POTENZIAMENTO - PARTE A
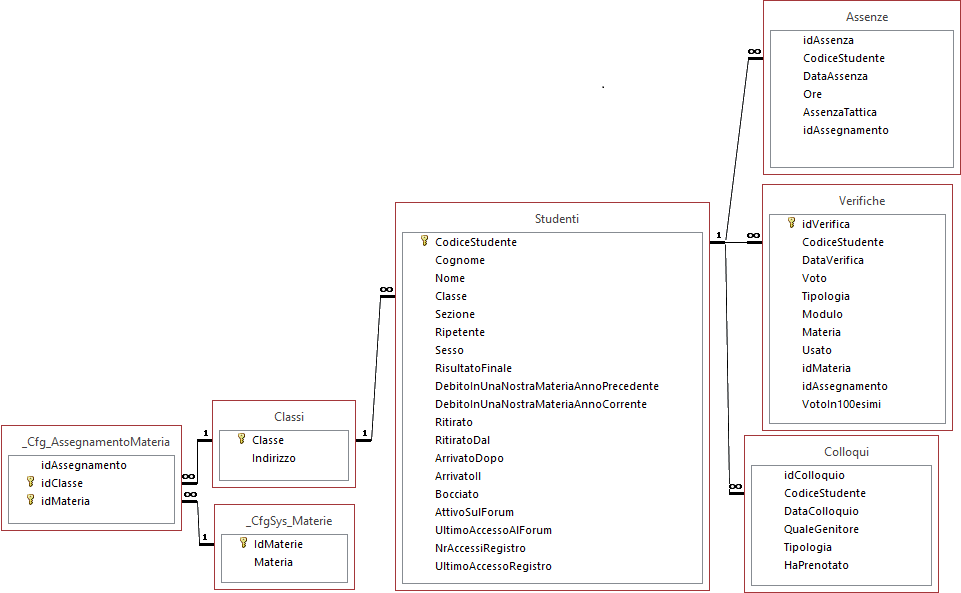
Scaricare il seguente file ZIP contenente le tabelle necessarie per l'esercitazione. La struttura del DB è la seguente:
dove:
- La tabella studenti
contiene i dati anagrafici dello studente. Il campo
booleano Ripetente contiene True se lo studente è stato bocciato l'anno precedente
mentre il campo booleano Bocciato contiene true se è stato bocciato l'anno corrente
(sarà compilato a fine anno!).
- La tabella assenze
contiene le assenze degli studenti. Attenzione: il campo DataAssenza
è testuale. Il campo AssenzaTattica è booleano ed indica se la data
dell'assenza coincide con una verifica. Il campo Ore ammette
come possibili valori: 1 (assenza
durante tutta l'ora di lezione) R
(ritardo) G (assenza
giustificata per altre attività scolastiche autorizzate)
A (uscita prima della fine dell'ora)
- La
tabella verifiche contiene i voti delle verifiche. Attenzione
il campo DataVerifica è testuale. Il campo modulo
è il numero identificativo dell'argomento (1 per il primo modulo, 2 per il
secondon modulo etc.). Il voto (che è un
campo testuale!) assume i seguenti valori: intero da
1.. 10 (se è una valutazione effettiva)
+ (bonus)
- (penalty)
* (controllo esercitazione)
M (nota di merito)
V (richiamo verbale)
S (ammonizione scritta:
nota sul registro). Il votoIn100esimi è un campo numerico di tipo
double che contiene la reale valutazione numerica con 2 cifre decimali della prova.
- La
tabella colloqui contiene le registrazioni dei colloqui. Il
campo DataColloquio è di tipo data/ora. Il campo HaPrenotato
è booleano ed è impostato a true se lo studente ha effettuato la prenotazione
tramite web. Il campo QualeGenitore contiene il genitore che è
venuto a colloquio ("Mamma", "Papà",
"Entrambe", "Altro:
...")
Si noti che all'interno del file di Access sono state definite le
seguenti funzioni:
Function Annata(Classe As String) As String Dim a As Byte If IsNumeric((Left(Classe, 1))) Then If (Left(Classe, 1) = "1") Then Annata = "prima" ElseIf (Left(Classe, 1) = "2") Then Annata = "seconda" ElseIf (Left(Classe, 1) = "3") Then Annata = "terza" ElseIf (Left(Classe, 1) = "4") Then Annata = "quarta" ElseIf (Left(Classe, 1) = "5") Then Annata = "quinta" Else Annata = "????" End If Else Annata = "????" End If End Function Function My_PrimaLetteraMaiuscola(s As String) As String My_PrimaLetteraMaiuscola = UCase(Left(s, 1)) & LCase(Mid(s, 2)) End Function Function Tassonomia(Voto, Optional Cosa As String = "Testo") As String Dim v As Double Dim TestoTassonomia As String Dim OrdineTassonomia As String If IsNumeric(Voto) Then v = CDbl(Voto) If (v >= 0 And v <= 2.5) Then TestoTassonomia = "Estremamente Insufficiente" OrdineTassonomia = "A" ElseIf (v > 2.5 And v <= 4.5) Then TestoTassonomia = "Gravemente Insufficiente" OrdineTassonomia = "B" ElseIf (v > 4.5 And v < 5.5) Then TestoTassonomia = "Insufficiente" OrdineTassonomia = "C" ElseIf (v > 5.5 And v < 6.5) Then TestoTassonomia = "Sufficiente" OrdineTassonomia = "D" ElseIf (v > 6.5 And v < 7.5) Then TestoTassonomia = "Discreto" OrdineTassonomia = "E" ElseIf (v > 7.5 And v < 8.5) Then TestoTassonomia = "Buono" OrdineTassonomia = "F" ElseIf (v > 8.5 And v <= 10) Then TestoTassonomia = "Eccellente" OrdineTassonomia = "G" Else TestoTassonomia = "NC" OrdineTassonomia = "Z" End If Else TestoTassonomia = "NC" OrdineTassonomia = "Z" End If If (Cosa = "Testo") Then Tassonomia = TestoTassonomia Else Tassonomia = OrdineTassonomia End If End Function
Attenzione: il file di access contiene già le funzioni qui elencate per cui non è necessario ricrearle
MYSQL: Stored Procedure equivalenti
-- -----------------------------------------------------
-- CREAZIONE FUNZIONI
-- -----------------------------------------------------
DROP FUNCTION IF EXISTS MeseInItaliano;
DELIMITER //
CREATE FUNCTION MeseInItaliano(Giorno DATE) RETURNS VARCHAR(15)
BEGIN
DECLARE NomeMese VARCHAR(15);
DECLARE mese INT;
SET mese=MONTH(Giorno);
if (mese=1) THEN
SET NomeMese='Gennaio';
elseif (mese=2) THEN
SET NomeMese='Febbraio';
elseif (mese=3) THEN
SET NomeMese='Marzo';
elseif (mese=4) THEN
SET NomeMese='Aprile';
elseif (mese=5) THEN
SET NomeMese='Maggio';
elseif (mese=6) THEN
SET NomeMese='Giugno';
elseif (mese=7) THEN
SET NomeMese='Luglio';
elseif (mese=8) THEN
SET NomeMese='Agosto';
elseif (mese=9) THEN
SET NomeMese='Settembre';
elseif (mese=10) THEN
SET NomeMese='Ottobre';
elseif (mese=11) THEN
SET NomeMese='Novembre';
elseif (mese=12) THEN
SET NomeMese='Dicembre';
end if;
RETURN NomeMese;
END //
DELIMITER ;
DROP FUNCTION IF EXISTS GiornoInItaliano;
DELIMITER //
CREATE FUNCTION GiornoInItaliano(Giorno DATE) RETURNS VARCHAR(15)
BEGIN
DECLARE NomeGiorno VARCHAR(15);
DECLARE GiornoW INT;
SET GiornoW=WEEKDAY(Giorno);
if (GiornoW=0) THEN
SET NomeGiorno='Lunedì';
elseif (GiornoW=1) THEN
SET NomeGiorno='Martedì';
elseif (GiornoW=2) THEN
SET NomeGiorno='Mercoledì';
elseif (GiornoW=3) THEN
SET NomeGiorno='Giovedì';
elseif (GiornoW=4) THEN
SET NomeGiorno='Venerdì';
elseif (GiornoW=5) THEN
SET NomeGiorno='Sabato';
elseif (GiornoW=6) THEN
SET NomeGiorno='Domenica';
end if;
RETURN NomeGiorno;
END //
DELIMITER ;
DROP FUNCTION IF EXISTS IsNumeric;
CREATE FUNCTION IsNumeric (sIn varchar(1024)) RETURNS tinyint
RETURN sIn REGEXP '^(-|\\+){0,1}([0-9]+\\.[0-9]*|[0-9]*\\.[0-9]+|[0-9]+)$';
DROP FUNCTION IF EXISTS My_PrimaLetteraMaiuscola;
CREATE FUNCTION My_PrimaLetteraMaiuscola (s varchar(1024)) RETURNS varchar(1024)
RETURN CONCAT(UCASE(LEFT(s,1)),LCASE(MID(s,2)));
DROP FUNCTION IF EXISTS Annata;
DELIMITER //
CREATE FUNCTION Annata(Classe VARCHAR(25)) RETURNS VARCHAR(10)
BEGIN
DECLARE Anno CHAR(1);
DECLARE frase VARCHAR(10);
SET Anno=LEFT(Classe,1);
IF (IsNumeric(Anno)) THEN
IF (Anno="1") THEN
SET frase = "prima";
ELSEIF (Anno="2") THEN
SET frase = "seconda";
ELSEIF (Anno="3") THEN
SET frase = "terza";
ELSEIF (Anno="4") THEN
SET frase = "quarta";
ELSEIF (Anno="5") THEN
SET frase = "quinta";
ELSE
SET frase = "?????";
END IF;
ELSE
SET frase = "?????";
END IF;
RETURN frase;
END //
DELIMITER ;
DROP FUNCTION IF EXISTS Tassonomia;
DELIMITER //
CREATE FUNCTION Tassonomia(Voto FLOAT, Cosa TEXT) RETURNS VARCHAR(50)
BEGIN
DECLARE Tassonomia VARCHAR(50);
DECLARE TestoTassonomia VARCHAR(50);
DECLARE OrdineTassonomia CHAR(1);
DECLARE v INT;
IF (IsNumeric(Voto)) THEN
SET v=CAST(Voto AS UNSIGNED);
If (v>=0 And v<=2.5 ) THEN
SET TestoTassonomia = "Estremamente Insufficiente";
SET OrdineTassonomia = "A";
ELSEIF (v > 2.5 And v <= 4.5) THEN
SET TestoTassonomia = "Gravemente Insufficiente";
SET OrdineTassonomia = "B";
ELSEIF (v > 4.5 And v < 5.5) THEN
SET TestoTassonomia = "Insufficiente";
SET OrdineTassonomia = "C";
ELSEIF (v > 5.5 And v < 6.5) THEN
SET TestoTassonomia = "Sufficiente";
SET OrdineTassonomia = "D";
ELSEIF (v > 6.5 And v < 7.5) THEN
SET TestoTassonomia = "Discreto";
SET OrdineTassonomia = "E";
ELSEIF (v > 7.5 And v < 8.5) THEN
SET TestoTassonomia = "Buono";
SET OrdineTassonomia = "F";
ELSEIF (v > 8.5 And v <= 10) THEN
SET TestoTassonomia = "Eccellente";
SET OrdineTassonomia = "G";
ELSE
SET TestoTassonomia = "NC";
SET OrdineTassonomia = "Z";
END IF;
ELSE
SET TestoTassonomia = "NC";
SET OrdineTassonomia = "Z";
END IF;
IF (Cosa = "Testo") THEN
SET Tassonomia = TestoTassonomia;
ELSE
SET Tassonomia = OrdineTassonomia;
END IF;
RETURN Tassonomia;
END //
DELIMITER ;
| ESERCIZIO 1 - IV-M2.5A.1 |
INTERPRETA CORRETTAMENTE I SEGUENTI COMANDI SQL SEMPLICI (in blu con ACCESS - in verde in MySQL):
as1)
SELECT
Cognome, Nome FROM Studenti
WHERE (Classe like "3*") AND (Sesso="F")
MYSQL:
SELECT
Cognome, Nome FROM Studenti
WHERE (Classe like "3%") AND (Sesso="F");
as2)
SELECT DataVerifica, Tipologia, Voto FROM Verifiche
WHERE DataVerifica Like "*/02/2014"
MYSQL:
SELECT DataVerifica, Tipologia, Voto FROM Verifiche
WHERE DataVerifica Like "%/02/2014";
as3)
SELECT * FROM Classi WHERE [Vuoi visualizzare tutte le
classi in elenco ?]='Si'
MYSQL: Nell'interfaccia testuale non è possibile valorizzare, durante l'esecuzione del comando SQL, una variabile pertanto la devo impostare manualmente nello script con il comando SET
SET @`Vuoi visualizzare tutte le
classi in elenco ?`='Si';
SELECT * FROM Classi WHERE @`Vuoi visualizzare
tutte le classi in elenco ?` = 'Si';
Oppure posso ricorrere ad una stored procedure a cui passo il parametro richiesto
DROP PROCEDURE IF EXISTS
Vuoi_visualizzare_tutte_le_classi_in_elenco;
DELIMITER //
CREATE PROCEDURE
Vuoi_visualizzare_tutte_le_classi_in_elenco(risposta VARCHAR(50))
BEGIN
SELECT * FROM Classi WHERE risposta = 'Si';
END //
DELIMITER ;
CALL
Vuoi_visualizzare_tutte_le_classi_in_elenco('Si');
CALL
Vuoi_visualizzare_tutte_le_classi_in_elenco('No');
as4)
SELECT Cognome & " " & Studenti.Nome AS Nominativo FROM
Studenti
WHERE Ripetente AND Bocciato
MYSQL:
SELECT CONCAT(Cognome," ",Studenti.Nome) AS Nominativo FROM
Studenti
WHERE Ripetente AND Bocciato;
as5)
SELECT Cognome FROM
Studenti
WHERE (Cognome Like "*U*") And ( (Cognome Like "D*") And (Cognome
Like "*I") );
MYSQL:
SELECT Cognome FROM
Studenti
WHERE (Cognome Like "%U%") And ( (Cognome Like "D%") And (Cognome
Like "%I") );
as6)
SELECT Cognome, Nome, [Di quale classe ?] AS Classe,
#03/01/2015# as [Stampato Il]
FROM Studenti WHERE [Di quale classe ?]=Classe
MYSQL: utilizzo una stored procedure a cui passo come parametro la classe
DROP PROCEDURE IF EXISTS
Di_Quale_Classe;
DELIMITER //
CREATE PROCEDURE Di_Quale_Classe(vClasse
VARCHAR(50))
BEGIN
SELECT Cognome, Nome, vClasse AS Classe,
STR_TO_DATE('03/01/2015','%m/%d/%Y') AS `Stampato Il`
FROM Studenti WHERE
Classe= vClasse;
END //
DELIMITER ;
CALL Di_Quale_Classe('3O');
as7)
SELECT DISTINCT
DataColloquio AS [Colloqui Generali] FROM Colloqui
WHERE
(tipologia="Quadrimestrale")
AND (DataColloquio>=#1/31/2014#) AND
(DataColloquio<=#06/08/2014#);
MYSQL:
SELECT DISTINCT DATE_FORMAT(DataColloquio,'%d/%m/%Y') AS
'Colloqui Generali' FROM Colloqui
WHERE
(Tipologia='Quadrimestrale')
AND ( DataColloquio>='2014-01-31' AND
DataColloquio<='2014-06-08' );
as8)
SELECT Classe, Cognome & " " & Nome As Nominativo, [Che
giorno è oggi ?] AS [Stampato Il]
FROM Studenti ORDER BY Classe, Cognome,
Nome;
MYSQL: Valorizzo una variabile con la data del giorno che desidero compaia in visualizzazione
SET @`Che giorno è oggi
?`='11/05/2015';
SELECT Classe, CONCAT(Cognome," ",Nome) As Nominativo, @`Che
giorno è oggi ?` AS `Stampato Il`
FROM Studenti ORDER BY Classe, Cognome,
Nome;
as9)
SELECT Cognome, Nome, NrAccessiRegistro FROM Studenti
WHERE (NrAccessiRegistro>20) AND (Bocciato OR Ripetente);
MYSQL:
SELECT Cognome, Nome, NrAccessiRegistro FROM Studenti
WHERE (NrAccessiRegistro>20) AND (Bocciato OR Ripetente);
as10)
SELECT Studenti.Cognome, Studenti.Nome,
Studenti.UltimoAccessoAlForum, Studenti.UltimoAccessoRegistro
FROM Studenti
Where ( (Studenti.UltimoAccessoAlForum - Studenti.UltimoAccessoRegistro)<=1
and (Studenti.UltimoAccessoAlForum - Studenti.UltimoAccessoRegistro)>=-1)
MYSQL:
SELECT Studenti.Cognome, Studenti.Nome,
Studenti.UltimoAccessoAlForum, Studenti.UltimoAccessoRegistro
FROM Studenti
WHERE ( TIMESTAMPDIFF(SECOND,Studenti.UltimoAccessoAlForum, UltimoAccessoRegistro)<=24*60*60
AND (TIMESTAMPDIFF(SECOND,UltimoAccessoAlForum,UltimoAccessoRegistro))>=-24*60*60);
| ESERCIZIO 2 - IV-M2.5A.2 |
INTERPRETARE CORRETTAMENTE I SEGUENTI COMANDI SQL SEMPLICI CONTENENTI ISTRUZIONI VBA:
bs1)
SELECT
Cognome, Nome FROM Studenti
WHERE (Left(Classe,1)>="3") AND (Sesso="F")
MYSQL:
SELECT
Cognome, Nome FROM Studenti
WHERE (Left(Classe,1)>="3") AND (Sesso="F");
bs2)
SELECT DataVerifica, Tipologia, Voto FROM Verifiche
WHERE (Format(CDate(DataVerifica),"mmyyyy")="022014")
ORDER BY
CDate(DataVerifica)
MYSQL:
SELECT DataVerifica, Tipologia, Voto
FROM Verifiche
WHERE
(DATE_FORMAT(STR_TO_DATE(DataVerifica,'%d/%m/%Y'),"%m%Y")="022014")
ORDER BY
STR_TO_DATE(DataVerifica,'%d/%m/%Y');
bs3)
SELECT TOP 1 CDate(DataVerifica) AS Giorno FROM
Verifiche
WHERE (Tipologia="Orale") AND (CByte(Voto)>5)
ORDER BY
CDate(DataVerifica)
MYSQL:
SELECT DataVerifica AS Giorno FROM
Verifiche
WHERE (Tipologia="Orale") AND (CONVERT(Voto,UNSIGNED)>5)
ORDER
BY STR_TO_DATE(DataVerifica,'%d/%m/%Y') LIMIT 1;
bs4)
SELECT DataVerifica,
Tipologia, Voto FROM Verifiche
WHERE Year(CDate(DataVerifica))=2014 AND
month(Cdate(DataVerifica))=2
ORDER BY CDate(DataVerifica);
MYSQL:
SELECT DataVerifica, Tipologia,
Voto FROM Verifiche
WHERE YEAR(STR_TO_DATE(DataVerifica,'%d/%m/%Y'))=2014
AND MONTH(STR_TO_DATE(DataVerifica,'%d/%m/%Y'))=2
ORDER BY
STR_TO_DATE(DataVerifica,'%d/%m/%Y');
bs5)
SELECT Cognome FROM Studenti
WHERE
Instr(Cognome,"U")>0 And ( Left(Cognome,1)="D" And Right(Cognome,1)="I" )
MYSQL:
SELECT Cognome FROM Studenti
WHERE
Instr(Cognome,"U")>0 And ( Left(Cognome,1)="D" And Right(Cognome,1)="I" );
bs6)
SELECT Cognome, Nome, [Di quale classe ?] AS Classe,
Now() AS [Stampato Il]
FROM Studenti WHERE [Di quale classe ?]=Classe;
MYSQL: Utilizzando una variabile valorizzata con il nome della classe da visualizzare possiamo fornire la seguente soluzione:
SET @`Di quale classe ?`='3O';
SELECT Cognome, Nome, @`Di quale classe ?` AS Classe
FROM Studenti WHERE
Classe=@`Di quale classe ?`;
Se il character set e la collation della tabella/campo risultano incompatibili con quelli impostati per la connessione (definiti nelle variabili: character_set_connection e collation_connection) possiamo avere il seguente errore:

infatti con il seguente comando posso verificare che il campo Classe e la variabile @`Di quale classe ?` hanno charset e collation differenti:
SET @`Di quale classe ?`='3O';
SELECT CharSet(Classe), Collation(Classe), CharSet(@`Di quale classe ?`),
Collation(@`Di quale classe ?`)
FROM Studenti LIMIT 1;

pertanto la query va riscritta nel seguente modo:
SET
character_set_connection='latin1';
SET @`Di quale classe ?`='4T';
SELECT
Cognome, Nome, Classe, DATE_FORMAT('2015-03-01','%m/%d/%Y') as `Stampato Il`
FROM Studenti WHERE Classe=@`Di quale classe ?`;
oppure:
SET @`Di quale classe ?`='4T';
SELECT Cognome, Nome, Classe, DATE_FORMAT('2015-03-01','%m/%d/%Y') as `Stampato
Il`
FROM Studenti WHERE Classe=CONVERT(@`Di quale classe ?` USING latin1)
COLLATE latin1_swedish_ci;
l'ultimo COLLATE è superfluo poichè latin1_swedish_ci è il default per il charset latin1 come si può verificare digitando il comando:
SHOW CHARACTER SET like 'latin1';
oppure:
SHOW CHARACTER SET WHERE CHARSET = 'latin1';
Approfondimento: I character set (insiemi di caratteri) sono tabelle che abbinano ai simboli visualizzabili su un computer un corrispondente valore binario. In ogni set di caratteri, una sequenza binaria corrisponde ad un carattere ben preciso. Di conseguenza, quando una stringa viene memorizzata utilizzando un certo set di caratteri, dovrà essere visualizzata attraverso quello stesso insieme, altrimenti alcuni caratteri potrebbero apparire diversi da come ce li aspettiamo. L’esempio classico di questo inconveniente si verifica in genere con le lettere accentate.
SELECT 'Latin1' AS `Set
Caratteri`, CONVERT('àìòùè áíóúé' USING latin1) AS Testo;
SELECT 'binary ' AS
`Set Caratteri`, CONVERT('àìòùè áíóúé' USING binary ) AS Testo;
MySQL, a partire dalla versione 4.1, ha introdotto un supporto
molto avanzato alla gestione dei character set. Infatti
ci consente di gestire i set di caratteri a livello di:
- server,
-
database,
- tabella
- singola colonna
- client e di connessione.
Ad ogni set di caratteri sono associate una o più "collation",
che rappresentano i modi possibili di confrontare le stringhe di caratteri
facenti parte di quel character set. Questo termine potrebbe essere tradotto con
l’italiano con "collazione" (termine arcaico ormai in
disuso sinonimo di "confronto").
Quindi una tabella che
utilizza character set "latin1"
(quello maggiormente usato in Europa Occidentale) e collation "latin1_general_cs"
avrà:
- un metodo di confronto non specifico per una determinata lingua
(adatto quindi a + idiomi)
- “case
sensitive” come indica la sigla “cs” finale, cioè tiene conto della
differenza fra maiuscole e minuscole nell’ordinare o confrontare le stringhe.
Normalmente l’esistenza di una collation dedicata ad una singola lingua si ha
quando le regole generali del set di caratteri non soddisfano le esigenze di
quella lingua.
In generale il nome di ogni
collation segue un determinato standard:
- inizia con il
nome del character set a cui si riferisce,
- comprende di
solito una specifica relativa alla lingua,
- termina con cs
(case sensitive) o ci (case insensitive) oppure con
bin quando il valore binario dei caratteri è utilizzato
direttamente per i confronti.
Quindi avremo ad esempio:
latin1_swedish_ci per la collation svedese case insensitive di
latin1,
latin1_german2_ci per la collation, sempre
case insensitive, basata sulle regole tedesche DIN-2,
utf8_bin
per la collation binaria della codifica utf8 (Unicode).
Ogni collation è legata a un solo set di caratteri! Le istruzioni SQL seguenti:
SHOW CHARACTER SET;
SHOW
COLLATION;
ci consentono di ottenere rispettivamente:
- la lista dei
set di caratteri (con la collation di default)
- la lista delle collation con
il set di caratteri associato
disponibili sul server.
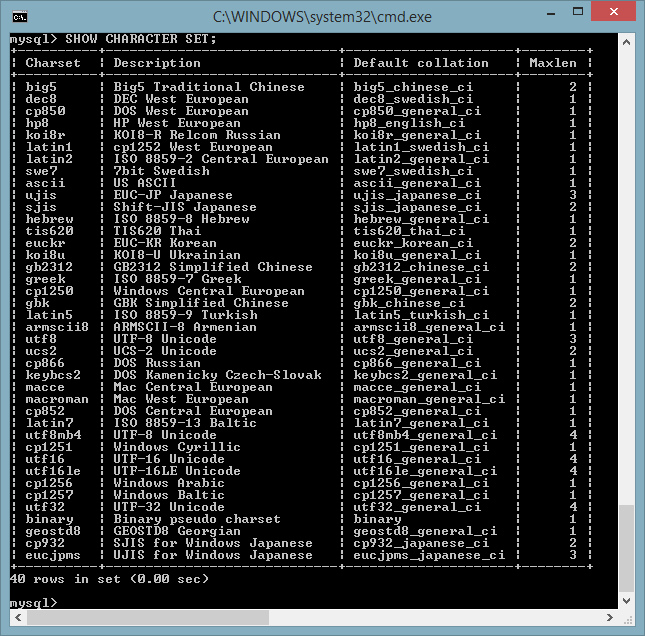
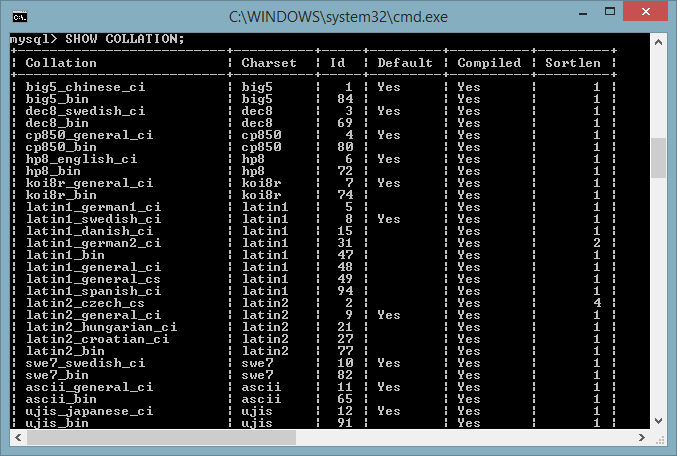
Come detto, MySQL gestisce character set e collation a diversi livelli: server, database, tabella, colonna. Parlando di dati, ovviamente ciò che è rilevante è quale character set viene utilizzato su ogni campo della singola tabellla di tipo CHAR, VARCHAR o TEXT. Tutti i charset definiti nei livelli superiori (server, database, tabella) hanno il solo scopo di definire il valore di default per il rispettivo livello inferiore.
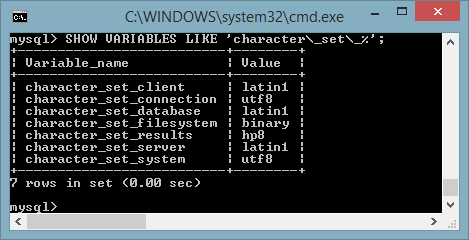
I set di caratteri gestiti a livello di server, database, tabella, singola colonna (o campo), client e di connessione sono visualizzabili con il seguente comando:
SHOW VARIABLES LIKE 'character\_set\_%';
Possiamo impostare il character set nelle variabili character_set_client, character_set_results e character_set_connection utilizzando questo singolo comando:
SET NAMES 'nome charset';
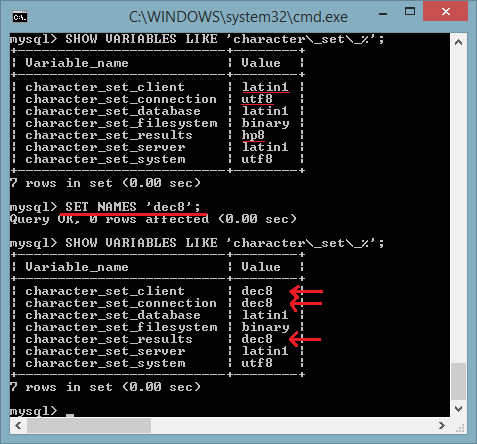
per cui equivale a:
SET character_set_client =
'nome charset';
SET character_set_results = 'nome charset';
SET
character_set_connection = 'nome charset';
In alternativa si poteva utilizzare anche il comando SQL:
SET CHARACTER SET 'nome charset';
che però è equivalente alla seguente sequenza di comandi:
SET character_set_client =
'nome charset';
SET character_set_results = 'nome charset';
SET
collation_connection = @@collation_database;
Quando un client si connette ad un server MySQL spedisce il nome del set di caratteri che intende utilizzare. Il server imposta automaticamente le variabili character_set_client, character_set_results e character_set_connection a quel set di caratteri (esegue sostanzialmente un SET NAMES su quel set di caratteri). Quando un client richiede l'esecuzione di un comando SQL, come SELECT Colonna1 FROM Tabella, il server restituisce i valori contenuti nel campo Colonna1 utilizzando il set di caratteri che il client ha specificato quando si è connesso. La conversione potrebbe determinare delle perdite se ci sono caratteri non definiti nei charset coinvolti.
Le variabili di sistema character_set_client e character_set_results rappresentano, rispettivamente, il charset delle istruzioni in arrivo dal client e quello che sarà utilizzato per spedire le risposte.
Il comando SQL successivo mostra invece come la variabile character_set_database acquisisca in automantico il character set del db in uso
-- Creo un DB impostando un
character set opportuno
CREATE DATABASE db1_buttare CHARACTER SET ucs2;
--
Visualizzo le variabili relative al charset
SHOW VARIABLES LIKE
'character\_set\_%';
USE DB1_Buttare; -- Cambio DB di default
-- Verifico
che la character_set_database e' cambiata
SHOW VARIABLES LIKE 'character\_set\_%';
DROP DATABASE
DB1_Buttare;
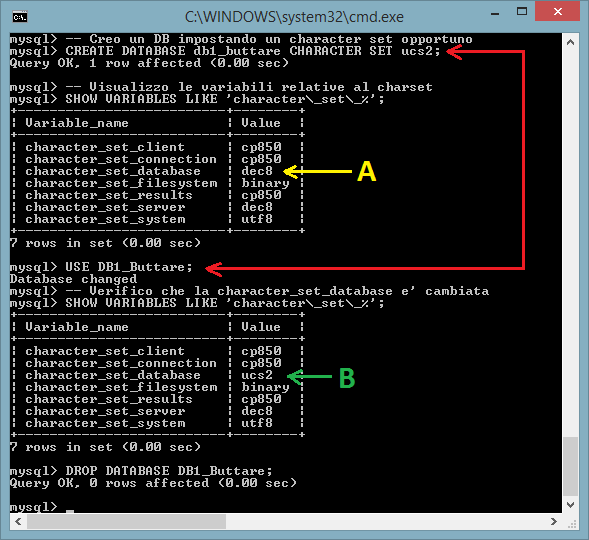
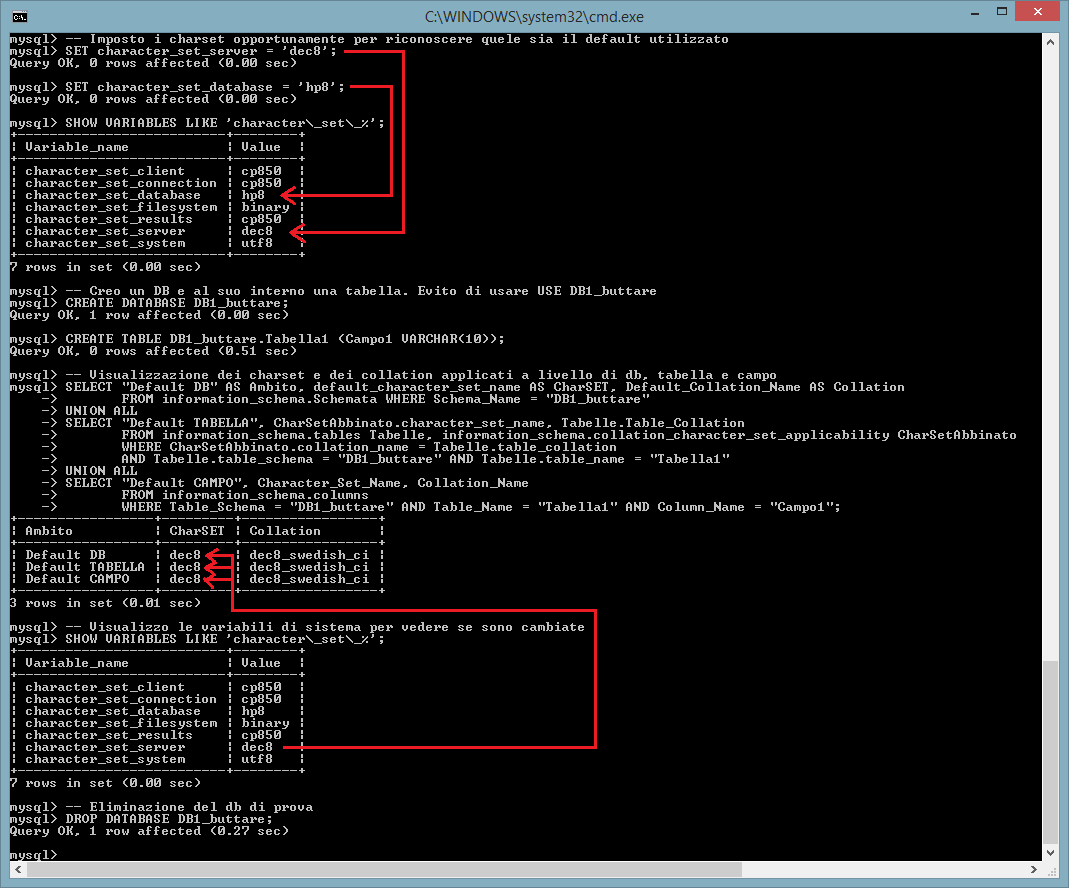
Il comando SQL successivo mostra quale charset venga utilizzato come default a livello di db, tabella e colonna:
-- Imposto i charset
opportunamente per riconoscere quele sia il default utilizzato
SET
character_set_server = 'dec8';
SET character_set_database = 'hp8';
SHOW
VARIABLES LIKE 'character\_set\_%';
-- Creo un DB e al suo interno una
tabella. Evito di usare USE DB1_buttare
CREATE DATABASE DB1_buttare;
CREATE TABLE DB1_buttare.Tabella1 (Campo1 VARCHAR(10));
-- Visualizzazione
dei charset e dei collation applicati a livello di db, tabella e campo
SELECT
"Default DB" AS Ambito, default_character_set_name AS CharSET,
Default_Collation_Name AS Collation
FROM
information_schema.Schemata WHERE Schema_Name = "DB1_buttare"
UNION ALL
SELECT "Default TABELLA",
CharSetAbbinato.character_set_name, Tabelle.Table_Collation
FROM information_schema.tables Tabelle,
information_schema.collation_character_set_applicability CharSetAbbinato
WHERE CharSetAbbinato.collation_name = Tabelle.table_collation
AND Tabelle.table_schema = "DB1_buttare" AND Tabelle.table_name = "Tabella1"
UNION ALL
SELECT "Default CAMPO", Character_Set_Name, Collation_Name
FROM information_schema.columns
WHERE
Table_Schema = "DB1_buttare" AND Table_Name = "Tabella1" AND Column_Name =
"Campo1";
-- Visualizzo le variabili di sistema per vedere se sono cambiate
SHOW VARIABLES LIKE 'character\_set\_%';
-- Eliminazione del db di prova
DROP DATABASE
DB1_buttare;
Dall'output noto che il charset di default utilizzato è quello indicato nella variabile character_set_server.
Non indicare il character set o la collation durante la creazione di un DB comporta quindi l'utilizzo delle impostazioni a livello di server (variabile character_set_server ). Non indicare il character set o la collation durante la creazione di una tabella comporta l'utilizzo delle impostazioni del DB contenitore mentre non indicare il character set o la collation durante la creazione di un campo comporta l'utilizzo delle impostazioni della tabella associata. Lo si può verificare guardando i 2 successivi esempi.
Nel primo esempio si nota che quando creo un DB senza indicare ne charset ne collation allora le impostazioni nelle variabili character_set_server e collation_server vengano utilizzate per stabilire il collation e il charset da applicare (come del resto già precisato precedentemente). Qualora nella creazione del DB venga definito il charset allora la collation utilizzata è quella predefinita per quel charset (i default sono visibili con il comando: SHOW COLLATION WHERE `Default` = 'Yes';). Analogamente se creo una tabella senza indicare il charset all'interno di un db questa eredita il il charset e la collation del db contenitore. Lo stesso vale per il campo: se definisco un campo all'interno di una tabella questa assume il charset e la collation della tabella stesssa.
-- Controllo il collation
predefinito per ucs2 ed imposto il charset e il collation di default
SET character_set_server = 'ucs2';
SET collation_server='ucs2_icelandic_ci';
-- Creazione del primo DB senza
charset
CREATE DATABASE DB_UsaDefault;
CREATE TABLE
DB_UsaDefault.Tabella_UsaDefault (
Campo_UsaDefault VARCHAR(10),
Campo_UsaUCS2 VARCHAR(10)
CHARACTER SET ucs2);
CREATE TABLE DB_UsaDefault.Tabella_UsaUCS2 (
Campo_UsaDefault VARCHAR(10),
Campo_UsaUCS2 VARCHAR(10)
CHARACTER SET ucs2) CHARACTER SET ucs2;
-- Creazione del secondo DB con
charset impostato
CREATE DATABASE DB_UsaUCS2 CHARACTER SET ucs2;
CREATE
TABLE DB_UsaUCS2.Tabella_UsaDefault (
Campo_UsaDefault VARCHAR(10),
Campo_UsaUCS2 VARCHAR(10)
CHARACTER SET ucs2);
CREATE TABLE DB_UsaUCS2.Tabella_UsaUCS2 (
Campo_UsaDefault VARCHAR(10),
Campo_UsaUCS2 VARCHAR(10)
CHARACTER SET ucs2) CHARACTER SET ucs2;
-- Visualizzo il charset e il collation applicati
SHOW
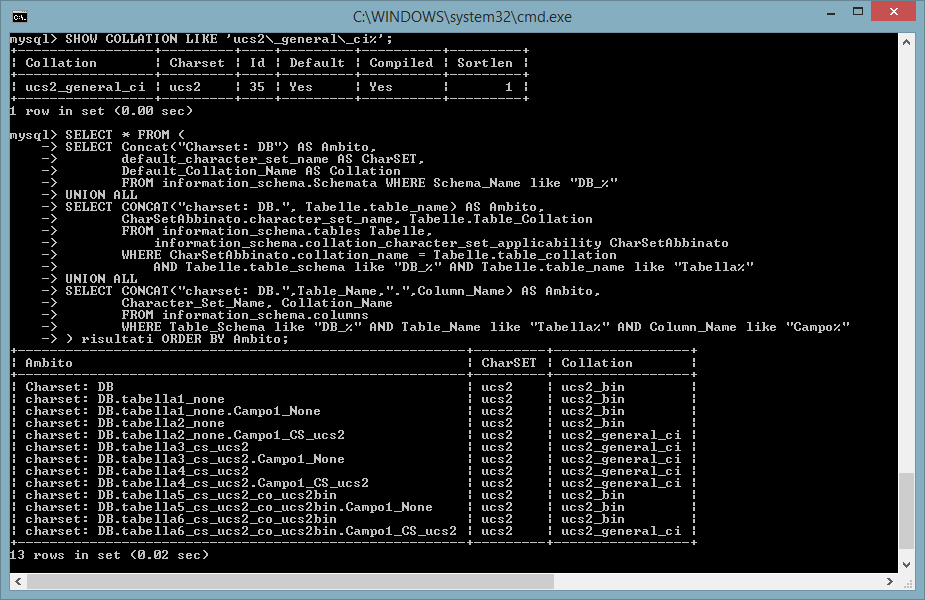
COLLATION LIKE 'ucs2\_general\_ci%';
SELECT * FROM (
SELECT Concat("Charset: ",Schema_Name) AS Ambito,
default_character_set_name AS CharSET,
Default_Collation_Name AS Collation
FROM
information_schema.Schemata WHERE Schema_Name like "DB_Usa%"
UNION ALL
SELECT CONCAT("charset: ",Tabelle.table_schema,".", Tabelle.table_name),
CharSetAbbinato.character_set_name, Tabelle.Table_Collation
FROM information_schema.tables Tabelle,
information_schema.collation_character_set_applicability CharSetAbbinato
WHERE CharSetAbbinato.collation_name = Tabelle.table_collation
AND Tabelle.table_schema like "DB_Usa%" AND Tabelle.table_name like "Tabella%"
UNION ALL
SELECT CONCAT("charset: ",Table_Schema,
".",Table_Name,".",Column_Name),
Character_Set_Name, Collation_Name
FROM
information_schema.columns
WHERE Table_Schema like "DB_Usa%" AND Table_Name like "Tabella%" AND Column_Name
like "Campo%"
) Risultati ORDER BY Ambito;
-- Elimino i db di prova
DROP DATABASE DB_UsaDefault;
DROP DATABASE DB_UsaUCS2;
Osservando l'output della sequenza SQL osserviamo che la
collation
ucs2_icelandic_ci definita nella variabile
collation_server è stata utilizzata solo quando:
- il db non ha
indicazioni sul charset da utilizzare
- la tabella non ha indicazioni sul
charset da utilizzare e neppure il db che la contiene (eredito le impostazioni
del db contenitore)
- il campo non ha
indicazioni sul charset da utilizzare e neppure il db ne la tabella dove è
definito (eredito le impostazioni della tabella associata)
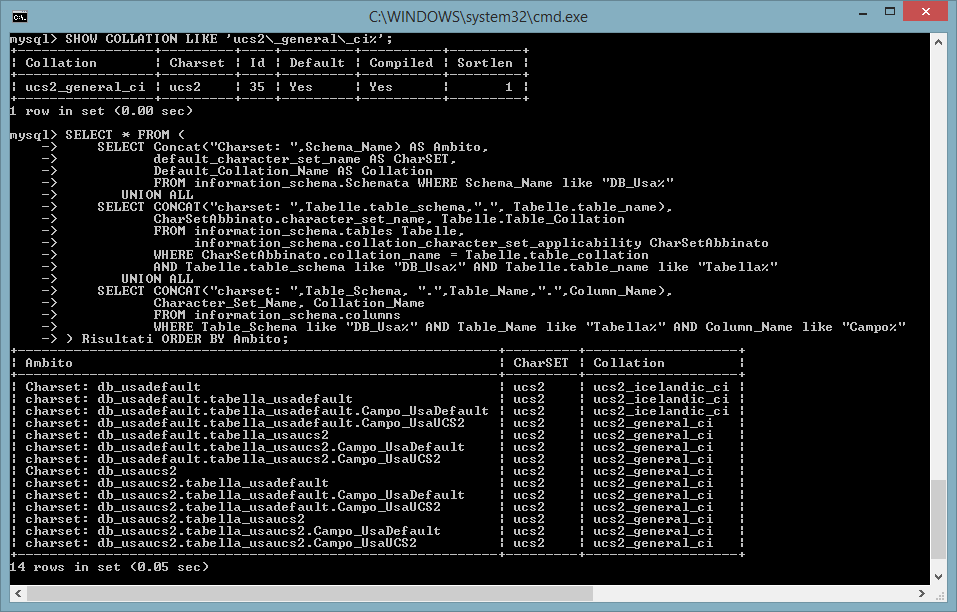
Nel secondo esempio la sequenza dei comandi SQL mostra come personalizzare la collation a livello di db, tabella e colonna:
-- Creazione del db e delle
tabelle con tute le combinazioni di COLLATE
CREATE DATABASE DB1_buttare
CHARACTER SET ucs2 COLLATE ucs2_bin;
CREATE TABLE DB1_buttare.Tabella1_None
(Campo1_None VARCHAR(10));
CREATE TABLE DB1_buttare.Tabella2_None
(Campo1_CS_ucs2 VARCHAR(10) CHARACTER SET ucs2);
CREATE TABLE
DB1_buttare.Tabella3_CS_ucs2 (Campo1_None VARCHAR(10)) CHARACTER SET ucs2;
CREATE TABLE DB1_buttare.Tabella4_CS_ucs2 (Campo1_CS_ucs2 VARCHAR(10) CHARACTER
SET ucs2) CHARACTER SET ucs2;
CREATE TABLE
DB1_buttare.Tabella5_CS_ucs2_CO_ucs2bin (Campo1_None VARCHAR(10)) CHARACTER SET
ucs2 COLLATE ucs2_bin;
CREATE TABLE DB1_buttare.Tabella6_CS_ucs2_CO_ucs2bin
(Campo1_CS_ucs2 VARCHAR(10) CHARACTER SET ucs2) CHARACTER SET ucs2 COLLATE
ucs2_bin;
-- Mostro il collation predefinito di ucs2
SHOW COLLATION LIKE
'ucs2\_general\_ci%';
SELECT * FROM (
SELECT Concat("Charset: DB") AS Ambito, default_character_set_name AS CharSET,
Default_Collation_Name AS Collation
FROM information_schema.Schemata WHERE Schema_Name like "DB_%"
UNION ALL
SELECT
CONCAT("charset: DB.", Tabelle.table_name) AS Ambito,
CharSetAbbinato.character_set_name, Tabelle.Table_Collation
FROM information_schema.tables Tabelle,
information_schema.collation_character_set_applicability CharSetAbbinato
WHERE CharSetAbbinato.collation_name = Tabelle.table_collation
AND Tabelle.table_schema like "DB_%" AND Tabelle.table_name like "Tabella%"
UNION ALL
SELECT
CONCAT("charset: DB.",Table_Name,".",Column_Name) AS Ambito, Character_Set_Name,
Collation_Name
FROM information_schema.columns
WHERE Table_Schema like "DB_%" AND Table_Name like "Tabella%" AND Column_Name
like "Campo%"
) risultati ORDER BY Ambito;
DROP DATABASE DB1_buttare;
Si osservi che la collation ucs2_bin, assegnata al DB, viene utilizzata tutte le volte in cui nel comando di creazione non viene citato uno specifico charset. Quando invece viene indicato il charset ucs2 allora la collation che viene utilizzata è ucs2_general_ci ovvero quella predefinita per ucs2.
Per concludere un comando che mostra le collation utilizzate in caso di costanti, funzioni, campi ...
-- Imposto i charset
opportunamente per riconoscerli
SET character_set_client ='dec8';
SET
character_set_connection ='hp8';
SET character_set_results ='ascii';
SET
character_set_database = 'latin1';
SET character_set_server = 'latin2';
--
Creo il DB ed una tabella con un record
CREATE DATABASE DB1_buttare CHARACTER
SET latin1 COLLATE latin1_danish_ci ;
CREATE TABLE DB1_buttare.Tabella1
(Campo1 VARCHAR(10), CAMPO2 INT);
INSERT INTO
DB1_buttare.Tabella1(Campo1,Campo2) VALUES ('Marco',1);
-- Mostro i collation
utilizzati in diverse casistiche
SET @`Che nome hai ?`="Marco";
SET
@`Quanti anni hai ?`=18;
SELECT 'Costante Testo' AS Tipo, COLLATION('Si') AS
`Collate usato` UNION ALL
SELECT 'Costante Numero' AS Tipo, COLLATION(100) AS
`Collate usato` UNION ALL
SELECT 'Variabile stringa', COLLATION(@`Che nome
hai ?`) UNION ALL
SELECT 'Variabile numerica', COLLATION(@`Quanti anni hai
?`) UNION ALL
SELECT 'Variabile (non definita)', COLLATION(@VarNonDefinita)
UNION ALL
-- LAST_INSERT_ID(), SCHEMA(), CONNECTION_ID(), USER() ...
SELECT 'Information Function()', COLLATION(VERSION()) UNION ALL
SELECT
'Funzione() Stringa', COLLATION(SPACE(3)) UNION ALL
SELECT 'Funzione()
binaria', COLLATION(SYSDATE()) UNION ALL
(SELECT 'Campo Testuale',
COLLATION(Campo1) FROM DB1_buttare.Tabella1 LIMIT 1) UNION ALL
(SELECT 'Campo
Numerico', COLLATION(Campo2) FROM DB1_buttare.Tabella1 LIMIT 1);
show
variables like 'character\_set\_%';
show variables like 'coll%';
DROP
DATABASE DB1_buttare;
Si osservi che le variabili, le costanti e i campi non testuali vengono associate ad un collate binary. Le funzioni informative (BENCHMARK(), CHARSET(), COERCIBILITY(), COLLATION(), CONNECTION_ID(), CURRENT_USER(), DATABASE(), FOUND_ROWS(), LAST_INSERT_ID(), ROW_COUNT(), SCHEMA(), SESSION_USER(), SYSTEM_USER(), USER(), VERSION() ) restituiscono il charset e la collation del sistema (variabile: character_set_system). Costanti, variabili e funzioni testuali utilizzano il charset e la collation di connessione (variabile: character_set_connection e collate_connection).
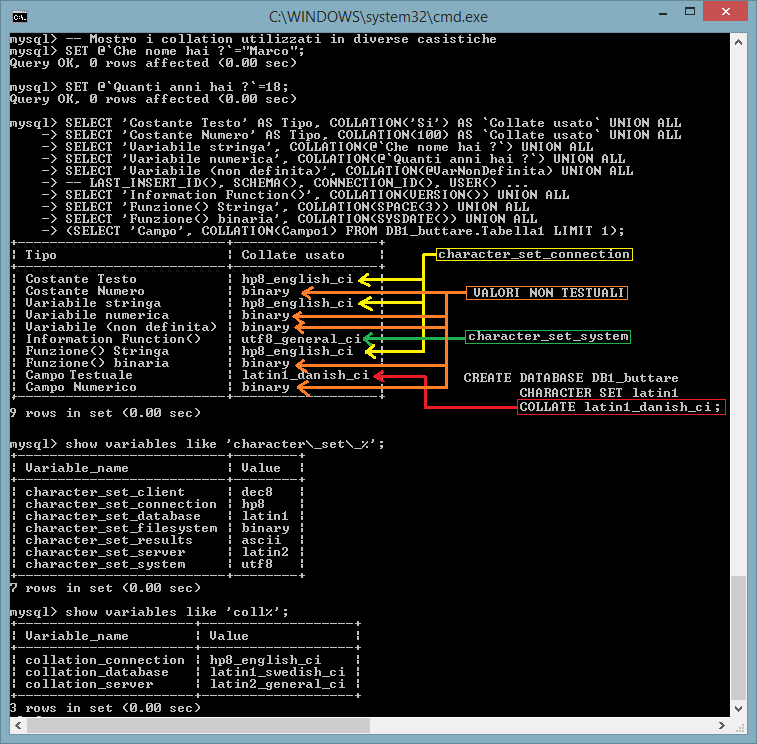
Quindi character_set_connection e collation_connection sono utilizzate dal server per convertire le istruzioni ricevute e fare confronti fra valori di tipo stringa.
bs7)
SELECT * FROM Classi
WHERE Indirizzo=IIf([Digita 1
per Classi Area Scientifica 2 Scienze Applicate ?]=1,"Scientifica","Scienze
Applicate");
MYSQL: utilizzando una prepared statement:
PREPARE stmt FROM 'SELECT *
FROM Classi WHERE Indirizzo=If(?=1,"Scientifica","Scienze Applicate")';
SET
@`Digita 1 per Classi Area Scientifica 2 Scienze Applicate ?`=1;
EXECUTE stmt
USING @`Digita 1 per Classi Area Scientifica 2 Scienze Applicate ?`;
SET
@`Digita 1 per Classi Area Scientifica 2 Scienze Applicate ?`=2;
EXECUTE stmt
USING @`Digita 1 per Classi Area Scientifica 2 Scienze Applicate ?`;
DEALLOCATE PREPARE stmt;
bs8)
SELECT
Ucase(Left(Cognome,1)) & Lcase(mid(Cognome,2)) & " " & Ucase(Nome) AS Nominativo
FROM Studenti ORDER BY COGNOME, Nome;
MYSQL:
SELECT
CONCAT(Ucase(Left(Cognome,1)),Lcase(mid(Cognome,2))," ",Ucase(Nome)) AS Nominativo
FROM Studenti ORDER BY COGNOME, Nome;
bs9)
SELECT Cognome & " " & Nome & " frequenta la classe " &
Annata(Classe)
& " sezione " & right(Classe,1) FROM Studenti
ORDER BY
Cognome, Nome
MYSQL:
SELECT CONCAT(Cognome," ",Nome,"
frequenta la classe ",
CAST(Annata(Classe) AS CHAR CHARACTER SET UTF8),"
sezione ",right(Classe,1)) FROM Studenti
ORDER BY Cognome, Nome;
bs10)
SELECT Cognome, Nome,
My_PrimaLetteraMaiuscola
(
IIf(IsDate(ArrivatoIl),
"è arrivato " & format(ArrivatoIl,"dddd, d mmmm yyyy"),
""
) &
IIf(IsDate(RitiratoDal) and IsDate(ArrivatoIl)," e ","") &
IIf(IsDate(RitiratoDal),
"si è
ritirato " & format(RitiratoDal,"dddd, d mmmm yyyy"),
""
)
) AS [Ritirati o Iscritti
dopo]
FROM Studenti
WHERE ( IsDate(RitiratoDal) OR IsDate(ArrivatoIl) )
ORDER BY IIf(IsDate(ArrivatoIl),ArrivatoIl,RitiratoDal);
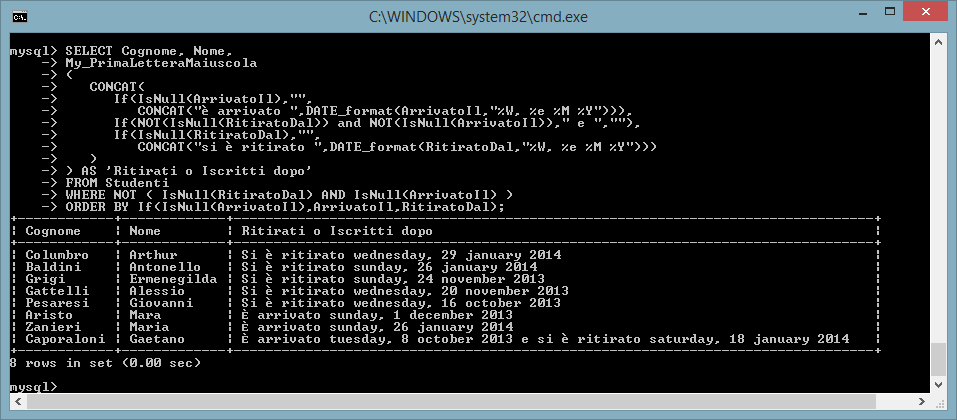
MYSQL:
SELECT Cognome, Nome,
My_PrimaLetteraMaiuscola
(
CONCAT(
If(IsNull(ArrivatoIl),"",
CONCAT("è arrivato ",DATE_format(ArrivatoIl,"%W, %e
%M %Y"))),
If(NOT(IsNull(RitiratoDal)) and
NOT(IsNull(ArrivatoIl))," e ",""),
If(IsNull(RitiratoDal),"",
CONCAT("si è ritirato
",DATE_format(RitiratoDal,"%W, %e %M %Y")))
)
) AS 'Ritirati o Iscritti dopo'
FROM Studenti
WHERE NOT (
IsNull(RitiratoDal) AND IsNull(ArrivatoIl) )
ORDER BY
If(IsNull(ArrivatoIl),ArrivatoIl,RitiratoDal);
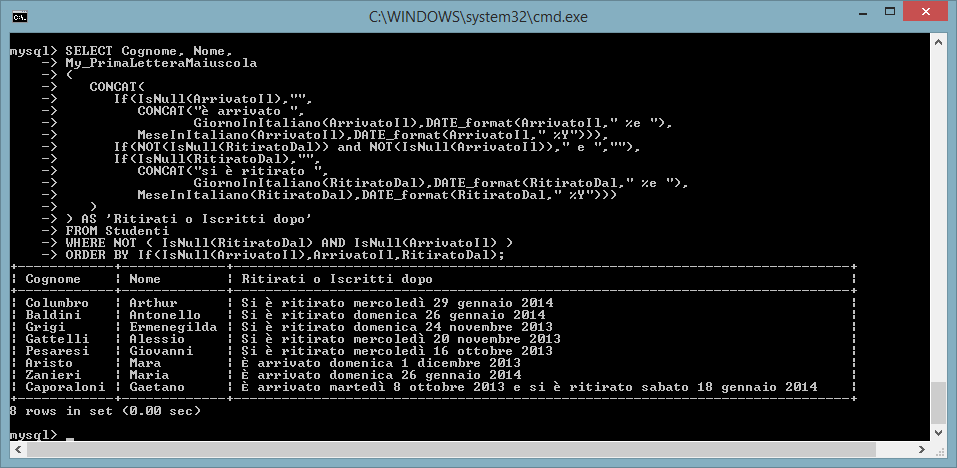
Per ottenere l'elenco con i nomi in italiano possiamo sfruttare le funzioni MeseInItaliano() e GiornoInItaliano() che sono state definite all'interno del nostro db DATISTUDENTE
SELECT Cognome, Nome,
My_PrimaLetteraMaiuscola
(
CONCAT(
If(IsNull(ArrivatoIl),"",
CONCAT("è arrivato ",
GiornoInItaliano(ArrivatoIl),DATE_format(ArrivatoIl," %e "),
MeseInItaliano(ArrivatoIl),DATE_format(ArrivatoIl," %Y"))),
If(NOT(IsNull(RitiratoDal)) and NOT(IsNull(ArrivatoIl))," e ",""),
If(IsNull(RitiratoDal),"",
CONCAT("si è ritirato ",
GiornoInItaliano(RitiratoDal),DATE_format(RitiratoDal," %e "),
MeseInItaliano(RitiratoDal),DATE_format(RitiratoDal," %Y")))
)
) AS 'Ritirati o Iscritti dopo'
FROM Studenti
WHERE NOT (
IsNull(RitiratoDal) AND IsNull(ArrivatoIl) )
ORDER BY
If(IsNull(ArrivatoIl),ArrivatoIl,RitiratoDal);
| ESERCIZIO 3 - IV-M2.5A.3 |
INTERPRETARE CORRETTAMENTE I SEGUENTI COMANDI SQL STATISTICI CON ISTRUZIONI VBA:
cs1)
SELECT Classe, Count(*) AS Nr FROM Studenti
GROUP BY
Classe ORDER BY Classe
MYSQL:
SELECT Classe, Count(*) AS Nr FROM Studenti
GROUP BY
Classe ORDER BY Classe;
cs2)
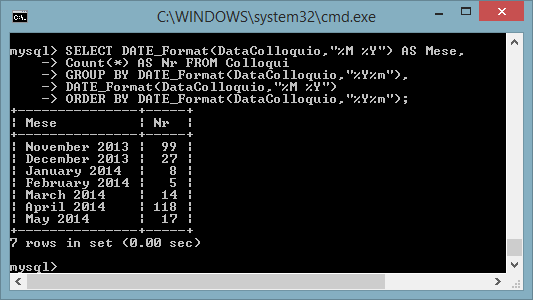
SELECT Format(DataColloquio,"mmmm yyyy") AS Mese,
Count(*) AS Nr FROM Colloqui
GROUP BY Format(DataColloquio,"mmmm yyyy"),
CLng(Format(DataColloquio,"yyyymm"))
ORDER BY
CLng(Format(DataColloquio,"yyyymm"))
MYSQL:
SELECT DATE_Format(DataColloquio,"%M
%Y") AS Mese, Count(*) AS Nr FROM Colloqui
GROUP BY
DATE_Format(DataColloquio,"%Y%m"), DATE_Format(DataColloquio,"%M %Y")
ORDER
BY DATE_Format(DataColloquio,"%Y%m");
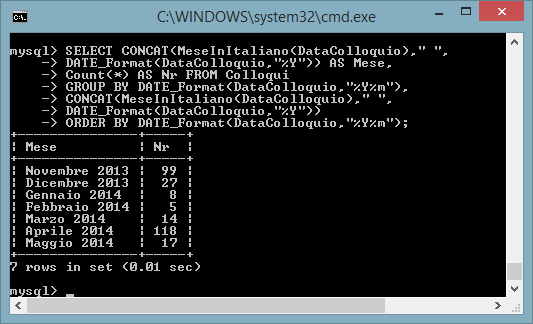
Per ottenere l'elenco con i nomi dei mesi in italiano possiamo sfruttare la funzione MeseInItaliano() che è stata definita all'interno del nostro db DATISTUDENTI
SELECT
CONCAT(MeseInItaliano(DataColloquio)," ",DATE_Format(DataColloquio,"%Y")) AS
Mese,
Count(*) AS Nr FROM Colloqui
GROUP BY
DATE_Format(DataColloquio,"%Y%m"),
CONCAT(MeseInItaliano(DataColloquio),"
",DATE_Format(DataColloquio,"%Y"))
ORDER BY
DATE_Format(DataColloquio,"%Y%m");
cs3)
SELECT Voto, Count(*) AS Nr FROM Verifiche
GROUP BY
Voto ORDER BY cbyte(Voto)
MYSQL:
SELECT Voto, Count(*) AS Nr FROM
Verifiche
GROUP BY Voto ORDER BY CONVERT(Voto,UNSIGNED);
cs4)
SELECT IIf(CByte(Voto)<4,"Gravemente Insufficiente",
IIf(CByte(voto)<6,"Insufficienti","Positivo")) AS Livello, Count(*) AS Nr
FROM Verifiche GROUP BY
IIf(CByte(Voto)<4,"Gravemente
Insufficiente",IIf(CByte(voto)<6,"Insufficienti","Positivo"))
MYSQL:
SELECT
If(CONVERT(Voto,UNSIGNED)<4,"Gravemente Insufficiente",
If(CONVERT(Voto,UNSIGNED)<6,"Insufficienti","Positivo")) AS Livello, Count(*) AS
Nr
FROM Verifiche GROUP BY
If(CONVERT(Voto,UNSIGNED)<4,"Gravemente
Insufficiente",If(CONVERT(Voto,UNSIGNED)<6,"Insufficienti","Positivo"));
cs5)
SELECT Count(*) as [Numero Voti],
Sum(iif(cbyte(voto)>=6,1,0)) AS [Numero sufficienze],
Format(Sum(iif(cbyte(voto)>=6,1,0))/Count(*),"0.00%") AS [Percentuale
Sufficienze]
FROM Verifiche
MYSQL:
SELECT Count(*) as 'Numero Voti',
Sum(if(CONVERT(Voto,UNSIGNED)>=6,1,0)) AS 'Numero sufficienze',
CONCAT(FORMAT(100*Sum(if(CONVERT(Voto,UNSIGNED)>=6,1,0))/Count(*),2),"%") AS
'Percentuale Sufficienze'
FROM Verifiche;
cs6)
SELECT DISTINCT TOP 1 CDate(DataVerifica) AS [Giorno
dell'ultimo 10]
FROM Verifiche WHERE voto="10"
ORDER BY
CDate(DataVerifica) DESC
MYSQL:
SELECT DISTINCT DataVerifica AS
'Giorno dell\'ultimo 10'
FROM Verifiche WHERE voto="10"
ORDER BY
STR_TO_DATE(DataVerifica,'%d/%m/%Y') DESC LIMIT 1
cs7)
SELECT iif(instr(QualeGenitore,":")>0,
left(QualeGenitore,instr(QualeGenitore,":")-1),QualeGenitore) AS [Con chi ho
parlato],
Count(*) AS Nr FROM Colloqui GROUP BY
iif(instr(QualeGenitore,":")>0,left(QualeGenitore,instr(QualeGenitore,":")-1),QualeGenitore)
MYSQL:
SELECT
if(instr(QualeGenitore,":")>0,
left(QualeGenitore,instr(QualeGenitore,":")-1),QualeGenitore) AS 'Con chi ho
parlato',
Count(*) AS Nr FROM Colloqui GROUP BY
if(instr(QualeGenitore,":")>0,left(QualeGenitore,instr(QualeGenitore,":")-1),QualeGenitore);
cs8)
SELECT iif(Cdate(DataAssenza)<#1/31/2014#,"1","2") & "
Quadrimestre" AS Periodo,
Count(*) As Nr FROM Assenze
Group By
iif(Cdate(DataAssenza)<#1/31/2014#,"1","2") & " Quadrimestre"
MYSQL:
SELECT
CONCAT(if(STR_TO_DATE(DataAssenza,'%d/%m/%Y')<'2014-01-31','1','2'),"
Quadrimestre") AS Periodo,
Count(*) As Nr FROM Assenze
Group By
CONCAT(if(STR_TO_DATE(DataAssenza,'%d/%m/%Y')<'2014-01-31','1','2'),"
Quadrimestre");
cs9)
SELECT Count(*) AS [Nr Colloqui], SUM(iif(
InStr(QualeGenitore,"Mamma")>0 OR QualeGenitore="Entrambe",1,0)) AS [Nr colloqui
con Mamma], SUM(iif( InStr(QualeGenitore,"Papà")>0 OR
QualeGenitore="Entrambe",1,0)) AS [Nr colloqui con Papà]
FROM Colloqui;
MYSQL:
SELECT CONCAT(ROUND(100*SUM(if(
InStr(QualeGenitore,"Mamma")>0 OR
QualeGenitore="Entrambe",1,0))/Count(*),2),'%')
AS `% con Mamma`,
CONCAT(ROUND(100*SUM(if( InStr(QualeGenitore,"Papà")>0 OR
QualeGenitore="Entrambe",1,0))/Count(*),2),'%')
AS `% con Papà` FROM
Colloqui;
cs10)
SELECT "Classe " &
My_PrimaLetteraMaiuscola(Annata(Classe)) AS [Anno Scolastico],
Count(*) AS
[Nr studenti] FROM Studenti
GROUP BY
Annata(Classe), Cbyte(Left(Classe,1))
ORDER BY Cbyte(Left(Classe,1))
MYSQL:
SELECT CONCAT("Classe
",My_PrimaLetteraMaiuscola(Annata(Classe))) AS `Anno Scolastico`,
Count(*)
AS `Nr studenti` FROM Studenti
GROUP BY Annata(Classe),
CONVERT(Left(Classe,1),UNSIGNED)
ORDER BY CONVERT(Left(Classe,1),UNSIGNED);
| ESERCIZIO 4 - IV-M2.5A.4 |
INTERPRETARE CORRETTAMENTE I SEGUENTI COMANDI MULTI TABELLARI:
ds1)
SELECT Classe, Avg(cbyte(Voto)) AS Media
FROM
Verifiche, Studenti
WHERE Verifiche.CodiceStudente=Studenti.CodiceStudente
GROUP BY Classe
MYSQL:
SELECT Classe,
Avg(CONVERT(Voto,UNSIGNED)) AS Media
FROM Verifiche, Studenti
WHERE
Verifiche.CodiceStudente=Studenti.CodiceStudente
GROUP BY Classe;
ds2)
SELECT iif(Sesso="M","Maschi","Femmine") as Genere,
Count(*) AS [Numero Assenze]
FROM Assenze, Studenti
WHERE
Assenze.CodiceStudente=Studenti.CodiceStudente
GROUP BY Sesso;
MYSQL:
SELECT
if(Sesso="M","Maschi","Femmine") as Genere, Count(*) AS 'Numero Assenze'
FROM
Assenze, Studenti
WHERE Assenze.CodiceStudente=Studenti.CodiceStudente
GROUP BY Sesso;
ds3)
SELECT Cognome, Nome, Classe
FROM Studenti LEFT
JOIN Verifiche ON Verifiche.CodiceStudente=Studenti.CodiceStudente
WHERE
Verifiche.idVerifica is null
MYSQL:
SELECT Cognome, Nome, Classe
FROM Studenti LEFT
JOIN Verifiche ON Verifiche.CodiceStudente=Studenti.CodiceStudente
WHERE
Verifiche.idVerifica is null;
ds4)
SELECT COUNT(*) as [Nr assenze]
FROM Studenti,
Assenze
WHERE Studenti.CodiceStudente = Assenze.CodiceStudente
AND
(Studenti.Classe=[Classe di cui si vogliono conoscere le date di assenza])
MYSQL: utilizzando una variabile che setto all'inizio. Devo convertire il charset della variabile poichè quello utilizzato dalla tabella è latin1.
SET @`Classe di cui si vogliono
conoscere le date di assenza`='4T';
SELECT COUNT(*) as `Nr assenze` FROM
Studenti, Assenze
WHERE Studenti.CodiceStudente = Assenze.CodiceStudente
AND (Studenti.Classe=CONVERT(@`Classe di cui si vogliono conoscere le date di
assenza` USING latin1));
ds5)
SELECT Cognome & " " & Nome & " - " & Classe AS
Studente, Materia, Voto, DataVerifica
FROM _CfgSys_Materie, Studenti,
Verifiche
WHERE Studenti.CodiceStudente = Verifiche.CodiceStudente
AND
[_CfgSys_Materie].idmaterie=verifiche.idmateria
MYSQL:
SELECT CONCAT(Cognome," ",Nome," -
",Classe) AS Studente, Materia, Voto, DataVerifica
FROM _CfgSys_Materie,
Studenti, Verifiche
WHERE Studenti.CodiceStudente = Verifiche.CodiceStudente
AND _CfgSys_Materie.idmaterie=verifiche.idmateria;
ds6)
SELECT Cognome, Nome,
Sum(iif(isnull(Colloqui.CodiceStudente),0,1)) AS [Nr Colloqui]
FROM Studenti
Left JOIN Colloqui ON Studenti.CodiceStudente = Colloqui.CodiceStudente
Group
by Cognome,Nome
MYSQL:
SELECT Cognome, Nome,
Sum(if(isnull(Colloqui.CodiceStudente),0,1)) AS 'Nr Colloqui'
FROM Studenti
Left JOIN Colloqui ON Studenti.CodiceStudente = Colloqui.CodiceStudente
Group
by Cognome,Nome;
ds7)
SELECT Cognome, Nome,Count(*) as [Nr Colloqui]
FROM
Studenti, Colloqui WHERE Studenti.CodiceStudente = Colloqui.CodiceStudente
Group by Cognome,Nome
MYSQL:
SELECT Cognome, Nome,Count(*) as 'Nr
Colloqui'
FROM Studenti, Colloqui WHERE Studenti.CodiceStudente =
Colloqui.CodiceStudente
Group by Cognome,Nome;
ds8)
SELECT Classi.Indirizzo, Count(*) AS Nr
FROM Classi,
Studenti, Colloqui
WHERE Classi.Classe = Studenti.Classe
AND
Studenti.CodiceStudente = Colloqui.CodiceStudente
GROUP BY Classi.Indirizzo;
MYSQL:
SELECT Classi.Indirizzo, Count(*) AS Nr
FROM Classi,
Studenti, Colloqui
WHERE Classi.Classe = Studenti.Classe
AND
Studenti.CodiceStudente = Colloqui.CodiceStudente
GROUP BY Classi.Indirizzo;
ds9)
SELECT top 1 Studenti.Cognome, Studenti.Nome, Count(*)
AS Nr
FROM Studenti, Assenze WHERE Studenti.CodiceStudente =
Assenze.CodiceStudente
AND Assenze.AssenzaTattica
GROUP BY
Studenti.Cognome, Studenti.Nome
ORDER BY Count(*) DESC;
MYSQL:
SELECT Studenti.Cognome,
Studenti.Nome, Count(*) AS Nr
FROM Studenti, Assenze WHERE
Studenti.CodiceStudente = Assenze.CodiceStudente
AND Assenze.AssenzaTattica
GROUP BY Studenti.Cognome, Studenti.Nome
ORDER BY Count(*) DESC LIMIT 1;
ds10)
SELECT top 1 Colloqui.QualeGenitore & " di " &
Studenti.Cognome & " " & Studenti.Nome AS Chi, Count(*) AS Nr FROM Studenti,
Colloqui
WHERE (Studenti.CodiceStudente=Colloqui.CodiceStudente)
GROUP BY
Colloqui.QualeGenitore & " di " & Studenti.Cognome & " " & Studenti.Nome
ORDER BY Count(*) DESC;
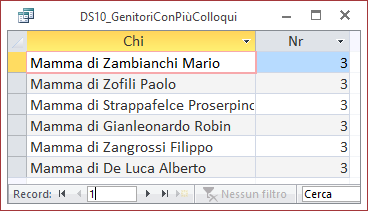
MYSQL:
SELECT
CONCAT(Colloqui.QualeGenitore," di ",Studenti.Cognome," ",Studenti.Nome) AS Chi,
Count(*) AS Nr FROM Studenti, Colloqui
WHERE
(Studenti.CodiceStudente=Colloqui.CodiceStudente)
GROUP BY
CONCAT(Colloqui.QualeGenitore," di ",Studenti.Cognome," ",Studenti.Nome)
ORDER BY Count(*) DESC LIMIT 1;
in mysql LIMIT 1 non è proprio equivalente
SELECT Classe,
SUM(CASE WHEN Sesso="F" THEN 1 ELSE 0 END) AS Femmine,
SUM(CASE WHEN Sesso="M" THEN 1 ELSE 0 END) AS Maschi
FROM Studenti GROUP By
Classe;
| ESERCIZIO 5 - IV-M2.5A.5 |
INTERPRETARE CORRETTAMENTE I SEGUENTI COMANDI SQL:
MYSQL: In mySql la query incrociata non esiste. La seguente Stored Procedure produce in MySQL un risultato analogo:
-- -----------------------------------------------------
-- STORE PROCEDURE PER EMULARE LE QUERY INCROCIATE
-- -----------------------------------------------------
DROP PROCEDURE IF EXISTS Transform;
DELIMITER $$
CREATE PROCEDURE Transform(stat_func TEXT, stat_arg TEXT,
row_select TEXT, row_from TEXT,
col_field TEXT, col_from TEXT,
Decimali TINYINT)
-- L'istruzione DETERMINISTIC indica che la funzione restituirà gli stessi
-- valori se passo lo stesso set di parametri. MySQL potrà quindi cercare
-- di ottimizzare le performance
DETERMINISTIC
-- L'istruzione successiva indica che la Stored Proc contiene solo comandi
-- di lettura dati (SELECT) ma non di scrittura
READS SQL DATA
-- L'istruzione successiva indica che la Stored Proc dovrà essere eseguita
-- con i previlegi dell'esecutore (INVOKER) e non del creatore (DEFINER) che
-- rappresenta il default
SQL SECURITY INVOKER
BEGIN
DECLARE ValoreNullo TEXT;
SET ValoreNullo = ""; -- Stringa da visualizzare al posto di NULL
-- Amplio il buffer per il comando GROUP_CONCAT
SET SESSION group_concat_max_len = 8192;
-- Evito problemi con il CHARSET sulle variabili locali
SET character_set_connection = @@character_set_database;
-- Sistemo alcuni parametri per gestire correttamente la funzione COUNT
IF (stat_func="COUNT") THEN
SET stat_func="SUM";
SET stat_arg="1";
SET Decimali=-1; -- nel conteggio niente decimali
END IF;
-- Creo il testo per costruire l'elenco delle intestazioni di colonna della
-- query incrociata
SET @column_query := CONCAT(
"SELECT GROUP_CONCAT(DISTINCT CONCAT('\\n, IFNULL(",
IF(Decimali>=0,"ROUND(",""),
stat_func,
"(CASE WHEN ",
col_field,
"=', '\"',",
col_field,
",'\"', ' THEN ",
stat_arg,
" END)",
IF(Decimali>=0,CONCAT(",",Decimali,")"),""),
",''",ValoreNullo,"'') ', CONCAT('`',",
col_field,
",'`')) SEPARATOR \' \') INTO @TitoliColonne ",
col_from
);
-- L'istruzione successiva serve solo nella fase di debug per verificare la correttezza
-- della stringa contenente GROUP_CONCAT
-- SELECT @column_query;
-- Con questo comando carico la variabile TitoliColonne
PREPARE column_query FROM @column_query;
EXECUTE column_query;
DEALLOCATE PREPARE column_query;
-- L'istruzione successiva serve a controllare l'elenco delle intestazioni di colonna ottenute
-- SELECT @TitoliColonne;
SET @pivot_query = CONCAT( row_select, @TitoliColonne," ", row_from );
-- La riga successiva serve per i debug e serve a verificare la query equivalente a quella incrociata
-- SELECT @pivot_query;
PREPARE `PivotQry` FROM @pivot_query;
EXECUTE `PivotQry`;
DEALLOCATE PREPARE `PivotQry`;
END$$
DELIMITER ;
MYSQL: Il suo utilizzo, partendo dalla sintassi generica della query incrociata ...
TRANSFORM
FunzioneStatistica(CampoValore)
SELECT CampoRighe FROM TabellaRighe ...
PIVOT
CampoColonne;
MYSQL: ... è il seguente:
Call Trasform("FunzioneStatistica","CampoValore",
"Select CampoRighe","From TabellaRighe ...",
"CampoColonne","From TabellaColonne",NrCifreDecimali);
es1)
TRANSFORM Count(*)
SELECT Classe FROM
Studenti GROUP BY Classe
PIVOT iif(Sesso="M","Maschi","Femmine");
MYSQL: Come già detto la query incrociata in mysql non esiste. In questo caso, essendo le etichette in testata poche e note a priori ("Maschi" e "Femmine") possiamo ricorrere alla funzione CASE, una per ciascun valore possibile:
SELECT Classe,
SUM(CASE WHEN Sesso="F" THEN 1 ELSE 0 END) AS Femmine,
SUM(CASE WHEN Sesso="M" THEN 1 ELSE 0 END) AS Maschi
FROM Studenti GROUP By
Classe;
oppure:
SELECT Classe,
SUM(IF(Sesso="F",1,0)) AS Femmine,
SUM(IF(Sesso="M",1,0)) AS Maschi
FROM Studenti GROUP By Classe;
oppure utilizzando la stored procedure proposta all'inizio di questa sezione:
CALL Transform('COUNT', '*', 'SELECT Classe', 'FROM
Studenti GROUP BY Classe',
'if(Sesso="M","Maschio","Femmina")', 'FROM
Studenti',-1);
es2)
SELECT Cognome, Nome, Classe
FROM Studenti WHERE
CodiceStudente NOT IN (SELECT CodiceStudente FROM Verifiche);
MYSQL:
SELECT Cognome, Nome, Classe
FROM Studenti WHERE
CodiceStudente NOT IN (SELECT CodiceStudente FROM Verifiche);
es3)
SELECT "Gravemente insufficienti" AS Livello, count(*)
as Nr from verifiche where cbyte(voto)<4
UNION
SELECT "Insufficienti",
count(*) from verifiche where voto="5" or voto="4"
UNION
SELECT
"Sufficienti", count(*) from verifiche where cbyte(voto)>=6
MYSQL:
SELECT "Gravemente insufficienti" AS
Livello, count(*) as Nr from verifiche where CONVERT(voto,UNSIGNED)<4
UNION
SELECT "Insufficienti", count(*) from verifiche where voto="5" or voto="4"
UNION
SELECT "Sufficienti", count(*) from verifiche where
CONVERT(voto,UNSIGNED)>=6;
es4)
SELECT Classi.Classe, Count(*) AS Nr INTO
_tmp_Statistica
FROM Classi, Studenti
WHERE Classi.Classe=Studenti.Classe
GROUP BY Classi.Classe
MYSQL:
CREATE TABLE _tmp_Statistica
SELECT Classi.Classe, Count(*) AS Nr
FROM Classi, Studenti
WHERE
Classi.Classe=Studenti.Classe
GROUP BY Classi.Classe;
es5)
CREATE TABLE _tmp_EstrazioneStudenti
(
CodiceStudente LONG CONSTRAINT IdxCodiceStudente PRIMARY KEY,
Cognome TEXT(35) CONSTRAINT idxCognome NOT NULL,
Nome TEXT(35),
Classe TEXT(20) CONSTRAINT idxClasse NOT NULL,
Sesso TEXT(1),
RisultatoFinale TEXT(150)
)
MYSQL:
CREATE TABLE _tmp_EstrazioneStudenti
(
CodiceStudente INT PRIMARY KEY,
Cognome
VARCHAR(35) NOT NULL,
Nome VARCHAR(35),
Classe
VARCHAR(20) NOT NULL,
Sesso CHAR(1),
RisultatoFinale VARCHAR(150)
);
es6)
INSERT INTO _tmp_EstrazioneStudenti
(
CodiceStudente, Cognome, Nome, Classe, Sesso, RisultatoFinale )
SELECT
CodiceStudente, Cognome, Nome, Classe, Sesso, RisultatoFinale
FROM Studenti
WHERE (Classe="1T");
MYSQL:
INSERT INTO _tmp_EstrazioneStudenti
(
CodiceStudente, Cognome, Nome, Classe, Sesso, RisultatoFinale )
SELECT
CodiceStudente, Cognome, Nome, Classe, Sesso, RisultatoFinale
FROM Studenti
WHERE (Classe="1T");
es7)
INSERT INTO _tmp_EstrazioneStudenti
(
CodiceStudente, Cognome, Nome, Classe, Sesso, RisultatoFinale )
VALUES
(9999,"Sechi","Marco", "6T", "M","Non ammesso")
MYSQL:
INSERT INTO _tmp_EstrazioneStudenti
(
CodiceStudente, Cognome, Nome, Classe, Sesso, RisultatoFinale )
VALUES
(9999,"Sechi","Marco", "6T", "M","Non ammesso");
es8)
UPDATE _tmp_EstrazioneStudenti
SET
Classe=Cstr(cbyte(left(Classe,1))+1) & Right(Classe,1)
WHERE
RisultatoFinale="AMMESSO"
MYSQL:
UPDATE _tmp_EstrazioneStudenti
SET Classe = CONCAT(
CONVERT(
CONVERT(
CONVERT(left(Classe,1),UNSIGNED)+1,
CHAR
)
USING Latin1
),
Right(Classe,1)
)
WHERE RisultatoFinale="AMMESSO";
es9)
DELETE FROM _tmp_EstrazioneStudenti WHERE Classe like
"*T"
MYSQL:
DELETE FROM _tmp_EstrazioneStudenti WHERE Classe like "%T";
es10)
SELECT * FROM _tmp_EstrazioneStudenti
WHERE
CodiceStudente<> ALL (SELECT CodiceStudente FROM Studenti)
MYSQL:
SELECT * FROM _tmp_EstrazioneStudenti
WHERE
CodiceStudente<> ALL (SELECT CodiceStudente FROM Studenti);
es11)
TRANSFORM Count(*) AS Nr
SELECT Left(classe,1) AS
Anno FROM Studenti, Assenze
WHERE
(Studenti.CodiceStudente=[Assenze].[CodiceStudente])
GROUP BY Left(classe,1)
PIVOT IIf(CDate(DataAssenza)<#1/31/2014#,"1","2") & " Quadrimestre";
MYSQL: Anche in questo caso, le etichette delle colonne sono limitate a 2 possibili valori: "1° Quadrimestre" e "2° Quadrimestre" per cui possiamo ricorrere alla funzione IF:
SELECT Left(classe,1) AS Anno,
SUM(IF(STR_TO_DATE(DataAssenza,'%d/%m/%Y')<STR_TO_DATE("31/01/2014",'%d/%m/%Y'),1,0))
AS `1° Quadrimestre`,
SUM(IF(STR_TO_DATE(DataAssenza,'%d/%m/%Y')>=STR_TO_DATE("31/01/2014",'%d/%m/%Y'),1,0))
AS `2° Quadrimestre`
FROM Studenti, Assenze
WHERE
(Studenti.CodiceStudente=Assenze.CodiceStudente)
GROUP By Left(classe,1);
oppure utilizzando la stored procedure proposta all'inizio:
CALL Transform('COUNT', '*', 'SELECT Left(classe,1) AS
Anno',
'FROM Studenti, Assenze
WHERE
(Studenti.CodiceStudente=Assenze.CodiceStudente)
GROUP BY Left(classe,1) ',
'IF( STR_TO_DATE(DataAssenza,"%d/%m/%Y") >=
STR_TO_DATE("31/01/2014","%d/%m/%Y"),"1 Quadrimestre","2 Quadrimestre")',
'FROM Assenze',-1);
es12)
TRANSFORM round(Avg(CDbl(VotoIn100esimi)),2) AS [Media
Reale]
SELECT
Tassonomia(VotoIn100esimi) AS [Livello voto] FROM Studenti,
Verifiche
WHERE (Studenti.codicestudente=Verifiche.codicestudente)
AND
Tassonomia(VotoIn100esimi)<>"NC"
GROUP BY
Tassonomia(VotoIn100esimi),
Tassonomia(VotoIn100esimi,"Ordine")
ORDER BY
Tassonomia(VotoIn100esimi,"Ordine")
PIVOT
Annata(Classe);
MYSQL: Le etichette delle colonne sono limitate a 5 possibili valori ("Prima","Seconda", ... e "Quinta") per cui possiamo ricorrere alla funzione CASE:
SELECT Tassonomia(VotoIn100esimi,"Testo") AS 'Livello
voto',
ROUND(AVG(CASE WHEN Annata(Classe) = 'prima' THEN VotoIn100esimi
END),2) Prima,
ROUND(AVG(CASE WHEN Annata(Classe) = 'seconda' THEN
VotoIn100esimi END),2) Seconda,
ROUND(AVG(CASE WHEN Annata(Classe) = 'terza'
THEN VotoIn100esimi END),2) Terza,
ROUND(AVG(CASE WHEN Annata(Classe) =
'quarta' THEN VotoIn100esimi END),2) Quarta,
ROUND(AVG(CASE WHEN
Annata(Classe) = 'quinta' THEN VotoIn100esimi END),2) Quinta
FROM Studenti,
Verifiche
WHERE (Studenti.codicestudente=Verifiche.codicestudente)
GROUP
BY Tassonomia(VotoIn100esimi,"Testo")
ORDER BY
Tassonomia(VotoIn100esimi,"Ordine");
oppure utilizzando la stored procedure proposta all'inizio:
CALL Transform('AVG', 'VotoIn100esimi',
'SELECT
Tassonomia(VotoIn100esimi,"Testo") AS "Livello voto" ',
'FROM Studenti,
Verifiche
WHERE (Studenti.codicestudente=Verifiche.codicestudente)
GROUP
BY Tassonomia(VotoIn100esimi,"Testo")
ORDER BY
Tassonomia(VotoIn100esimi,"Ordine")',
'Annata(Classe)', 'FROM Studenti',2);
es13)
CREATE INDEX NominativoIDX
ON
_tmp_EstrazioneStudenti ( Cognome, Nome)
WITH DISALLOW NULL
CREATE INDEX RisultatoFinaleIDX
ON _tmp_EstrazioneStudenti ( RisultatoFinale)
WITH IGNORE NULL
CREATE UNIQUE INDEX ClasseIDX
ON
_tmp_Statistica (Classe)
WITH PRIMARY
CREATE INDEX RisultatoFinaleIDX
ON _tmp_EstrazioneStudenti ( RisultatoFinale)
WITH IGNORE NULL
DROP INDEX ClasseIDX ON _tmp_Statistica;
MYSQL: Si osservi che la primary key può essere impostata solo con l'alter table.
ALTER TABLE _tmp_EstrazioneStudenti ADD CHECK (
Cognome <> NULL OR Nome <> NULL );
CREATE INDEX NominativoIDX ON
_tmp_EstrazioneStudenti ( Cognome, Nome );
ALTER TABLE _tmp_Statistica ADD PRIMARY KEY (Classe);
CREATE UNIQUE INDEX ClasseIDX ON _tmp_Statistica (Classe);
ALTER TABLE _tmp_EstrazioneStudenti
MODIFY COLUMN
RisultatoFinale TINYTEXT DEFAULT NULL;
CREATE INDEX RisultatoFinaleIDX ON
_tmp_EstrazioneStudenti (RisultatoFinale(255));
oppure:
ALTER TABLE _tmp_EstrazioneStudenti
ADD INDEX
NominativoIDX ( Cognome, Nome ),
ADD CHECK ( Cognome <> NULL OR Nome <> NULL
);
ALTER TABLE _tmp_Statistica ADD PRIMARY KEY (Classe), ADD UNIQUE KEY (Classe);
ALTER TABLE _tmp_EstrazioneStudenti
MODIFY COLUMN
RisultatoFinale TINYTEXT DEFAULT NULL,
ADD INDEX RisultatoFinaleIDX
(RisultatoFinale(255));
infine:
DROP INDEX ClasseIDX ON _tmp_Statistica;
es14)
TRANSFORM Count(*) AS Presenti
SELECT
CDate([DataVerifica]) AS [Data Scritto] FROM Studenti, Verifiche
WHERE
(Studenti.CodiceStudente=Verifiche.CodiceStudente)
AND
(Verifiche.tipologia="Scritto")
AND (DataVerifica & Classe) IN
(
SELECT (DataVerifica & CLasse) FROM Studenti, Verifiche
WHERE
(Studenti.CodiceStudente=Verifiche.CodiceStudente)
AND
(Verifiche.tipologia="Scritto")
GROUP BY (DataVerifica & Classe)
HAVING Count(*) >20
)
GROUP BY CDate(DataVerifica)
ORDER BY
CDate(DataVerifica)
PIVOT Studenti.Classe
MYSQL: In questo caso le etichette delle colonne sono tante e non prevedibili a priori pertanto non possiamo ricorrere alla funzione CASE o IF. Possiamo però sfruttare la nostra Stored Procedure per emulare le query incrociate in mysql:
CALL Transform('COUNT', '*', 'SELECT DataVerifica AS
`Data Scritto`',
'FROM Studenti, Verifiche
WHERE
(Studenti.CodiceStudente=Verifiche.CodiceStudente)
AND
(Verifiche.tipologia="Scritto")
AND CONCAT(DataVerifica,Classe) IN
(
SELECT
CONCAT(DataVerifica,Classe) FROM Studenti, Verifiche
WHERE
(Studenti.CodiceStudente=Verifiche.CodiceStudente)
AND
(Verifiche.tipologia="Scritto")
GROUP BY
CONCAT(DataVerifica,Classe)
HAVING Count(*) >20
)
GROUP BY
STR_TO_DATE(DataVerifica,"%d/%m/%Y")
ORDER BY
STR_TO_DATE(DataVerifica,"%d/%m/%Y")',
'Classe', 'FROM Studenti', -1);
es15)
ALTER TABLE _tmp_EstrazioneStudenti ADD COLUMN
Ripetente BIT;
ALTER TABLE _tmp_EstrazioneStudenti DROP COLUMN Sesso;
ALTER TABLE _tmp_EstrazioneStudenti ALTER COLUMN RisultatoFinale TEXT(160);
DROP TABLE _tmp_EstrazioneStudenti
MYSQL:
ALTER TABLE _tmp_EstrazioneStudenti
ADD COLUMN Ripetente BIT;
ALTER TABLE _tmp_EstrazioneStudenti DROP COLUMN
Sesso;
ALTER TABLE _tmp_EstrazioneStudenti MODIFY COLUMN RisultatoFinale
VARCHAR(160);
DROP TABLE _tmp_EstrazioneStudenti;