP è un file di Access che contiene maschere, report, macro, moduli VBA e una stringa di connessione. Tutte le tabelle e le query sono memorizzate nel DB server: SQL Server. L'architettura ADP è stata progettata per creare applicazioni client-server utilizzando la stessa modalità adoperata nello sviluppo di applicazione file-server) questo tipo di dato consente la memorizzazione di valori compresi tra –1038–1 e 1038–1.
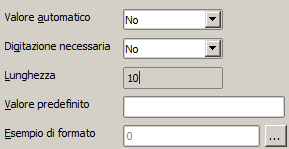
Mentre in Access abbiamo un generico tipo "Numerico" al quale, sfruttando la proprietà "Dimensioni Campo", abbiniamo una particolare tipologia, in OOBase esistono tipi numerici specifici ed esattamente:
·
TINYINT: Occupa un byte. Adatto a contenere valori interi con range [-128, 127].
·
SMALLINT:
Occupa 2 byte. Adatto a contenere valori interi con range [-215, 215-1]=[-32.768
, 32.767].
·
INTEGER: Occupa 4 byte. Adatto a contenere valori
interi con range [-231, 231-1].
·
BIGINT: Occupa 8 byte. Adatto a contenere valori
interi con range [-263, 263-1].
· REAL, DOUBLE: Sono tipi equivalenti. Occupano 8 byte. Vengono usati per contenere valori con la virgola in doppia precisione.
· FLOAT: Equivale al single di Access. E' simile a REAL e DOUBLE ma ha una minore precisione (circa 7 cifre tra parte decimale ed intera). Richiede 4 byte. Vediamo alcuni esempi che mostrano i limiti di precisione per questo tipo di dato. Immaginiamo di digitare in un campo FLOAT i seguenti valori numerici ed analizziamo il valore registrato nel file:
| Cosa digito | Cosa viene registrato |
| 123456789 | registra un valore errato: 123456792 |
| 1234567,1 | registra un valore errato: 1234567,125 |
| 0,12345678 | registra un valore errato: 0,1234568 |
| 0,1234567 | nessun problema |
| 7654321 | nessun problema |
Gli errori sono dovuti alla particolare rappresentazione binaria utilizzata (si tratta della notazione "Floating Point " a 32 bit nota anche con la sigla IEEE754). FLOAT è usato per contenere valori per i quali non è richiesta un'accurata precisione.
·
NUMERIC, DECIMAL: In HSQL (motore db utilizzato da
OOBase) i tipi
sono
equivalenti. La loro precisione è specificata
indicando esattamente il numero massimo di cifre presenti nel numero (comprese
quelle relative alla parte decimale) e nella parte decimale.
Esempi di dichiarazione:
- DECIMAL (2, 1) : definisce un campo che accetta numeri la cui parte intera e
decimale possono contenere al massimo una sola
cifra. Valori come
9,9 1,0
sono accettati mentre vengono scartati i numeri
10,1
o
1,01.
-
DECIMAL(2) : accetta numeri interi da -99 a 99. Nel conteggio delle cifre è
escluso il segno e la virgola.
Questo tipo è equivalente al "Decimale" di Access
Formato
| Maschera | Valore | Risultato: | Supportato da: |
| 0,00 | 0,679 | 0,68 | Access - OOBase |
| 0,631 | 0,63 | ||
| 0,555 | 0,56 | ||
| #,000 [Blu];-#,000 [Rosso] | 0,67 | ,670 | Access |
| 1220,67 | 1220,670 | ||
| -12,3 | -12,300 | ||
| [BLUE] #,000;[RED] -#,000 | 0,67 | ,670 | OOBase |
| 1220,67 | 1220,670 | ||
| -12,3 | -12,300 | ||
| #.##0,00 | 1220,67 | 1.220,67 | Access - OOBase |
| 220,6 | 220,60 | ||
| #.###,00 | 0,67 | ,67 | |
| #. | 10000 | 10 | |
| 0,00% | 0,512 | 51,20% | |
| 0,00E+00 | 0,0123456 | 1,23E-02 | |
| 123456 | 1,23E+05 | ||
| 1,23456 | 1,23E+00 | ||
| 0,00E+000 | 123456 | 1,23E+005 | |
| # ?/? | 11,33 | 11 1/3 | OOBase |
| 11,75 | 11 3/4 | ||
| # ?/?? | 11,33 | 11 32/97 | |
| 11,025 | 11 1/40 | ||
| 11,0025 | 11 | ||
| # ?/??? | 11,33 | 11 33/100 | |
| 11,0025 | 11 1/400 |
La sintassi relativa ai formati numerici consente la definizione di 4 sezioni
separate dal punto e virgola. La prima sezione rappresenta il formato per i positivi,
la seconda quello per i negativi;la terza quella applicata allo zero e
la quarta per il valore nullo.
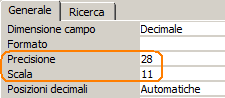
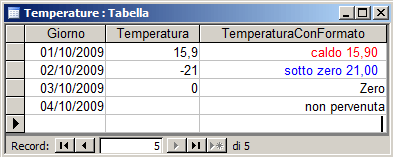
Ad esempio la seguente maschera di formato:
"caldo "#,00 [Rosso];"sotto zero "#,00 [Blu];"Zero";"non pervenuta"
produce questo risultato:
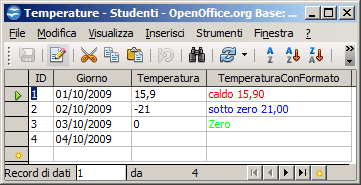
Anche in OOBase esiste una maschera di formato analoga suddivisa in tre parti (non viene gestito il NULL!). La maschera di formato sottostante
[RED] "caldo" #,00;[BLUE] "sotto zero" #,00;"Zero"
produce questo output:
In OOBase è possibile creare dei formati personalizzati basati su
condizioni. Le condizioni devono essere racchiuse tra parentesi quadre [ ].
Nella costruzione delle condizioni è possibile utilizzare qualsiasi combinazione di numeri ed operatori
di relazione (<, <=, >, >=, = e <>). Le condizioni ammesse sono al massimo tre.
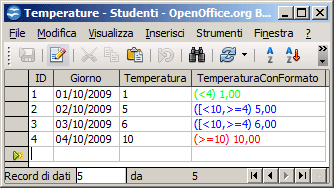
Esempio:
per applicare differenti
colori
a seconda della temperatura
possiamo impostare la seguente maschera di formato:
[<=4][GREEN]"(<4) "#.##0,00;[>=10][RED]"(>=10) "#.##0,00;[BLUE]"([<10,>=4) "#.##0,00
che produce questo risultato:
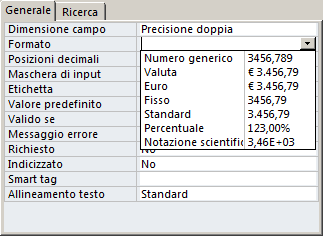
Access e OOBase posseggono delle maschere di formato predefinite:
| ACCESS | OPEN OFFICE BASE |
 |
 |
Posizione decimali (Access
)
Valore predefinito
Valido se (Access): Permette la definizione dei vincoli di validità sui valori digitati. Ad esempio per impedire inserimenti assurdi nel campo "VOTO" della tabella "VERIFICHE" posso impostare questa proprietà a: “
>0 AND <11”.
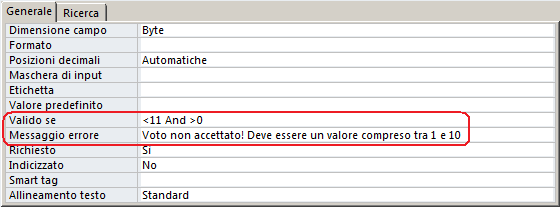
Messaggio di errore (Access): In questa proprietà si mette la frase mostrata nell'avviso che compare quando la proprietà "Valido se" non viene rispettata. Non è necessario delimitare la frase con i doppi apici ".

| TIPO DATA/ORA: |
Questo tipo va utilizzato quando l’ordinamento cronologico
risulta importante. Per questo tipo di campo non è
prevista una dimensione (occupa 8 byte). Come in Excel,
le date sono dei numeri dove la parte intera rappresenta il numero di giorni
trascorsi a partire dal
30/12/1899 fino al giorno rappresentato nel campo.
In Access il riferimento al 30/12/1899 si può verificare utilizzando
le seguenti istruzioni VBA:
-
Le date precedenti il 30/12/1899 vengono registrate come numeri negativi. Il
29/12/1899 viene registrato come -1.
La parte decimale (è interpretata sempre
come valore positivo!) invece indica
la frazione di giorno trascorsa. Ad esempio:
>> 0,5 corrisponde alle
ore 12:00 (se considero il numero come una data completa allora al
30/12/1899 alle ore 12.00).
>>
-0,5 è trattato come un numero positivo per cui è equivalente a 0,5.
>> 1,75 corrisponde al 31/12/1899
alle ore 18.00
>> -1,25 corrisponde al 29/12/1899
alle ore 06.00
In OOBase la gestione dei tipi data/ora è leggermente diversa. I tipi supportati sono:
·
DATE: Questo tipo è utilizzato per registrare una data senza l'orario.·
TIME: Questo tipo è utilizzato per registrare un orario privo di data.·
TIMESTAMP: E' una combinazione del tipo DATE/TIME.A
nche in OOBase le date sono registrate come numeri razionali dove la parte decimale rappresenta la frazione di giorno. La data di riferimento corrispondente a zero è 30/12/1899 (al null invece corrisponde 01/01/1900).
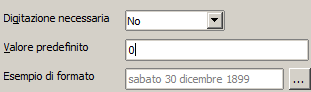
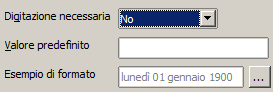
Come per i tipi precedenti esistono delle proprietà aggiuntive:
Formato: Simile a quello visto per i numeri ma adattato alle specifiche esigenze di un campo data/ora. Anche in questo caso esistono dei formati predefiniti
E’ tramite il meccanismo della maschera di formato che mostro la data 22/09/2002
come "domenica, 22 settembre 2002".
La sintassi per definire la maschera di formato è
praticamente identica a quella di Excel
Vediamo in dettaglio alcuni esempi
(attenzione i comportamenti delle maschere di formato in OOBase potrebbero cambiare a secondo della versione e della localizzazione).| Maschera (ACCESS) | Maschera (OOBase) | Valore | Risultato (ACCESS): | Risultato: (OOBase) | Osservazioni |
| g | G |
In ACCESS: #02/28/2009 08.00.00# In OOBase 28/02/2009 08.00.00 |
28 | 28 | giorno del mese con 0 iniziale se il giorno ha una sola cifra |
| gg | GG | 28 | 28 | ||
| ggg | NN - GGG | sab | sab | ||
| gggg | NNN - GGGG | sabato | sabato | ||
| m | M | 2 | 2 | ||
| mm | MM | 02 | 02 | numero del mese con 0 iniziale se il mese ha una sola cifra | |
| mmm | MMM | feb | feb | ||
| mmmm | MMMM | febbraio | febbraio | ||
| MMMMM | f | prima lettera del mese | |||
| a | 59 | giorno dell'anno | |||
| aa | AA | 09 | 09 | ||
| aaaa | AAAA | 2009 | 2009 | ||
| X | dC | specifica se prima o dopo Cristo | |||
| RR | dC2009 | specifica se prima o dopo Cristo seguito dall'anno | |||
| i | 6 | numero giorno della settimana (1 corrisponde a lunedì) | |||
| ii | WW | 9 | 9 | numero della settimana | |
| q | Q | 1 | T1 | trimestre | |
| 1o trimestre | |||||
| h | H | 8 | 8 | ||
| hh | HH | 08 | 08 | ora con uno 0 iniziale se l'ora ha una sola cifra | |
| n | M | 0 | 0 | ||
| nn | MM | 00 | 00 | minuti con uno 0 iniziale se i minuti hanno una sola cifra | |
| [MM] | 480 | Minuti trascorsi dall'inizio della giornata | |||
| s | S | 0 | 0 | ||
| ss | SS | 00 | 00 | secondi con uno 0 iniziale se i secondi hanno una sola cifra | |
| [SS] | 28800 | Secondi trascorsi dall'inizio della giornata | |||
| AM/PM | m. | OOBASE: visualizza p. per pomeriggio - m. per mattina | |||
| 0,00 | 0,00 | 39.872,33 | 39.872,33 | nr di giorni dalla data di riferimento + 1/3 di giorno |
| Formati data e ora applicati in modo erroneo a tipi numerici: | |||
| gg/mm/aaaa hh.nn.ss | 0 | "30/12/1899 00.00.00" | Access |
| 0,5 | "30/12/1899 12.00.00" | ||
| gg/mm/aaaa | -21 | "09/12/1899" | |
| GG/MM/AAAA HH.MM.SS | 0 | "01/01/1900 00.00.00" | OOBase |
| 0,5 | "01/01/1900 12.00.00" | ||
| GG/MM/AAAA | -21 | "11/12/1899" | |
Le sigle indicate nella precedente tabella possono essere combinate tra loro. Ad esempio con le seguenti maschere di formato, applicate alla data 6/2/2002 18.10.59, otteniamo:
| gg/mm/aaaa | è | 06/02/2002 |
| gg/mm/aaaa hh.nn.ss | è |
06/02/2002 |
| g/mmm/aa | è |
6/feb/02 |
| gggg | è |
mercoledì |
| gggg, g mmmm aaaa | è | mercoledì, 6 febbraio 2002 |
Il primo esempio corrisponde (in access) al formato predefinito “Data
in cifre”
Il secondo esempio corrisponde (in access) al formato predefinito “Data
generica”
Maschera di Input (Access):
impone dei vincoli sull’immissione dei dati. Le regole imposte da questa
proprietà garantiscono omogeneità nella digitazione dei dati ovvero impediscono
scritture differenti per indicare la stessa data (ad esempio il "2 gennaio 2002"
potrebbe essere scritto: 02/01/02, 02-01-02, 2 gennaio 2002, 2.1.2002, ...). Le diverse modalità di scrittura
accettate per rappresentare lo stesso valore determinano
maggior difficoltà nell'individuazione dell'informazione e portano ad uno
scadimento delle prestazioni durante le fasi di ricerca. I simboli utilizzati nelle maschere di input sono gli stessi presentati
con il tipo "Testo".
Vediamo alcuni esempi
di maschere di
input applicabili alle date:
| Simbolo | Risultato |
| 00/00/0000 |
devo digitare tutti i caratteri che compongono una data completando eventualmente il giorno ed il mese con uno 0 iniziale qualora fosse necessario |
| ##/##/#### |
posso anche non compilare la data ed inserire degli spazi al posto degli 0 iniziali |
Valore predefinito (Access - OOBase)
: ha lo stesso significato visto per i campi di tipo numerico.Ecco un esempio di inizializzazione per quanto riguarda OOBase:
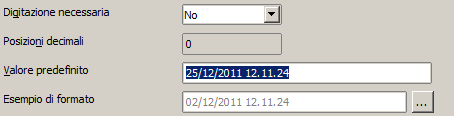
In OOBase non è possibile inizializzare la proprietà "Valore predefinito" con funzioni come avviene in ACCESS. Per far si che un campo venga alimentato automaticamente con la data e l'orario attuale occorre ricorrere ai comandi SQL:
ALTER TABLE "NomeTabella" ALTER COLUMN "NomeCampoTimeStamp" SET DEFAULT CURRENT_TIMESTAMP;| TIPO MEMO: |
Solitamente questo tipo è utilizzato per le note. Può contenere
fino a 64 mila caratteri (216) (anche in Access 2007/2010/2013!). Questo campo,
nella vecchia versione di Access 97, non poteva essere indicizzato e pertanto le ricerche al suo interno
risultavano lente
(sequenziali).
Le proprietà di questo tipo di campo sono simile a quelle viste per il tipo testo.
In OOBase il tipo equivalente al memo è LONGVARCHAR che è un sinonimo di VARCHAR senza dimensioni. Il numero massimo di caratteri accettati è 2.147.483.647 (231 byte - 2Gbyte).
|
TIPO Si/No (booleano) |
Viene
utilizzato quando si vuole memorizzare un'informazione che accetta al massimo
due valori. Ad esempio:
Esempio 1: per distinguere nella tabella CLIENTI quelli esteri da quelli nazionali posso creare un campo booleano "ITALIANO" che avrà il valore "No" (falso) per i clienti stranieri, "Si" (vero) per quelli italiani.
Esempio 2: per registrare il sesso nella tabella PAZIENTI posso costruire un
campo booleano "MASCHIO" che valorizzo a False se si tratta di una "femmina",
a True altrimenti.
In
molti casi il tipo booleano viene sostituito con un tipo numerico intero dove al
falso (false) faccio corrispondere lo 0 e al vero (true) qualsiasi valore diverso da
zero.
In OOBase il tipo equivalente è BOOLEAN che assume i valori "<senza>", "Si" e "No".
| Formati applicati in modo erroneo a tipi numerici: | |||
| Vero/Falso | 0 | Falso | Access |
| -21 | Vero | ||
| BOOLEAN | 0 | FALSO | OOBase |
| -1 | VERO | ||
| 0,5 | VERO | ||
| TIPO VALUTA: |
E’ un tipo numerico che utilizza le impostazione di valuta del sistema operativo ospitante (con Access corrisponde a quello definito nel pannello di controllo di WINDOWS).
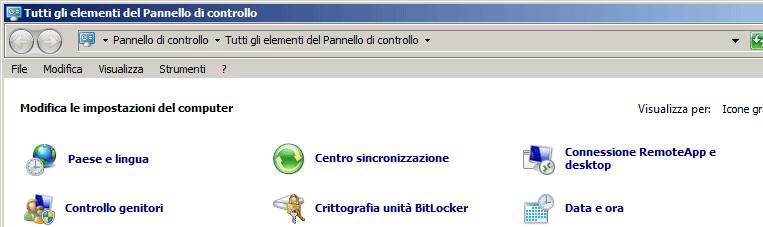
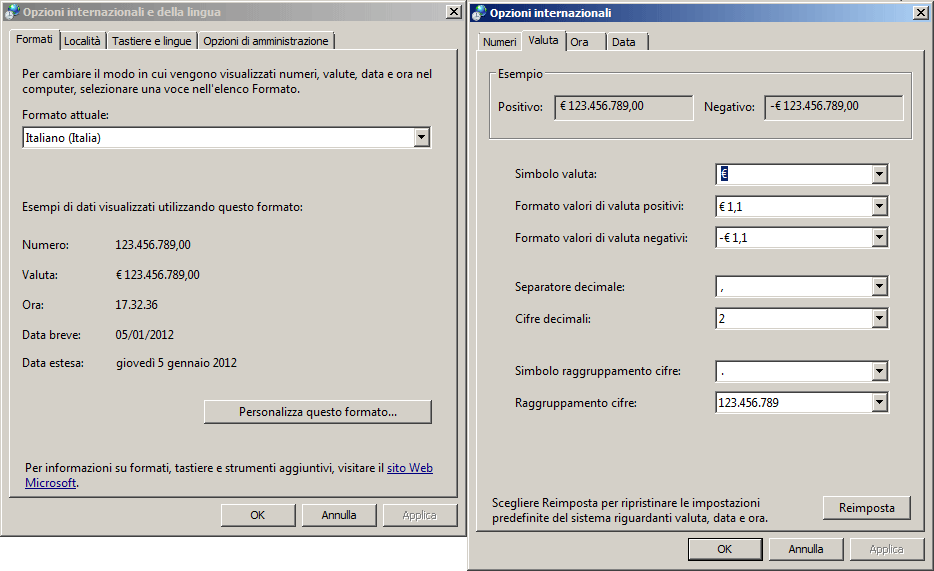
Cambiando le impostazioni di sistema cambia il modo con cui vengono visualizzati i valori registrati in questo tipo di dato. Se non si devono costruire applicazioni a diffusione internazionale è un tipo del tutto inutile.
In OOBase non esiste un tipo equivalente.
| TIPO OLE: |
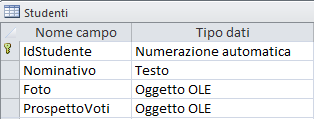
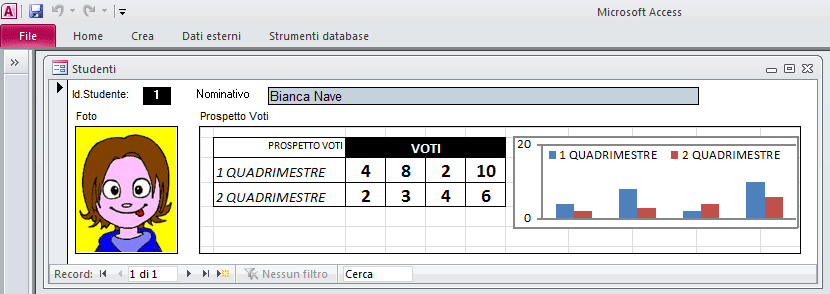
Questa tipologia di campo consente l'inserimento, all''interno del file di Access, di documenti prodotti con altre applicazioni (ad esempio un foglio di calcolo di Microsoft Excel, un documento di Microsoft Word, suoni o altri dati binari). Vediamo ora un esempio pratico.
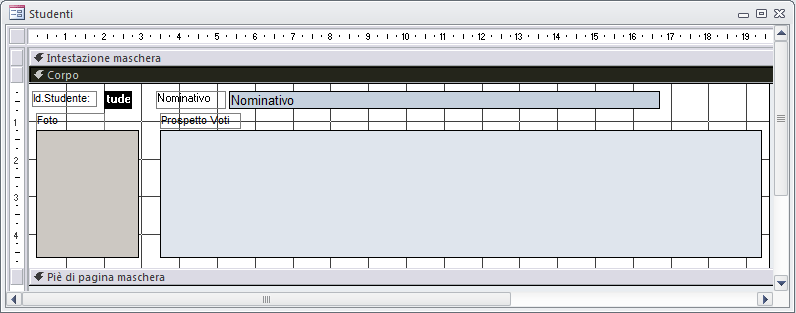
Ecco una struttura tabella contenente due campi di tipo OLE (Foto e ProspettoVoti)
La maschera (in "modalità struttura") utilizzata per alimentare questa tabella potrebbe apparire in questo modo
che in modalità "visualizzazione maschera" diventa:
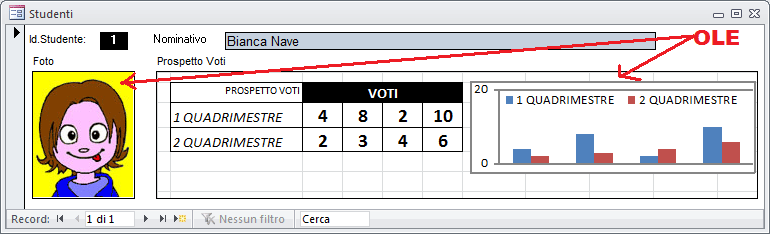
ATTENZIONE! - I campi OLE sono visibili sulla maschera solo se sul PC risultano installate le applicazioni utilizzate nella creazione dei documenti incorporati (nell'esempio Paint [foto] ed Excel [Prospetto voti]).
I campi OLE non sono direttamente visibili in modalità "Foglio Dati" ma occorre fare un doppio click sul campo che ci interessa consultare.
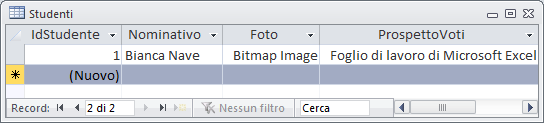
OLE (Object Linking and Embedding = collegamento ed incorporazione di oggetti) è una tecnologia per la creazione di documenti compositi sviluppata da Microsoft. La prima versione di OLE (rilasciata nel 1991) permetteva di integrare un documento creato con un'applicazione (detta server OLE) all'interno di un'altra applicazione (detta client OLE). Per superare i limiti della prima versione, nel 1993 fu rilasciato OLE 2, la cui principale caratteristica era la possibilità di modificare i documenti incorporati direttamente nell'applicazione ospitante. Durante la modifica dell'oggetto OLE il programma ospitante acquisisce la stessa interfaccia utente (menu, barre degli strumenti ecc.) dell'applicazione che è stata utilizzata per creare l'oggetto incorporato.
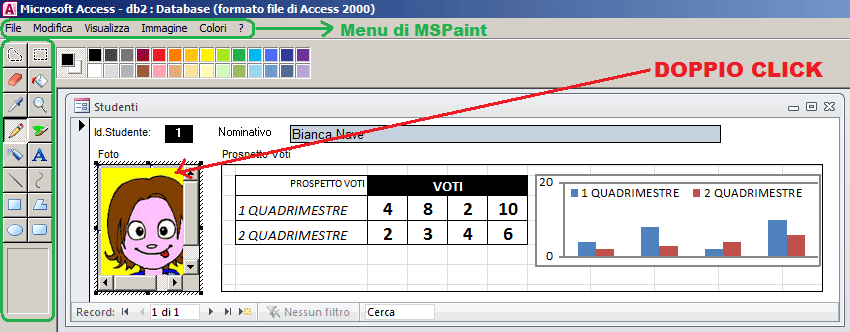
Esempio: se faccio doppio click sulla foto mi accorgo che i menu di Access acquisiscono l'aspetto tipico di microsoft paint (applicazione con cui ho creato l'immagine).
mentre se faccio doppio click sul prospetto dei voti noterò i menu tipici di Excel
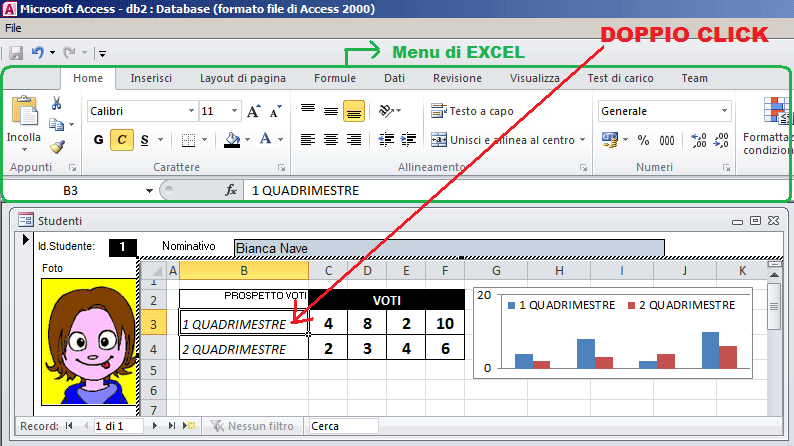
Quando non sto modificando un campo OLE i menu tornano ad essere quelli predefiniti di ACCESS.
Un'altra caratteristica di OLE 2 è la possibilità di spostare oggetti tra applicazioni diverse con il drag & drop.
OLE 2 è implementato con il
protocollo COM. COM è una tecnologia che permette di creare componenti software
riutilizzabili. In un certo senso COM permette di fare a livello di programmazione
ciò che OLE permette di fare a livello di documento. A livello software il
confine tra OLE e COM è quindi molto sfumato, ed infatti il nome OLE è spesso
usato per identificare tecnologie basate su COM che con lo scopo di OLE
(i documenti compositi) non hanno nulla a che fare.
COM è una tecnologia complessa e per i computer del 1993 era decisamente
pesante. Per questo i primi software che utilizzavano OLE 2 (Word 6 e Excel 5)
avevano delle prestazioni non proprio eclatanti. Con l'aumento della potenza di
calcolo COM e OLE sono diventate tecnologie molto diffuse nei sistemi Windows a
32 bit (ad esempio, Internet Explorer è un oggetto COM, ed è grazie ad OLE che
nella finestra del browser è possibile visualizzare e modificare un documento di
Word).
Sebbene COM abbia subito nel tempo una notevole evoluzione, OLE 2 è rimasto
fondamentalmente invariato, anche perché svolge al meglio il compito di creare
documenti compositi. Il futuro di COM è incerto, perché con l'introduzione della
piattaforma .NET Microsoft ha relegato questa tecnologia ad un ruolo di secondo
piano.
Un campo OLE può arrivare ad una dimensione di 1 GigaByte (purché vi sia spazio disco disponibile!). In Access l'uso di OLE come tipo di campo presenta due inconvenienti principali:
- Il contenuto non è leggibile se non ho installato il
software che ha generato il documento incorporato
- Il documento incorporato è salvato all'interno della tabella di access per
cui le dimensioni del file mdb/accdb possono crescere molto velocemente.
Esistono delle alternative al campo OLE:
·
Collegamento Ipertestuale: Si tratta di un campo testuale che può contenere fino a 2048 caratteri. Il contenuto viene utilizzato come un indirizzo di collegamento ipertestuale. Un indirizzo di collegamento ipertestuale può essere :
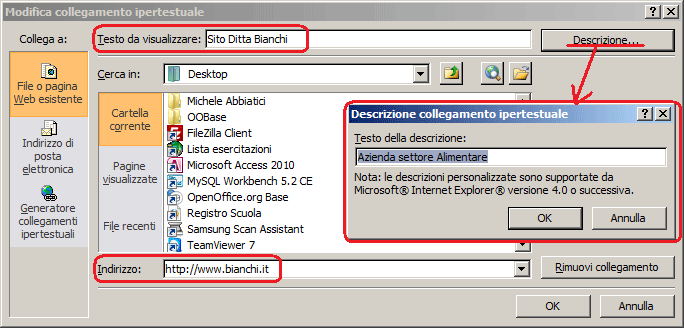
·
Allegato (è disponibile solo se il file di Access è stato salvato in formato 2007/2010/2013): Utilizzando questa tipologia è possibile allegare ai singoli record di una tabella immagini, fogli di calcolo, documenti, grafici e altri tipi di file supportati in una modalità simile a quella utilizzata per i messaggi di posta elettronica. È inoltre possibile visualizzare e modificare i file allegati, sulla base delle impostazioni definite per questo tipo di campo durante la progettazione del db. I campi Allegato offrono una maggiore flessibilità rispetto ai campi OLE ed utilizzano lo spazio di memorizzazione con maggiore efficienza poiché non incorporano l'allegato all'interno del campo.
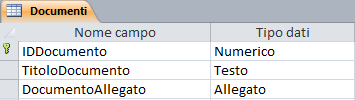
Quando sono in modalità "Foglio dati" con un doppio click sul campo "allegato" richiamo una finestra di dialogo che consente la definizione dei documenti da allegare
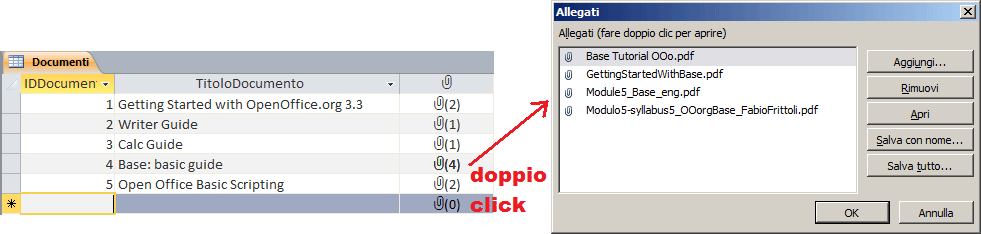
In modalità "Visualizza Maschera" i campi allegati appaiono con l'icona associata al documento allegato che in quel momento risulta attivo. Opportuni bottoni semitrasparenti permettono di scorrere i documenti allegati.
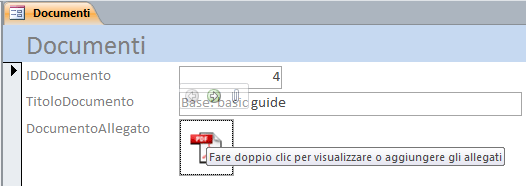
In OOBase i tipi di dato equivalenti sono:
·
BINARY: In generale questo tipo contiene una sequenza fissa di byte. La parte non utilizzata viene riempita con 0. In OOBase l'interfaccia grafica di definizione dei campi non fa alcuna differenza rispetto agli altri tipi binary. Infatti se utilizzo questo tipo la proprietà "lunghezza" rimane bloccata ed impostata a 2 Gbyte.
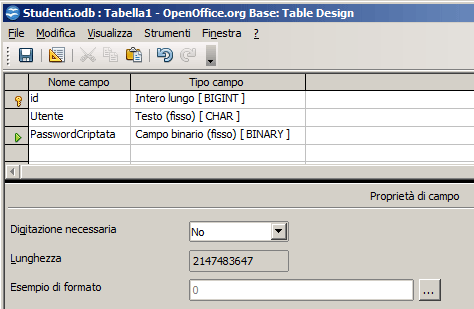
·
VARBINARY: Questo tipo contiene una sequenza di byte a lunghezza variabile. In OOBase l'interfaccia grafica di definizione dei campi non fa alcuna differenza rispetto al LONG VARBINARY. Infatti anche in questo caso la proprietà "lunghezza" risulta bloccata a 2.147.483.647 (2Gb) e non è accessibile.·
LONG VARBINARY: Contiene una sequenza di byte variabile fino a 2 Gbyte.·
OTHER: Contiene una sequenza di byte variabile fino a 2 Gbyte.| TIPO CAMPO RICERCA (Access): |
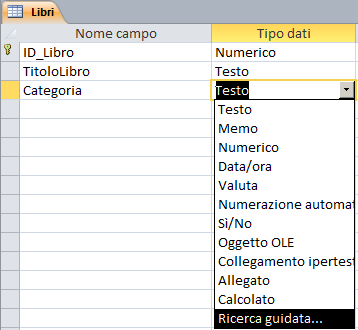
Questa tipologia non è un vero e proprio tipo ma attiva un meccanismo di autocomposizione che consente l'uso di un combobox/listbox come meccanismo di input.
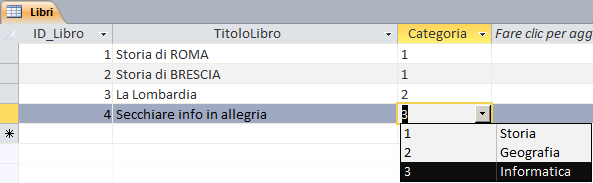
Selezionando questa tipologia si attiva la seguente maschera di autocomposizione:
 |
 |
In realtà il meccanismo del "campo ricerca" può essere implementato per qualsiasi tipo di campo ad esclusione di quelli automatici (contatore) e binari (OLE, Allegato ad esempio).
Vediamo come procedere:
1) Partendo dalla struttura della tabella clicchiamo sul campo per il quale si vuole creare l'elenco a discesa.
2) Nella parte bassa della maschera clicchiamo sul pannello "Ricerca"
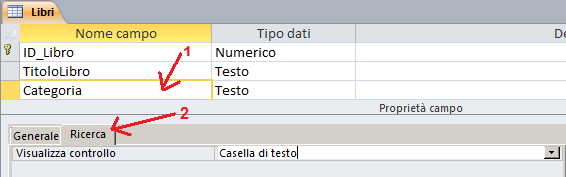
3) Compiliamo la prima proprietà presente nel pannello "Ricerca" in questo modo
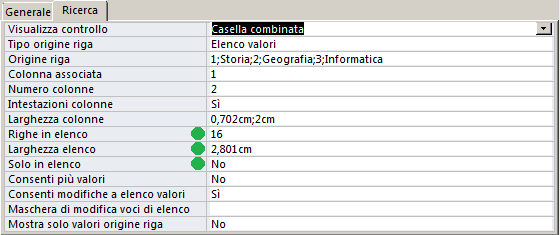
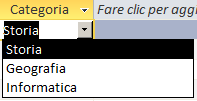
- Visualizza controllo: selezioniamo il tipo di controllo: "Casella di riepilogo"
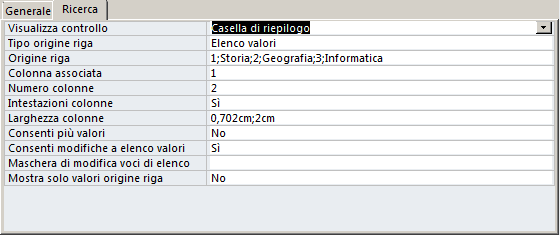
oppure "Casella combinata". Verranno mostrate le proprietà abbinate al controllo selezionato (i pallini verdi evidenziano quelle aggiuntive visualizzate quando seleziono "Casella combinata")
Se impostiamo "Visualizza controllo"
a "Casella di testo"
l'elenco a discesa non verrà visualizzato e il campo potrà essere compilato (in modalità "Foglio dati")
semplicemente digitando il valore nella cella abbinata.
-
Tipo origine riga: impostiamolo su "Elenco valori"
(ignoriamo
quindi le altre due possibilità: "Tabella/query" ed "Elenco campi").
-
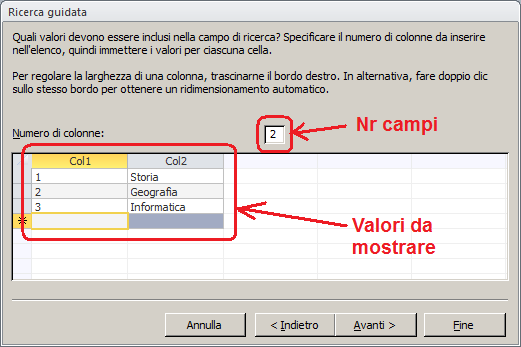
Origine riga: elenchiamo i valori da visualizzare separandoli con un
punto e virgola. Ad
esempio:
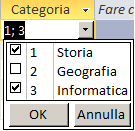
1;Storia;2;Geografia;3;Informatica. Se "Tipo origine riga" è
impostato su "Tabella/query" in questa proprietà viene
inserito un comando SQL di
selezione (ad esempio:
SELECT Matricola, Nominativo FROM Studenti).
-
Colonna associata: indica la colonna del combobox da cui viene estratto il valore da registrare
nel campo.
-
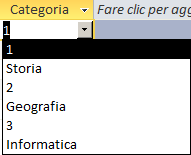
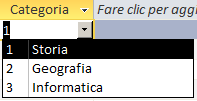
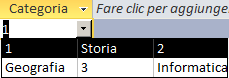
Numero colonne: indica il numero di colonne presenti nel combobox. L'elenco di
valori in "origine riga" verrà suddiviso in gruppi di "Numero
Colonne" elementi. Ogni gruppo verrà inserito su ciascuna riga del combobox.
|
Origine riga:"1;Storia;2;Geografia;3;Informatica" |
||
| Numero colonne = 1 | Numero colonne = 2 | Numero colonne = 3 |
 |
 |
 |
-
Larghezza elenco: indica la larghezza in cm. dell'elenco quando viene aperto
Larghezza elenco=
5,079 cm
Larghezza elenco=
2,801 cm
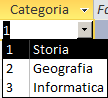
- Larghezza colonne: indica la larghezza di ciascuna colonna espressa in cm. Ponendo una larghezza a 0cm nascondo la colonna associata (utile per occultare gli id e mostrare solo il campo significativo). Ecco alcuni esempi:
| Larghezza colonne= 2,54 cm;2,54 cm |
Larghezza colonne= 0 cm;2,54 cm |
Larghezza colonne= 0,701cm;2,547cm |
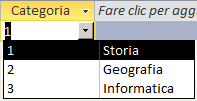 |
 |
|
-
Intestazione colonne: Se la imposto a "Si" il primo gruppo di "Origine riga" (composto da "Numero colonne" elementi) verrà usato per intitolare le colonne.| Origine valori= 1;Storia;2;Geografia;3;Informatica | Origine valori= Id.;Materia;1;Storia;2;Geografia;3;Informatica |
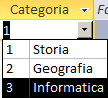 |
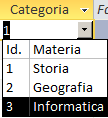 |
-
Consenti più valori (solo Access 2007/2010/2013): Se lo imposto a "Si"
potrò selezionare più righe. In questo caso il campo verrà trasformato in campo
testuale. Attenzione: una volta impostata questa proprietà a "Si" non è possibile ritornare
sul
"No".