
EXCEL/OPEN CALC E I DATABASE

|
|
EXCEL/OPEN CALC E I DATABASE |
|
INTRODUZIONE
Un archivio rappresenta il contenitore dove inseriamo tutte le informazioni che descrivono il fenomeno che intendiamo analizzare. Un archivio è solitamente composto da dati non omogenei (ad esempio Alunni, Professori, Voti, Assenze, ...). Ogni gruppo di dati omogenei viene registrato all'interno di uno stesso contenitore detto tabella. Le proprietà che caratterizzano ogni singolo elemento (record) della stessa tabella vengono definite campi. In una rappresentazione tabellare le righe rappresentano i record mentre le colonne i campi. L'insieme delle descrizione dei campi (nome, dimensione, tipo ...) prende il nome di struttura della tabella.

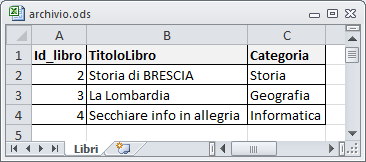
Un db composto da una sola tabella si dice monolitico. Per gestire un db monolitico possiamo utilizzare anche un foglio elettronico:
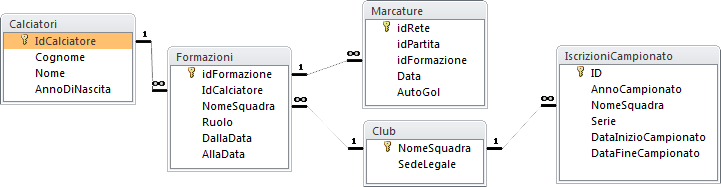
Un DB composto da diverse tabelle in relazione tra loro si dice Relazionale. Le relazioni tra le tabelle, permettono di manipolare i dati più facilmente e soprattutto evitano la ridondanza dei dati, ovvero la duplicazione delle informazioni che è inevitabile quando si opera con singole tabelle indipendenti. Un Diagramma Entità-Relazioni (ERD o Entity-Relationship Diagram) come quello sottostante evidenzia i collegamenti logici tra le tabelle del database.
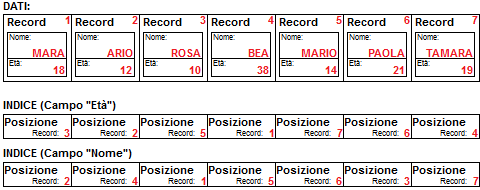
L’indicizzazione
è una delle funzionalità più importanti nei programmi che gestiscono archivi (database
L'indice viene associato ai campi soggetti a ricerche
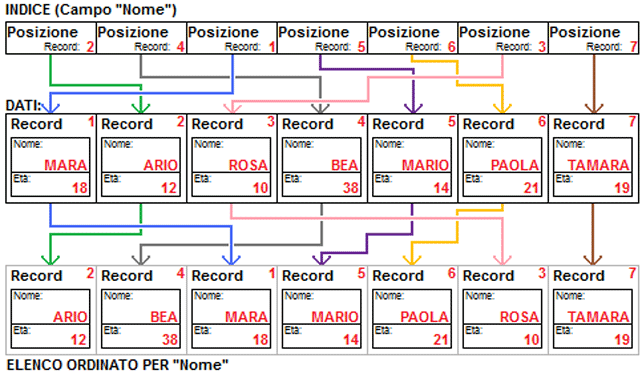
Se leggo l'archivio DATI seguendo le posizioni indicate dall'indice relativo all' "Età" ottengo un elenco ordinato rispetto a quel campo:
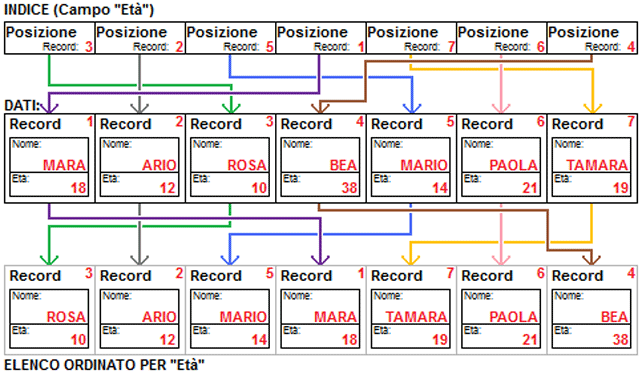
Se invece leggo l'archivio DATI seguendo le posizioni indicate dall'indice relativo al "Nome" ottengo un elenco ordinato alfabeticamente:
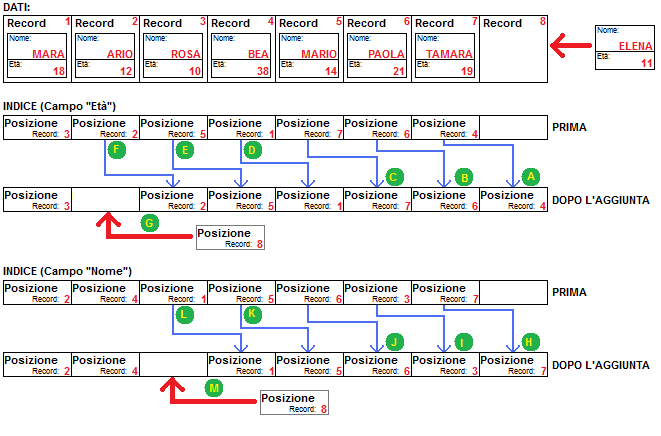
Il prezzo dell'indicizzazione è rappresentato da una minor velocità nelle operazioni di aggiornamento dell'archivio (aggiunta/modifica) poiché, oltre alle modifiche sui dati, occorre aggiornare tutti gli indici associati. Nella successiva figura viene mostrato come l'aggiunta di un nuovo record (posto in fondo all'elenco dei dati) determini una serie di operazioni aggiuntive sull'indice (A, B, C, ... , M) che hanno lo scopo di mantenerlo aggiornato.
Negli elenchi ordinati è possibile applicare una serie di algoritmi che abbattono i tempi di risposta nelle ricerche. In un elenco non ordinato l'unica ricerca possibile è quella sequenziale o casuale.
Esempio pratico: Consideriamo un elenco telefonico.
L'indice applicato è sul nominativo
(se considero solo una singola località!) per cui la localizzazione di un numero di
telefono in base al cognome risulta immediata. Immaginiamo ora di ricercare il nominativo della persona che risponde ad un determinato numero di
telefono. In questo caso l'indice non ci supporta per cui siamo costretti a
scorrere l'elenco, partendo dall'inizio, un numero dopo l'altro fino a che non
si arriva a quello richiesto (ricerca sequenziale). I tempi di risposta in
questo caso potrebbero essere anche molto lunghi.
Vediamo in dettaglio i due principali metodi (algoritmi) di ricerca:
Ricerca Sequenziale: Vediamo come calcolare il numero medio di letture necessarie per trovare un nominativo, utilizzando una ricerca sequenziale, in un elenco non ordinato di N schede (record).
Risposta: quando consulto un archivio quello che maggiormente influisce sulla velocità di ricerca è il numero di letture (confronti). Il numero medio di letture quindi è un valido parametro per misurare la bontà del metodo utilizzato nella ricerca. La ricerca sequenziale consiste nello scorrere un archivio partendo dal primo record e procedendo in avanti, una scheda dopo l'altra. Con N schede la casistica delle letture necessarie per trovare un nominativo è:
1 lettura (se lo trovo al primo colpo), 2 letture (se lo trovo al secondo colpo), ... ,N letture (se il nominativo cercato è in fondo all'archivio)
Tutte queste situazioni sono equiprobabili e pertanto la loro media rappresenta la soluzione al nostro problema
1+2+3+
.... N
N
per induzione possiamo dimostrare che
1+2+3+...N=N*(N+1)/2
da cui segue che il numero medio di letture è (N+1)/2. La formula ottenuta evidenzia come la media dei confronti (letture) aumenti linearmente al crescere dell'archivio rendendo la ricerca sequenziale improponibile in archivi di medie dimensioni. Ad esempio in un archivio di un 1.000.000 di record sono necessari, in media, circa 500.000 confronti prima di estrarre il valore cercato.
Ricerca con indice: In
un archivio indicizzato il numero
massimo di letture
scende a logm
N
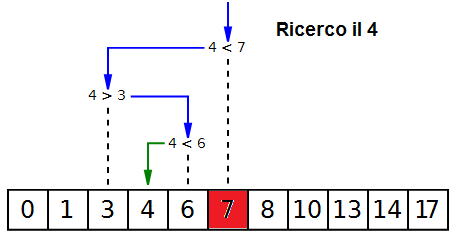
L'algoritmo dicotomico è simile al metodo usato per trovare una parola in un dizionario.
Sapendo che il vocabolario è ordinato alfabeticamente non inizio dal primo
elemento ma da quello centrale, cioè a metà
del dizionario. Si confronta questo elemento con quello cercato e ...
- se corrisponde, la ricerca termina indicando che l'elemento è stato trovato;
- se è inferiore, la tecnica di ricerca procede sugli elementi
precedenti (ovvero sulla prima metà del dizionario), ignorando la seconda metà.
- se invece è superiore, la ricerca procede sugli elementi successivi
(ovvero sulla seconda metà del dizionario), scartando la prima metà.
La ricerca continua partendo dal centro della metà presa in considerazione e
si ripete il metodo finché non trovo l'elemento cercato oppure quando tutti gli elementi sono stati scartati.
In questo caso la ricerca finisce indicando che
il valore non è stato trovato.
Scarica il file di excel che contiene l'animazione della ricerca dicotomica
Excel è un programma nato per automatizzare i calcoli. Il suo aspetto tabellare ha fatto si che molti utenti vedessero in lui un valido strumento per trasporre digitalmente i propri elenchi contenti dati.
L'uso diffuso e sistematico di Excel come gestore di database (monotabellari!) ha portato la stessa Microsoft ad inserire (ormai da tantissimi anni) un menu ad hoc per la gestione dei dati tramite Excel.
Nelle vecchie versioni il menu prende il nome di dati.
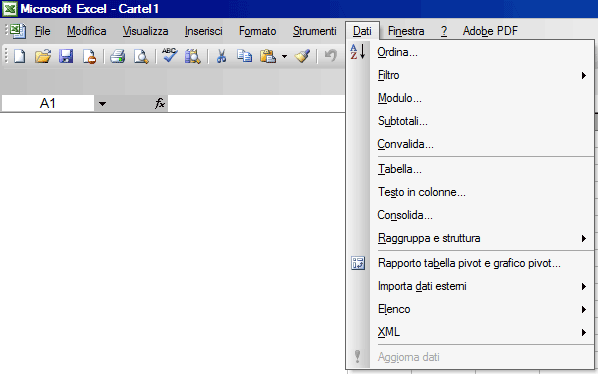
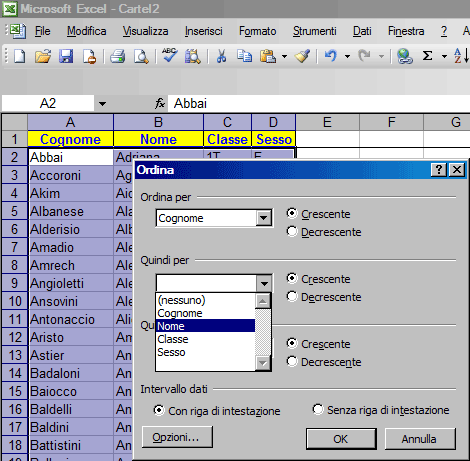
Attivando la voce "Ordina ..." verrà mostrato un menu di questo tipo
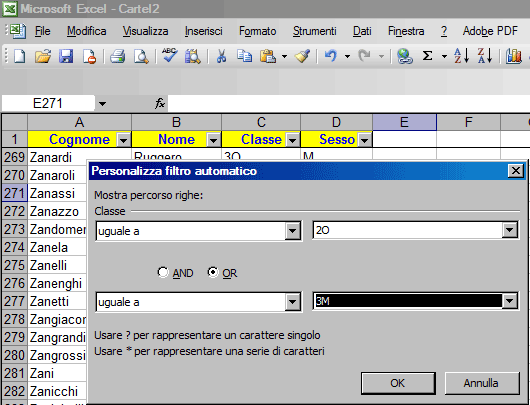
Se invece seleziono il menu "Filtro ..." ottengo:
Nella versione 2007, 2010 e 2013 il menu dati si presenta con i seguenti ribbon:


IMPORTAZIONE DEI DATI
Le informazioni aziendali vengono alimentate e gestite mediante appositi programmi. Tali programmi sono solitamente "specializzati" ovvero progettati per risolvere determinate problematiche. Pur contenendo utili informazioni adatte ad altri scopi non possono essere analizzate all'interno di tali applicativi proprio per l'alta specializzazione degli stessi. Vediamo questo esempio:
Un programma di contabilità si preoccupa di acquisire ed organizzare l'informazione seguendo le disposizioni fissate dalla vigente normativa in ambito fiscale. In questo modo è possibili compilare correttamente i bilanci e gli stati patrimoniali.
Un archivio rappresenta il contenitore dove inseriamo tutte le informazioni che descrivono il fenomeno che intendiamo analizzare.