II MODULO - HARDWARE PRATICO - 2° parte
(rielaborazione dei contenuti tratte dai siti:
http://www.pcself.com/pc/index.html
- di M. Cassone
http://www.itis.mn.it/italiano/corsi/lavori4bin/ - Classe 1B)
http://db.accomazzi.net/TarticoliI1021.html)
IL MICROPROCESSORE O CPU
L'unità centrale di elaborazione (conosciuta
anche come CPU, processore, o microprocessore) è uno
dei due componenti principali della macchina a programma memorizzato di Von Neumann: il modello su cui è basata la maggior parte dei moderni computer.
Compito della CPU è quello di eseguire le istruzioni di un programma (che deve
essere presente in memoria). Durante l'esecuzione del programma, la CPU legge o
scrive dati in memoria; il risultato dell'esecuzione dipende dal dato su cui
opera e dallo stato interno della CPU stessa, che tiene traccia delle passate
operazioni.
Una generica CPU deve
eseguire i suoi compiti sincronizzandoli con il resto del sistema: perciò è
dotata, di uno o più bus interni che si occupano di collegare le componenti
interne della CPU. Inoltre una serie di segnali elettrici esterni si occupano di
tenere la CPU al corrente dello stato del resto del sistema e di agire su di
esso. Il tipo e il numero di segnali esterni gestiti possono variare ma alcuni,
come il RESET, le linee di IRQ e il CLOCK sono sempre presenti.
|
PROCESSORI DELLA INTEL |
 |
 |
 |
| 64Bit - Da 4 a 6 core (Extreme edition)
- Socket H o LG 1156 |
64Bit - Da 2 a 4 core
- Socket H o LG 1156 |
64Bit - 2 core
- Socket H o LG 1156 |
 |
 |
 |
| 64Bit - 4 core - Generazione precedente |
64Bit - 2 core - Generazione precedente |
Server Processor (64Bit-8core)
Costo dai 2000$ a 3500$ |
Il processore (CPU, per Central Processing Unit, ossia
Unità Centrale di Trattamento) è il cervello del computer. Esso permette di
manipolare delle informazioni digitali, cioè delle informazioni codificate sotto
forma binaria, e di eseguire le istruzioni stoccate nella memoria.
Il processore (sigla CPU, per Central Processing Unit) è un circuito elettronico
cadenzato al ritmo di un orologio interno, grazie ad un cristallo di quarzo che,
sottoposto ad una corrente elettrica, invia degli impulsi, detti « top ». La
frequenza dell'orologio (detta anche ciclo, corrispondente al numero di impulsi
al secondo, è espressa in Hertz (Hz). Così, un computer a 200 MHz ha un orologio
che invia 200 000 000 battiti al secondo.
Ad ogni top dell'orologio il processore esegue un'azione, corrispondente ad
un'istruzione o ad una parte di istruzione. L'indicatore detto CPI (Cicli Per
Istruzione) permette di rappresentare il numero medio di cicli di orologio
necessario all'esecuzione di un'istruzione su un microprocessore.
La potenza può
quindi essere caratterizzata dal numero di istruzioni che è capace di trattare
al secondo. L'unità utilizzata è il MIPS (Milioni di Istruzioni al Secondo)
corrispondente a: frequenza del processore/CPI.
ISTRUZIONI:
Un ' istruzione è l'operazione elementare che il
processore può eseguire. Le istruzioni sono stoccate nella memoria principale,
per essere poi trattate dal processore. Un'istruzione è composta da due campi :
- il codice operazione, che rappresenta l'azione che il processore deve
eseguire;
- il codice operando, che definisce i parametri dell'azione. Il codice operando
dipende dall'operazione. Si può trattare di un dato oppure di un indirizzo di
memoria.
|
Codice operazione |
Campo operando |
Il numero di bytes di un'istruzione è variabile secondo il
tipo di dato (l'ordine di grandezza va da 1 a 4 bytes).
Le istruzioni possono essere classificate in categorie fra cui le principali
sono :
- Accesso alla memoria : degli accessi alla memoria o trasferimenti di dati tra
registri.
- Operazioni aritmetiche : operazioni come le addizioni, sottrazioni, divisioni
o moltiplicazioni.
- Operazioni logiche : operazioni E, O, NO, NO esclusivo, ecc.
- Controllo : controlli di sequenza, collegamenti condizionali, ecc.
ELEMENTI PRINCIPALI DEL PROCESSORE:
REGISTRI:
Quando il processore esegue delle istruzioni, i dati sono temporaneamente
stoccati in piccole memorie rapide da 8, 16, 32 o 64 bits che vengono chiamate
Registri. Secondo il tipo di processore il numero totale dei registri può
variare da una dozzina fino a più centinaia.
I principali registri sono :
il registro accumulatore (ACC), che immagazzina i risultati delle
operazioni aritmetiche e logiche (questo registro appartiene alla instruction
unit);
il registro di stato (PSW, Processor Status Word), che permette di
stoccare degli indicatori sullo stato del sistema (questo registro
appartiene alla instruction unit)
il registro istruzioni (IR), che contiene le istruzioni in corso di
trattamento (questo registro appartiene alla control unit);
il program counter (PC), che contiene l'indirizzo della prossima
istruzione da trattare (questo registro appartiene alla control unit);
il MDR, che immagazzina temporaneamente un dato proveniente dalla memoria
viva.
MEMORIA CACHE:
La Memoria cache (detta anche memoria tampone) è
una memoria rapida che permette di ridurre i tempi di attesa delle informazioni
stoccate nella memoria RAM. In effetti, la memoria centrale del computer ha una
velocità molto meno importante rispetto al processore. Esistono comunque delle
memorie molto più rapide, ma ad un costo decisamente elevato. La soluzione
consiste quindi nell'includere questo tipo di memoria rapida in prossimità del
processore e immagazzinarvi temporaneamente i dati principali che devono essere
trattati dal processore. I computer recenti hanno più livelli di memoria cache :
La memoria cache di primo livello (detta L1 cache, per Level 1 Cache) è
direttamente integrata nel processore. Essa è suddivisa in 2 parti :
- La prima è la cache di istruzioni, che contiene le istruzioni derivanti dalla
memoria ram decodificata durante il passaggio nelle pipeline.
- La seconda è la cache di dati, che contiene dei dati derivanti dalla memoria
ram e i dati recentemente utilizzati nelle operazioni dal processore.
Le cache di primo livello sono di rapido accesso. Il loro tempo di accesso tende
ad avvicinarsi a quello dei registri interni del processore.
La memoria cache di secondo livello (detta L2 Cache, per Level 2 Cache) è
posta a livello del case contenente il processore (nel chip). La cache di
secondo livello si pone tra il processore con la sua cache interna e la memoria
RAM. Esso è di più rapido accesso rispetto a quest'ultima ma meno rapida
rispetto alla cache di primo livello.
La memoria cache di terzo livello (detta L3 Cache, per Level 3 Cache) è
posta a livello della scheda madre (molto spesso coincide con la RAM stessa).
Tutti questi livelli di cache permettono di
ridurre il tempo di latenza (intervallo di tempo che intercorre fra il momento
in cui arriva un dato ad un sistema ed il momento in cui è disponibile) delle
diverse memorie durante il trattamento e il trasferimento delle informazioni.
Mentre il processore lavora, il controller di cache di primo livello può
interfacciarsi con quello di secondo livello per effettuare dei trasferimenti di
informazioni senza bloccare il processore. Allo stesso modo, la cache di secondo
livello si interfaccia con quella della memoria ram (cache di terzo livello),
per permettere dei trasferimenti senza bloccare il normale funzionamento del
processore.
UNITA' FUNZIONALI:
Il processore è costituito anche da un insieme di unità
funzionali collegate fra loro ed esattamente:
>> Un' unità di controllo (CONTROL UNIT) che legge i dati in
arrivo, li decodifica e poi li invia all'unità di esecuzione (Fetch, Decode e
Execute);
L'unità di controllo è costituita soprattutto dai seguenti elementi :
- sequenziatore (o blocco logico di comando) incaricato di sincronizzare
l'esecuzione delle istruzioni al ritmo di un orologio. E' inoltre incaricato
dell'invio dei segnali di comando ;
- Program Counter che contiene l'indirizzo della prossima istruzione da
eseguire (su alcune architetture il program counter conserva invece l'indirizzo
dell'istruzione in via di esecuzione);
- IR o registro di istruzione che contiene l'istruzione in esecuzione.
>> Un' unità di esecuzione (INSTRUCTION UNIT), che compie le azioni che
gli ha passato la Control Unit. L'unità di esecuzione è composta
soprattutto dai seguenti elementi :
- L' unità aritmetica e logica (ALU). La ALU assicura le funzioni di base
del calcolo aritmetico e le operazioni logiche (E, O, O esclusivo, ecc.);
- L'unità di virgola flottante (sigla FPU, per Floating Point Unit), che
compie i calcoli complessi non interi che l'unità aritmetica e logica non può
realizzare.
- Il registro di stato ;
- Il registri accumulatori.
>> Una unità di gestione del bus (I/O Management Unit), che
gestisce i flussi di informazioni in entrata e uscita, in collegamento con la
memoria RAM del sistema;
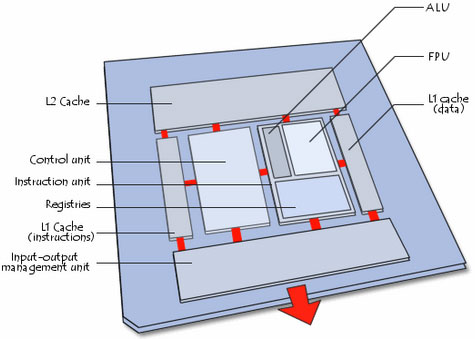
I segnali che attraversano le unità funzionali della CPU si dicono segnali di comando
e sono dei segnali elettrici che permettono di
orchestrare le differenti unità del processore partecipanti all'esecuzione di
un'istruzione. I segnali di comando sono distribuiti grazie a un elemento detto
sequenziatore. Ad esempio il segnale Read / Write, in italiano lettura/scrittura, permette
di segnalare alla memoria che il processore vorrebbe leggere o scrivere
un'informazione.
Quindi la
CPU (Central Processing Unit) è
il motore del computer, la parte che elabora le informazioni.
Le caratteristiche principali dei processori sono il numero di informazioni che
possono essere elaborate contemporaneamente, la quantità di istruzioni
eseguibili e la velocità di
elaborazione (frequenza espressa in Mhz)
Il microprocessore o CPU (acronimo inglese di Central
Processing Unit) si incarica di dirigere tutte le operazioni e di trasferire
le informazioni risultanti a tutti i componenti del computer: costituisce il
"cervello" vero e proprio del nostro elaboratore. Un
"cervello" infinitamente potente e non più grande di 10 cm quadrati.
Ogni generazione di microprocessori sfoggia un numero di "piedini"
(PIN) superiore alla precedente. Questi piedini costituiscono l'unico veicolo di
comunicazione tra il processore e le varie componenti presenti sulla scheda
madre: ciascuno di essi assolve un ruolo unico ed insostituibile.
I vecchi processori 80386 avevano 132 piedini. Il processore successivo: il 486
aveva 168 piedini; I primi PENTIUM, per assicurare le prestazione a 64 bit,
richiedevano 273 piedini. Oggi la CPU I7-900 ha ben 1366 piedini.
 |
 |
 |
| Piedinatura di un vecchio processore
486
(interfaccia PGA) |
piedinatura i7 (Interfaccia LGA) |
Socket LGA 1366 o Socket B |
L'interfaccia di connessione per i processore si classificano
in due categorie LGA e PGA.
Il Land Grid Array (LGA) è un'interfaccia fisica di
connessione per i processori introdotta da Intel nel 2004. A differenza dell'interfaccia
PGA (pin grid array), utilizzata nei vecchi socket Intel e AMD, non sono
presenti pin sul processore, sostituiti da contatti in rame sottoposto a
doratura elettrolitica, che toccano dei pin posti sul socket della scheda madre.
Intel lanciò l'interfaccia LGA nel giugno 2004, presentando il socket 775
(775 indica il numero di pin) per processori Pentium 4 (e successivamente
utilizzato per Pentium D e Core 2 Duo) e continuerà ad utilizzarla nei futuri
socket B e H. Anche AMD adotterà l'interfaccia LGA nel socket L1 per CPU Opteron
X2.
Tra i principali vantaggi di questo tipo di connessione vi sono i minori costi
produttivi, la possibilità di aumentare la densità dei pin e la superficie di
contatto tra processore e socket, permettendo un flusso di corrente più stabile
anche a frequenze elevate. Tuttavia i produttori di schede madri hanno visto l'LGA
come un tentativo di Intel di liberarsi dei problemi di rottura dei pin, che
vanno a carico dei produttori stessi.
BREVE STORIA DEI MICROPROCESSORI
INTEL
Nel lontano 1971, abbiamo il debutto del primo processore della Intel (Integrated
Electronics) 4004, di cui sotto vedete un esemplare.

Il 4004 era a tutti gli effetti un 'mini-computer' per l'epoca, in quanto
all'interno inglobava tutta la logica per farlo funzionare come processore general-purpose, cioè per applicazioni generali. Consisteva di 2300 transistor.
Il package era dotato di soli 16 piedini per la comunicazione col mondo esterno.
I registri cioè i dispositivi di memorizzazione interni, erano a soli 4 bit (da
cui la terminologia architettura a 4 bit dell'Intel), poteva decodificare
al massimo 45 istruzioni e correva intorno al KHz. Sembra poco, ma fu un chip
rivoluzionario poiché stabilì in via definitiva il percorso che avrebbe seguito
l'elettronica negli anni a venire: e cioè cercare di integrare quante più
funzionalità possibili all'interno di un singolo chip, permettendo ad
applicazioni di natura diversa di girare sullo stesso processore. Nel 1972 esce
il 8008 con architettura a 8 bit.
Potremmo collocare l'inizio dell'era dei Personal Computer nel
fatidico anno 1981, quando nacque il PC IBM, dotato di un processore
denominato 8088 sviluppato nei laboratori Intel. Le prime CPU sono state sempre
contraddistinte da una duplice serie di numeri: il primo è la sigla di
progettazione ed è sinonimo della quantità di informazioni che il
microprocessore è in grado di trattare in una sola volta; il secondo numero
rappresenta i megahertz del processore ed indica la velocità con cui le
informazioni vengono trasferite da e verso la CPU. Alcuni processori sono
contraddistinti anche da lettere del tipo SX o DX, che indicano la
versione del processore.
Di seguito viene fornita una sintetica descrizione dei principali modelli di
microprocessore:
8086 e 8088
Rappresentano la preistoria dei microprocessori ed hanno una velocità
variabile da 4,7 a 10 MHz. I computer che utilizzano questi processori
sono denominati XT e sono usciti di produzione verso la metà degli anni
80. L'8086 è stato il primo processore x86, che seguiva i primi, segnati dalle
sigle 8008, 8080 e 8085. Questo processore a 16-bit poteva gestire 1 MB di
memoria usando un bus esterno a 20-bit. La frequenza di clock scelta da IBM fu
di 4.77 MHz, decisamente bassa, considerando che alla fine della sua carriera
questo processore raggiunse la velocità di 10 MHz.
Questa tipologia aveva circa 29.000 transistor
(un transistor è una componente
elettronica che può essere settata in ON/OFF dal microprocessore).
Più transistor più potenza
computazionale.
Il primo PC usava un derivato di questo processore, il modello 8088, disponeva
di un bus dati (esterno) di 8-bit. Un'interessante storia riguardo questo
processore è che il sistema di controllo degli space shuttle usa processori 8086
e la NASA è stata costretta ad acquistarne, nel 2002, alcuni esemplari da eBay,
poiché Intel non poteva più fornirne.
 |
|
40 DIP (Dual Inline
Package) |
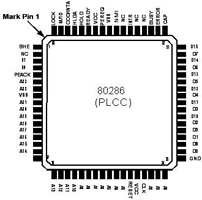
80286
Presentato nel 1982, il processore 80286 era tre volte più veloce dell'8086,
alla stessa frequenza. Poteva gestire 16 MB di memoria, ma era ancora un
processore a 16-bit. Fu il primo x86 equipaggiato con un'unità di gestione della
memoria (MMU), che permetteva di gestire la memoria virtuale.
Come l'8086, non
aveva unità floating-point (FPU), si affidava ad un co-processore x87 (80287).
Intel offriva questi processori alla massima frequenza di 12.5 MHz, mentre i
concorrenti offrivano già modelli a 25 MHz.
 |
 |
| |
PLCC 68 : Plastic Lead
less Chip Carrier |
80386
Inseriti sul mercato a partire dal 1986, hanno una velocità dai 16 ai 40 MHz.
Esistono due diversi modelli gli SX e i DX. Mentre i secondi
sfruttano a pieno la tecnologia appena immessa sul mercato, gli SX
rappresentano una sorta di compromesso nato per fattori economici, pur
trattandosi di 80386 a tutti gli effetti sono montati su schede
madre di precedente generazione che non riescono a sfruttare a pieno titolo
le prestazioni del processore. Con questa generazione di processori è comparso
anche il modello denominato
SL, equivalente ad un SX ma a basso
consumo di energia, particolarmente sfruttato soprattutto nei PC
portatili.
L'Intel 80386 è stato il primo x86 con architettura a 32-bit. Le versioni SX (Single-word
eXternal), avevano un bus dati a 16-bit, mentre quelli DX (Double-word
eXternal), un bus dati a 32-bit. Due altre versioni sono degne di menzione: la
SL, che era il primo x86 a offrire un sistema di gestione della cache (esterna)
e il 386EX, usato nel programma spaziale (il telescopio Hubble usa questo
processore). Questa tipologia aveva circa 275.000 transistor.
 |
 |
 |
| |
|
Ceramic Pin Grid Array a
132 pin (CPGA-132) |
 |
 |
| Plastic Quad
Flat Package 132(PQFP-132) |
Clone AMD |
80486
Nel 1991 sono stati presentati i primi modelli della fortunata serie 80486
contraddistinta dalla caratteristica innovativa dell'incorporazione del
coprocessore matematico direttamente all'interno della CPU. Esistono 4 diversi
modelli dei processori 80486: gli SX, i DX, i DX2 e i DX4,
più alcuni modelli a basso consumo energetico come gli SL. Anche il
processore 80486 SX rappresenta una sorta di "anello di
transizione" nato per fini economici, in quanto è l'unico dell'intera
serie a non essere dotato di coprocessore matematico; la sua velocità varia da
25 a 33 MHz. I modelli DX raggiungono una velocità massima di 50 MHz
e hanno rappresentato, unitamente ai loro "fratelli maggiori" la vera
piattaforma di decollo per la grafica e la multimedialità. I DX2 e DX4
utilizzano una tecnologia conosciuta sotto il termine di "doppio
orologio", in grado di raddoppiare o addirittura quadruplicare la velocità
interna della CPU. Mentre un DX lavora in tutta la scheda
madre a 50 MHz, un DX2 lavora a 25 MHz nel resto del
computer e a 50 MHz all'interno della CPU. Le velocità dei DX2
variano da 50 a 66 MHz, mentre i DX4 raggiungono normalmente i 100 MHz. Il 486 è
stato, per molti, la porta di ingresso al mondo dei computer. Il famosissimo 486
DX2/66, infatti, è stato per molto tempo considerato il minimo per chi volesse
giocare. Questo processore, presentato nel 1989, offriva interessanti
funzionalità, come una FPU integrata, cache dati, e il primo moltiplicatore di
clock. L'FPU non era altro che un coprocessore x87, integrato direttamente del
486 DX (non SX). Vantava anche 8 KB di cache di primo livello integrata nel
processore (tipo write-through), ed era possibile posizionare sulla motherboard
una cache di secondo livello. E' il primo processore che infrange la barriera
del milione di transistor. Ha un bus a 32 bit.
La seconda generazione di 486 offriva un moltiplicatore, poiché il processore
operava a FSB più veloce: moltiplicatore 2X per il DX2 e 3X per il DX4.
Questo processore contava su una
cache di 16 KB, con un numero relativamente ridotto di transistor, 1,6 milioni.
Il processo produttivo, all'epoca, era a 600 nm, e il chip, che occupava 76 mm²,
consumava meno potenza dell'originale 486 (al voltaggio di 3.3V)..
 |
 |
 |
 |
| |
|
19x19 PGA Socket 3
- 237 pin |
PGA Socket 2 - 238 pin |
 |
 |
| Package PQFP
196 |
Clone AMD |
PENTIUM
Secondo la tradizione avrebbe dovuto chiamarsi 80586, ma è stato battezzato
PENTIUM a causa delle leggi americane che non consentono di registrare un
marchio di fabbrica composto di soli numeri. Il nome è figlio di una
problematica legale nata quando sul mercato si sono affacciati i
"cloni" dei processori della casa produttrice Intel.
Lo
stratagemma del nome è nato per garantire alla Intel l'univocità di
denominazione. Si tratta di un processore immensamente potente la cui velocità
varia dai 60 ai 200 MHz. Il Pentium, presentato nel 1993, divenne famoso anche
per il bug che lo affliggeva. Alcune operazioni di divisione, infatti,
producevano un risultato non corretto ; Intel corse velocemente ai ripari,
rimpiazzando tutti i processori difettosi, ma il danno ormai era fatto, e tutti
i media ne parlarono.
Il Pentium esisteva in tre versioni: la prima sprovvista di moltiplicatore, la
seconda dotata di moltiplicatore (tra cui il famoso Pentium 166), e l'ultima
dotata di un set di istruzioni SIMD per x86s, MMX. Il Pentium MMX vedeva
incrementata anche la dimensione della cache di primo livello e offriva alcuni
piccoli vantaggi: fu il primo processore x86 in grado di eseguire due istruzioni
in parallelo, per esempio. La cache L2 era posizionata sulla motherboard (e
lavorava alla frequenza dell'FSB).
Ecco una veloce spiegazione del bug del Pentium: certi calcoli che usavano la
FPU producevano, raramente, risultati sbagliati, per quanto alcune fonti non
sono d'accordo sul "raramente". In ogni caso, Intel sostituì il prodotto
gratuitamente. Ecco un esempio di quanto accadeva:
4195835.0/3145727.0 = 1.333 820 449 136 241 002 (risultato corretto)
4195835.0/3145727.0 = 1.333 739 068 902 037 589 (risultati, non corretto, su un
Pentium con bug).
 |
 |
 |
 |
| |
|
Socket 4: 21x21 PGA |
Clone AMD |
PENTIUM PRO
Il Pentium Pro, rilasciato nel 1995,
era la prima CPU x86 in grado di gestire più di 4 GB di RAM usando il PAE (Physical
Address Extension), con indirizzi a 36-bit, quindi 64 GB. Un punto interessante
è che questo processore era anche il primo P6 (da cui deriva l'architettura Core
2) e anche il primo x86 a includere la cache L2
sul processore, anziché sulla
motherboard. C'erano da 256 KB a 1 MB di cache vicino alla CPU, che prendeva il
nome di "cache on-package" (differentemente da on-chip), che funzionava alla
stessa frequenza della CPU.
Questo processore aveva alcuni problemi di prestazioni.
Offriva ottime
prestazioni con applicazioni a 32-bit, ma era lento con software scritti in
16-bit (come Windows 95). La causa era semplice: l'accesso ai registri a 16-bit
causa problemi di gestione dei registri a 32-bit, cancellando, di fatto, i
vantaggi dell'architettura del Pentium Pro.
Questa tipologia aveva circa 5,5 milioni di transistor
PENTIUM II
Presentato nel 1997, il Pentium II
era un riadattamento del Pentium Pro per il mercato di massa. Era molto
simile
al Pentium Pro, dal quale però differiva per la memoria cache. Anziché usare
cache alla stessa frequenza del processore (che era costoso), i 512KB di cache
L2 operavano a metà della frequenza. Inoltre, il Pentium II abbandonava il
classico socket per passare su una cartuccia che conteneva sia processore che
cache.La cartuccia veniva innestata su un particolare slot noto con la sigla di
SECC
C'erano nuove caratteristiche rispetto al Pentium Pro, come il supporto MMX (SIMD)
e una cache L1 di dimensioni doppio. Il Primo Pentium III (Katmai) era molto
simile al Pentium II. Presentato nel 1999, portava essenzialmente il supporto
per SSE (istruzioni SIMD), ma per il resto era identico.
 |
 |
| Single Edge Contact
Cartridge 242 (SECC-242) - Socket: Slot 1 |
Schema di montaggio |
 |
| Slot 1 |
CELERON e XEON
Alla fine degli anni novanta, Intel
presentò due processori molto conosciuti:
Celeron e Xeon. Il primo mirava al
mercato entry-level, e il secondo al mercato server, e in certi casi a quelli
workstation. Il primo Celeron (Covington) era un Pentium 2 senza cache L2, e
offriva prestazioni molto limitate, mentre lo Xeon era un Pentium II con cache
maggiore. Entrambi i marchi esistono ancora oggi: Celeron per il mercato
entry-level (generalmente modelli con meno cache e FSB più lento) e Xeon per i
server (con FSB più veloce, a volte più cache, e velocità di clock superiori).
Intel ha velocemente aggiunto più cache ai suoi Celeron con il modello Mendocino
(128 KB). Il Celeron 300A è famoso per le sue capacità di overclock, in grado di
andare a velocità maggiore del 50%.
Come il Pentium II, lo Xeon è dotato di cache L2 esterna, presente sulla
cartuccia dove risiede il processore stesso. La sua capacità era compresa tra i
512 KB e i 2 MB, e il numero di transistor tra i 31 milioni e i 124 milioni.
Definizione: In informatica la pratica
dell'overclocking consiste nel perseguire il miglioramento delle
prestazioni di un componente elettronico (in genere una CPU) mediante l'aumento
della frequenza di clock rispetto a quella prevista dal produttore, marchiata
sul package della CPU.
 |
 |
| Celeron (mendoncino) - Interfaccia SEPP-242 |
|
|
| Slot 1 |
PENTIUM III
Il Pentium III Coppermine è stato
il
primo processore x86 commerciale di Intel a raggiungere la velocità di clock di
1 GHz; fu rilasciata anche una versione da 1.13 GHz, ma sparì presto dal
mercato perché molto instabile. C'erano tre versioni di PENTIUM III:
server (Xeon), entry-level (Celeron) e mobile (con la prima versione di
SpeedStep).
Una versione migliorata (Tualatin), con più cache L2 (512 KB) e prodotta con
processo produttivo a 130 nm, fu rilasciata nel 2002. Era pensata per i server (PIII-S)
e i dispositivi mobile, mentre era meno comune per i sistemi consumer.
Questa tipologia aveva circa 28 milioni di transistor
 |
|
| SECC2-242 - Socket: Slot
1 - Questa tipologia aveva 9,5 milioni di transistor |
Schema di montaggio |
|
|
| Slot 1 |
Nel novembre del 2000, Intel
annunciò il suo nuovo processore, il Pentium 4. Questo processore vantava una
frequenza più alta, con un minimo di 1,4 GHz, ma, ciò nonostante, non teneva il
passo con i suoi concorrenti, che pur lavoravano alla stessa frequenza. Tanto
gli AMD Athlon che i Pentium III, infatti, facevano meglio. Intel cerco di
passare alla memoria Rambus (l'unica memoria del tempo in grado di offrire le
prestazioni richieste dall'FSB della CPU), ma fallì, complicando ulteriormente
una situazione già difficile. Costoso e molto caldo, il Pentium 4, in molte
varianti, rimase sul mercato per alcuni anni (vide, nel tempo, l'aggiunta di una
cache L3 e di tecnologie come l'Hyper-Threading).
Furono vendute, in ogni caso, versioni mobile (con moltiplicatore variabile),
versioni Celeron (con cache L2 più contenuta), e versioni Xeon (con cache L3).
L'Hyper-Threading e la cache L3 apparirono prima sui server, per poi essere
adattate ai processori standard (anche se la cache L3 era disponibile solo per i
modelli EE).
Dobbiamo anche menzionare l'FSB, che, grazie alla tecnologia QDR, Quad Data
Rate, superò di 4 volte la velocità nominale, quindi un bus di 400 MHz era in
verità un bus QDR a 100 MHz, 533 MHz corrispondeva a un bus a 133 MHz QDR, etc.
Infine, fece la sua comparsa la versione a 64 bit del Pentium 4
verso fine del
2005, di cui parleremo più avanti.
Definizione:
ll multithreading in informatica indica il supporto hardware da parte di
un processore di eseguire più thread
Definizione: La tecnologia
Hyper-Threading è stata presentata da Intel in un momento in cui i processori
dual core non potevano ancora venire prodotti a prezzi ragionevoli.
L'idea alla base della tecnologia Hyper-Threading era quella di duplicare alcune
unità di elaborazione all'interno dei microprocessori al fine di poter eseguire
simultaneamente alcune operazioni, grazie a tecniche di multithreading. Si trattava, in un certo senso, di un
tentativo di creare un processore di transizione tra i tradizionali single core
e i successivi dual core, non inserendo 2 interi core all'interno di un unico
package, ma duplicando solo alcune aree "sensibili" del singolo core. Grazie
all'Hyper-Threading un singolo core era comunque in grado di gestire più thread
in contemporanea, quando le istruzioni di un thread rimanevano bloccate nella
pipeline il processore procedeva ad elaborare un secondo thread al fine di
mantenere le unità di elaborazione sempre attive. Con l'avvento, a partire dalla
metà del 2006, dei nuovi processori dual core basati sull'architettura "Core", i Core 2 Duo Conroe, come successori del Pentium D Presler, Intel decise di
abbandonare l'implementazione di tale tecnologia in quanto essa era poco
efficace quando abbinata a processori dual core con pipeline corte come i Core 2
Duo. Nel 2007 è cessata la
sua produzione.
 |
 |
 |
| Prime versioni PENTIUM 4 |
|
Socket PGA 423 |
 |
 |
 |
| Pentium 4
Northwood |
Pedinatura LGA 478 |
Socket PGA478B |
PENTIUM M(obile)
Nel 2003 il mercato dei computer
portatili esplose, e Intel aveva solo due processori da impiegare: il vecchio
Pentium III Tualatin e il Pentium 4, il cui elevato consumo energetico lo
rendeva inadatto ai notebook. Un salvatore stava però arrivando da Israele: il
Banias (alias, Pentium M). Questo processore, basato sull'architettura P6 (la
stessa del Pentium Pro) offriva elevate prestazioni e basso consumo energetico.
Batteva anche il Pentium 4, con consumi molto inferiori. Era il processore usato
per la piattaforma Centrino, che fu seguito (nel 2004) dal più performante
modello Dothan. Il Pentium M lasciò un segno indelebile nel mercato dei
portatili.Come per il Pentium 4, il Front Side Bus operava a un quarto della
frequenza nominale (QDR). Il connettore usato, il Socket 479, era differente da
quello per sistema desktop, il Socket 478.
 |
 |
 |
| |
Pentium M Dothan |
Socket M o PGA 479M |
PENTIUM IV (64Bit)
Nel 2005, Intel migliorò il suo
Pentium 4 due volte. Prima con il Prescott-2M, e poi con lo Smithfield. Il primo
era un processore a 64-bit, basato sul design Prescott, il secondo era un
processore dual-core. Questi due modelli sono abbastanza simili, e hanno gli
stessi problemi degli altri Pentium 4: poche istruzioni per ciclo (IPC) e
difficoltà nell'aumento della frequenza di clock a causa della perdita di
corrente. Questi due processori, che facevano da tappabuchi, aspettando l'arrivo
del Core 2 Duo, non sono tra i modelli Intel più apprezzati. La versione desktop
dello Smithfield, il Pentium D dual-core, in realtà era un processore che
abbinava due die Prescott nello stesso package.
 |
 |
 |
|
Pentium 4 Prescott-2M |
|
LGA 775 |
CORE DUO
Nel 2006 Intel presentò i Core Duo
(E' il successore del Pentium M Dothan).
Il primo processore dual-core per PC portatili che offriva elevate prestazioni
-
nettamente superiori al Pentium 4. Fu
anche il primo processore x86 ad essere un vero dual-core. La cache, per
esempio, era condivisa (mentre il Pentium D integrava due processori nello
stesso package). Questo processore era parte della piattaforma Centrino Duo, che
ebbe un grande successo. L'unico problema riguarda la natura a 32-bit, un passo
indietro rispetto al Pentium 4 in questo contesto.
Fu presentata anche una versione a un solo core, il Core Solo, e una versione a
basso consumo che usava un bus a 533 MHz (133 MHz QDR), anziché 667 MHz. Questo
processore era usato nei server (nome in codice Sossaman); era la prima volta
che un processore pensato per il mondo mobile entrava in quello server. Questo
processore non usa ufficialmente l'architettura Core del Core 2 Duo, e fu
rimpiazzato velocemente con il Core 2 Duo (Merom).
 |
 |
 |
 |
| Pentium Core Duo Meron |
Pentium Core Duo Meron |
|
Socket M |
CORE 2 DUO e QUAD
Nel 2006, Intel ha presentato un processore
che in breve tempo ha conquistato il mondo: il Core 2 Duo. Derivato dal lavoro
svolto per il Pentium M, questo processore è basato su una nuova architettura.
Fino a questo momento, Intel aveva due linee di processori - Pentium 4 per i
desktop e Pentium M per il mercato mobile, ed entrambe le linee per server. In
contrasto, Intel ora ha una sola micro-architettura per tutte le linee. Il Core
2 Duo a 64 bit è presente nel mercato desktop, mobile e server.
Ci sono molte versioni di questa architettura, che risultano in varie
configurazioni di numero di core (da uno a quattro), memoria cache (da 512 KB a
12 MB), e FSB (tra i 400 e i 1600 MHz).
La versione mobile (Merom) è identica, ma ha un FSB più lento, mentre la
versione Extreme Edition ha un FSB ancora più veloce. Il Core 2 Duo esiste anche
in versione a quattro core (nel 2007: è il primo con tale tecnologia) - Core 2
Quad, che abbina due Conroe nello stesso package. La versione a 45 nm del Core 2
Duo (Penryn) dispone di più cache e genera meno calore, ma fondamentalmente la
struttura è la stessa.
 |
 |
 |
|
| CORE 2 DUO |
CORE 2 QUAD |
|
Socket T o LGA775 |
DUAL CORE
Esistono anche modelli economici come Pentium
Dual Core, Centrino Dual Core
 |
|
| |
Socket T o LGA775 |
GAMMA NEHALEM
Con il lancio dell'architettura Nehalem Intel
ha deciso di utilizzare dei "differenziatori" per distinguere i modelli
destinati alle varie fasce di mercato. Di conseguenza alcuni core sono alla base
di diversi processori differenti a seconda delle caratteristiche intrinseche di
ciascun modello e quindi della fascia di mercato cui verrà destinato:
La
cronologia è quindi la seguente:
- 1978
: 8086
- 1979 : 8088
- 1982 : 80186
- 1982 : 80188
- 1982 : 80286
- 1985 : 386
- 1989 : 486
- 1993 : Pentium
- 1995 : Pentium Pro
- 1997 : Pentium II
- 1998 : Celeron - P6
- 1998 : Xeon - P6
- 1999 : Pentium III
- 2000 : Pentium 4
- 2001 : Xeon - Netburst
- 2002 : Celeron - Netburst
- 2003 : Pentium M
- 2004 : Celeron - Mobile
- 2006 : Core 2
- 2006 : Xeon - Core
- 2006 : Xeon - Mobile
- 2007 : Celeron - Core
- 2008 : Atom
- 2008 : Core i3, i5 & i7 - Nehalem
- 2009 : Xeon - Nehalem
- 2010 : Celeron - Nehalem
- 2011 : Core i3, i5 & i7 - Sandy Bridge
AMD: LA
CLONAZIONE
AMD è un nome importante da circa vent'anni, epoca nella quale cominciò a
produrre microprocessori su licenza Intel. Dopo tanti anni di rivalità Intel
domina ancora il mercato, ma la sua acerrima rivale non ha mai smesso di
lottare. L'inizio di questa rivalità, curiosamente, si deve ad un'altra azienda.
Nel 1981 Intel fu scelta da IBM come
fornitore di processori per il suo primo personal computer. L'azienda, però,
voleva due fornitori, così Intel si vide costretta a dare in licenza la sua
tecnologia, permettendo ad AMD di diventare la prima azienda autorizzata a
clonare il processore 8086. Il primo processore AMD, venduto nel 1981, era l'AMD
8086 (e 8088) identico in tutto e per tutto al modello Intel. Presentiamo ora
l'elenco dei cloni AMD (fonte:
http://www.tomshw.it/)
|
INTEL |
AMD |
descrizione |
|
8086 |
AMD 8086 |
|
|
80286 |
AM286 |
L'Am286 di AMD, un clone dell'Intel 80286 era identico al chip di Intel,
ma aveva un grande vantaggio: una frequenza più elevata. Mentre la CPU
286 di Intel lavorava a 12.5 MHz, AMD vendeva versioni a 20 MHz.
|
|
80386 |
AM386 |
Nel 1991, AMD presentò il processore 386. Come i
predecessori, questo modello era identico alla proposta di Intel,
giacché AMD aveva la licenza per produrre cloni di prodotti Intel,
partendo direttamente dal microcode (il firmware della CPU). Questo
processore aveva due caratteristiche interessanti. Era
più veloce della controparte Intel - 40 MHz rispetto a 33 MHz - ed era
la prima a fregiarsi del logo Windows
Compatible sul
package |
|
80486 |
AM486/AM586 |
Il 486 è stato l'ultimo clone di un processore Intel. AMD produceva il
486 in due versioni differenti, uno con microcode di Intel e uno con
microcode di AMD, quest'ultimo introdotto come conseguenza ad alcune
dispute con Intel su questo punto.
Oltre ai processori venduti sotto il nome 486, AMD mise in vendita anche
il 5x86, che era un 486 con un moltiplicatore di frequenza a 4x.
Lavorava a 133 MHz, era compatibile con le schede madre per 486, ma
aveva le prestazioni di un Pentium 75. |
|
PENTIUM |
K5 |
Nel 1996, AMD presentò la quinta generazione di processore, il K5.
Rispetto al Pentium, il K5 era tecnicamente più avanzato, ma aveva anche
alcuni punti deboli. Era interessante perché la sua architettura RISC
interna decodificava le istruzioni x86 in microistruzioni prima di
eseguirle.
Il K5 aveva difficoltà nel raggiungere frequenze elevate, e la sua unità
dedicata ai calcoli in virgola mobile (FPU) non molto prestante.
Nell'uso normale, tuttavia, il K5 era più veloce del Pentium. Il
suffisso PR, nel nome, non era solo una montatura - un K5 con frequenza
a 100 MHz veniva venduto come PR133, il che significava che AMD
considerava le sue prestazioni equivalenti a un Pentium con frequenza di
133 MHz. Il dissipatore e la ventola erano obbligatori, pur trattandosi
di dispositivi ancora poco comuni, all'epoca. |
|
PENTIUM II |
K6 |
Nel 1997 AMD presentò un nuovo processore: il K6. A differenza del K5,
il K6 era il risultato del lavoro fatto da NexGen sull'Nx686 . Questo
processore era compatibile con le schede madre Socket 7 (Pentium) e
offriva prestazioni molto buone rispetto ai processori Intel Pentium II,
ma ad un prezzo inferiore . L'unità floating point del K6 era ancora
debole rispetto a quella di Intel. Ne sono uscite 3 versioni. L'ultima
K6-III. Fu rimpiazzato dall'Athlon |
|
PENTIUM III |
K7 o Athlon |
Nel 1999 AMD presentò la settima generazione di processore, il K7, poi
rinominato Athlon . Questo chip non aveva i punti negativi dei modelli
precedenti, e finalmente integrava una FPU degna di esser chiamata tale,
persino migliore di quella di Intel.
L'Athlon era il processore x86 più veloce sulla piazza, e aveva molti
punti di forza , incluso un veloce FSB (EV6, usato nei primi processori
Alpha) e prestazioni elevate. L'unico problema reale non proveniva dal
processore ma dai chipset: né i modelli AMD né quelli VIA potevano
competere con i chipset Intel (come il famoso 440BX). Il K7 usava lo
Slot A (concorrente dello Slot 1 di Intel) e aveva una cache L2 con un
divisore variabile (1/2, 2/5 o 1/3). AMD è stata la prima ad annunciare
e a portare sul mercato un processore da 1 GHz con l'Athlon (due giorni
prima del Pentium III da 1 GHz). |
|
CELERON |
Sempron
e Duron |
I produttori di CPU, per qualche ragione, amano i nomi che finiscono con
"on". Per competere con il Celeron, AMD ha rivisitato il suo Athlon,
presentando il Duron, poi rimpiazzato dal Sempron.
Questi due processori a basso costo erano generalmente più lenti di un
Athlon e avevano un quantitativo di memoria cache inferiore. |
| |
K8 - Athlon |
Esce nel 2003. Il K8 è stato il primo processore x86 compatibile con
l'indirizzamento a 64-bit. L'architettura aveva altri vantaggi, come un
controller di memoria integrato. AMD presentò processori di grande
spessore, basati sull'architettura K8, ma ci concentreremo sui modelli
di fascia media, i famosi Athlon 64, dei quali gli Opteron (server), gli
Athlon 64 FX (fascia alta) e i Turion 64 (mobile) erano stretti parenti.
In generale, differivano solamente nell'amministrazione del controller
di memoria e della cache, più il tipo di memoria usata. |
|
CORE DUO |
Athlon 64X2 |
Nel 2005, AMD cambiò la sua architettura per offrire una versione dual
core del K8. Nacque così l'Athlon 64 X2. Nonostante fosse realizzato
impacchettando due core K8, l'architettura, con l'interfaccia
HyperTransport, permetteva buone prestazioni, a differenza delle
soluzioni Intel - E il primo processore dual core |
|
NEHALEM |
K10 -
Phenom extreme II |
Nel 2007, AMD ha presentato il core K10, commercializzato sotto il
marchio Phenom, che ha interrotto la serie positiva dell'azienda. Questo
processore non ha convinto: non è veloce come le controparti Intel,
aveva dei bug nelle prime revisioni (TLB), e non permetteva di salire
molto in overclock. Il Phenom, tuttavia, è ancora un buon processore:
l'architettura, per esempio, è ben concepita per il mondo server.
Anche se è considerato un processore a basso costo, il Phenom è ora
maturo e libero da alcuni problemi iniziali. |
In questo appunto, dopo una breve dissertazione sulla storia dei
processori, parleremo a fondo di uno dei molti scontri "ideologici" che hanno
costellato la storia dell'hardware: la "diatriba" tra approccio CISC e approccio
RISC alla progettazione dei processori.
L'evoluzione dei moderni processori è legata a tanti fattori, fra cui
compilatori buoni, raffinate tecniche litografiche per lo stampaggio dei
microcircuiti. Ma il fattore fondamentale, il più importante di tutti, è il
costo di tutto questo.
La storia dell'elettronica questo insegna:
l'evoluzione che ha portato dai calcolatori grossi come magazzini di un
supermercato fatti con valvole fino a quelli con milioni di transistor integrati
su un die (chip) di silicio di pochi millimentri quadrati è stata fatta grazie
all'abbattimento dei costi che le nuove tecnologie recavano con sè.
Partiamo per il nostro viaggio riassuntivo sulla storia del computer...
Iniziamo direttamente dagli anni '70, da quando cioè furono introdotti i primi
calcolatori basati su transistor altamente integrati, ed esaminiamo la
situazione hardware/software dell'epoca:
1) le memorie erano a nucleo (core) magnetico: in altri termini erano lente,
grosse e costosissime. Un esempio di memoria di questo tipo è dato dal
componente nella figura ( l'uomo tiene in mano un 'modulo di memoria' da qualche
centinaio di byte costituito da piccoli toroidi di materiale ferromagnetico e
dai fili che ne alteravano lo stato di magnetizzazione tramite corrente
elettrica).

2) esistevano i compilatori, ma facevano acqua da tutte le parti: il codice da
questi prodotto era poco ottimizzato e spesso talmente "sporco", cioè
inefficiente, che conveniva lavorare direttamente in assembler, spendendo ore ed
ore a scrivere codice che poi risultava difficile da correggere.
Definizione: In informatica, un
compilatore è un programma che traduce una serie di istruzioni scritte in un
determinato linguaggio di programmazione (codice sorgente) in istruzioni di un
altro linguaggio (codice oggetto di solito assembler). Questo processo di
traduzione si chiama compilazione.
3) i dispositivi di memoria secondaria (memorie di massa), anch'essi magnetici, erano ancora più
lenti e anch'essi molto costosi.
La conseguenza di tutto ciò è evidente: i
programmi dovevano essere molto semplici e molto compatti per risiedere in una
memoria dalle dimensioni di pochi Kbytes. Con l'avvento delle memorie dinamiche
a semiconduttore, a metà degli anni '70, la situazione migliorò un poco, ma
basta guardare la tabella in basso per avere un'idea dei costi.
|
Costo di 1 Mbit di memoria a semiconduttore (in $) |
150.000
|
50.000
|
10.000
|
800
|
240
|
60
|
10
|
1
|
0.25
|
0.11
|
|
Anno |
1974
|
1976
|
1979
|
1982
|
1985
|
1988
|
1991
|
1994
|
1997
|
2001
|
Lo stato di integrazione era di poche migliaia
di transistor su un singolo die (chip) di silicio, e per avere un dispositivo completo
di tutte le funzioni necessarie occorreva collegare più chip , ognuno con
mansioni diverse, sulla medesima scheda madre (ricordate che ancora una decina
di anni fa il 386 aveva bisogno del coprocessore matematico a parte per svolgere
i calcoli in virgola mobile?;-).
Splittare le mansioni su più chip, tenendo pure conto della limitazione di banda
dei bus, cioè delle piste di rame sulla scheda, introduceva ulteriori ritardi
nel trasferimento dei segnali digitali da una parte all'altra. (il problema si
è ripresentato in tempi recenti, da quando cioè si parla del collo di bottiglia
costituito dall'interfaccia memoria-chipset e chipset-processore, in cui le
centinaia di Mhz dei bus attuali finiscono per creare diafonia fra le varie
piste). Si avvertiva la necessità di impacchettare quanta più logica possibile
su un singolo chip, anzichè rivolgersi ad architetture distribuite. Il progresso
tecnologico sulla via della miniaturizzazione dei dispositivi condusse, nel
lontano 1971, al debutto del primo processore della Intel (Integrated
Electronics), 4004.
Per avere un termine di paragone
sull'importanza dell'integrazione, basti pensare che nelle missioni Apollo degli
anni '60, quelle che portarono gli americani sul suolo lunare, il computer
deputato al controllo di guida del razzo era composto da 5000 chip, ognuno a sua
volta composto da tre transistor e 4 resistenze! In breve ci si rese conto come
un microprocessore
fosse infinitamente superiore ad una struttura distribuita
per
una serie di ragioni che elencherò brevemente:
1) consuma di meno
2) produce meno calore e quindi richiede soluzioni meno raffinate per il
raffeddamento
3) occupa meno spazio
4) è più affidabile, cioè si guasta con meno frequenza rispetto ad una soluzione
cablata, perchè tutte le componenti interne nascono con lo stesso procedimento e
non esistono saldature che possano saltare
5) è più veloce perchè i segnali percorrono cammini più brevi e quindi si può
salire in frequenza.
6) è più economico da produrre su larga scala.
La situazione che si presentava ai progettisti degli anni '70 era allora chiara:
le memorie erano molto costose, i compilatori inefficienti e dunque perché non
cercare di rendere i computer più facilmente programmabili sfruttando le
emergenti tecnologie ad alta integrazione per fare chip sempre più
"intelligenti" in grado di eseguire in hardware istruzioni anche molto
complesse? Per capire meglio il senso di questa frase ricorriamo ad un semplice
esempio:
Programma in linguaggio generico di alto livello: prende un valore fornito
dall'utente, lo moltiplica per due e ne effettua il cubo.
B = 2 ;
C =CuboDi(B);
A cosa possa servire un tale programma non ci interessa; è qui messo solo a
scopo didattico. Quanto appena visto è il listato che un programmatore può
produrre. Il compilatore riceve la stringa di ingresso dei comandi impartiti e
produce in uscita lo stesso codice tradotto in linguaggio assembler, come
evidenziato in basso :
Lo stesso programma in linguaggio assembler:
MOV B,2; memorizza nel registro
B del processore il valore 2
MUL TEMP,B,B; moltiplica B per se stesso e salva il risultato in un registro
temporaneo
MUL C,TEMP,B; moltiplica TEMP per B e salva il risultato in C
Notiamo subito che l'operazione "elevamento al cubo" presente con un solo
comando nel linguaggio ad alto livello è stato "splittata" in due istruzioni
separate del linguaggio assembler ;
questo perchè il processore di riferimento,
che è il target del codice prodotto dall'assembler, non dispone in hardware
della funzione "cubo" ma deve ricorrere a due moltiplicazioni separate, e ad un
registro temporaneo di appoggio. In gergo si dice che 'ISA ( instruction set
architecture ) del processore, cioè l'insieme delle operazioni che quel
processore può eseguire, non contempla la funzione "cubo" . Di conseguenza, è
necessario decomporre la funzione cubo in operazioni più semplici che il
processore può esguire. Fin qui tutto semplice, ma sarebbe bello se il nostro
processore disponesse di un' ISA avanzato che contemplasse anche l'esecuzione di
un elevamento al cubo. Se tale funzione esistesse, l'assembler sarebbe
modificato in questo modo:
Lo stesso programma in linguaggio assembler con un ISA più potente:
MOV B,2; memorizza nel registro
B del processore il valore 2
CUB C,B; esegue il cubo di B e salva il risulato in C
Quelle che emergono in questo caso sono due conseguenze importanti:
1) il codice assembler è in corrispondenza 1-1 col codice ad alto livello;
pertanto è più compatto.
2) se c'è un errore nel programma, è più facile
scovarlo e porvi rimedio (fase di debugging più semplice). Il primo punto è noto
come chiusura del gap semantico fra il codice ad alto livello e il codice
assembler. Significa semplicemente che per ogni istruzione ad alto livello non
ne occorrono diverse in assembler più semplici, ma ne basta una.
CISC = Complex Instruction Set Computing
Una filosofia di questo tipo, in cui si cerca di avere un ISA che sia il più
flessibile possibile e che faciliti il debugging del codice prodotto dai
compilatori, è nota come approccio CISC al progetto di un microprocessore. CISC
è un acronimo e sta appunto per Complex Instruction Set Computing, cioè
architettura costituita da un insieme, o set, di istruzioni complesse. Fin qui
sembrerebbe tutto rosa e fiori: abbiamo solo aiutato i programmatori a scrivere
codice assembler più semplice, quindi più veloce da correggere, e abbiamo dunque
ovviato al grave problema del costo del debugging del software, che all'epoca
era molto sentito giacchè la memoria era assai costosa e il codice compilato
doveva essere il più possibile denso e ottimizzato. Già, ma il problema è che
abbiamo fatto in modo da demandare tutta la responsabilità della decodifica di
istruzioni complesse al microprocessore! Ricordate che vi ho detto prima
sull'Intel 4004? Che il suo ISA era costituito da 45 istruzioni soltanto. Negli
anni a venire si inserirono nell'ISA dei
nuovi processori general purpose come quelli
Intel e relativi cloni (AMD per intenderci) centinaia di nuove istruzioni.
Inoltre, ogni set di nuove istruzioni doveva essere retrocompatibile con quello
precedente, pena l'impossibilità da far girare i vecchi applicativi sui nuovi
processori. Il set ISA della famiglia Intel è noto come set 80x86 (o
semplicemente x86), perchè compatibile con i set di istruzioni del 8086, 80286,
80386 etc, fino ad arrivare all'attuale Pentium4. In breve, l'i7 è
progettato per far girare anche applicativi scritti 30 anni fa!
Ma torniamo a noi e ai prodromi dell'architettura CISC. All'epoca non esisteva
il concetto di una memoria veloce e piccola (l'odierna cache) da affiancare al
processore, e a causa del mantenimento della compatibilità con i vecchi ISA, la
maggior parte delle istruzioni prevedevano un sacco di accessi in lettura e
scrittura alla memoria di sistema, la
RAM, per intenderci . Vediamo di chiarire
le idee con un esempio: possiamo schematizzare la memoria di sistema come un array, cioè un insieme ordinato, di celle aventi una certa dimensione in byte.
Il processore è schematizzabile, per i nostri scopi, come un elemento che,
dietro i comandi impartiti da una logica di controllo, preleva i dati dalla
memoria centrale (fase di read o load), li elabora (fase di execute), e una
volta processati scrive i risulati finali (fase di write back o store)
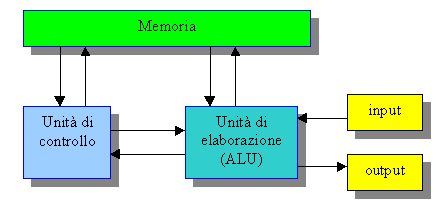
nuovamente in memoria. Questo schema descrive l'arcinota macchina di Von Neumann,
dal nome del cervellone che ideò lo schema base del funzionamento di un
calcolatore negli anni Quaranta. Potete pensare alla macchina di Von Neumann
come ad un tizio con un braccio solo: può eseguire una sola operazione alla
volta, prelevando documenti da uno scaffale, riordinandoli, e riporli
nuovamente nello scaffale una volta riordinati. La figura sottostante chiarisce
le idee :.
Il problema di una tale soluzione è che il
concetto di memoria è molto "nebuloso": un dispositivo di memorizzazione può
essere un registro (che funziona alla velocità di clock del processore in cui è
inglobato), una cache, una RAM di sistema o ,alla peggio, l'intero Hard Disk!
La maggior parte delle istruzioni CISC fanno uso di modalità di indirizzamento
complesso sempre nell'ottica di ridurre la dimensione del codice compilato. Un
esempio banale per capire l'approccio CISC all'uso della memoria: abbiamo due
valori immagazzinati in due celle di memoria, esempio la cella numero 100 e la
cella numero 230. Dobbiamo fare la moltiplicazione fra i contenuti delle due
celle e scrivere il risultato nella cella numero 300. Il modo di procedere
corretto sarebbe allora questo:
Codice assembler per l'operazione di moltiplicazione fra due valori
immagazzinanti in memoria centrale:
MOV A, %100; muovi (move) nel registro A il contenuto della cella 100
MOV B,%230; salva in un altro registro, detto B, il contenuto della cella 230
MUL C,A,B; moltiplica A per B e scrivi il risultato nel registro C
STR C, %300; scrivi (store) il valore di C nella cella numero 300
Osserviamo che, in totale, abbiamo 4 istruzioni in assembler. Troppe per i
progettisti, secondo la filosofia CISC. Perchè non fare una singola istruzione
di moltiplicazione che preveda tutte queste operazioni una volta decodificata
dal processore? Se venisse aggiunta nell'ISA del processore, basterebbe
scrivere:
MUL %300,%230,%100
per impartire l'ordine al processore di salvare il contenuto della memoria nei
registri, fare la moltiplicazione e scrivere il risultato nuovamente in
memoria. Bel risparmio di mal di testa per i programmatori in assembler! E bel
risparmio per la ditta produttrice di software che impiegherà molto meno tempo
per correggere eventuali bachi nel programma, portando al pubblico il prodotto
finito in tempi più rapidi!
Purtroppo, come si suol dire, non è tutto oro quello che luccica....
Tutto quello che abbiamo visto sui CISC è "molto bello", davvero, ma avviene a
scapito di un parametro: l'efficienza nella esecuzione del codice. Guardiamo
infatti a questa formula:
time/program = tempo programma = [ (instructions/program) x (cycles/instruction) x (time/cycle) ]
il membro a sinistra dell'uguaglianza è il parametro fondamentale che esprime
l'efficienza di un processore ad eseguire il dato programma. Più il time/program
è basso, meno tempo impiega la CPU a portare a termine il compito.
La filosofia CISC tende ad abbattere il termine instructions/program, cioè
il numero di
istruzioni che compongono il programma. Abbiamo già visto come abbiamo
effettuato una riduzione del 75%, portando il numero di istruzioni in assembler
da 4 ad 1 semplicemente aggiungendo una nuova istruzione all'ISA iniziale, nel
calcolo di un semplice prodotto! Il problema però è dato dal fatto che
l'aumento della complessità intrinseca ad ogni singola istruzione determina un
aumento del numero di cicli necessari per eseguire la singola istruzione e
la durata del singolo colpo di clock. Quindi tutta la fatica fatta per
semplificare l'assembler andrebbe a farsi benedire! Confusi?
Cerco di chiarirvi
le idee con un esempio estremo: posso fare in modo, al limite, di avere
pochissime istruzioni macchina che descrivano un intero programma, ma se poi
ogni istruzione richiede un giorno per essere decodificata ed eseguita, perchè
troppo complessa, ho peggiorato tutto!
I problemi dell'approccio CISC sono proprio questi:
1) le istruzioni contengono un sacco di store e load, cioè di accessi in
scrittura e lettura in e dalla memoria centrale la quale, essendo lenta, causa
un rallentamento complessivo del sistema.
2) le istruzioni sono tante, complesse, e vanno decodificate prima di poter
essere eseguite. E qui veniamo al secondo punto nel calcolo delle performance di
un microprocessore : il critical path, la direct execution e la ROM di
decodifica. Cominciamo da quest' ultime due:
La Direct Execution e la ROM di decodifica
Per esecuzione diretta, o direct execution, si intende la capacità del
processore di elaborare l'istruzione in linguaggio macchina senza doverla
decomporre in elementi più semplici (store, load,exec). Per esempio, l'istruzione MUL
%300,%230,%100 imponenva una serie di step da eseguire, fra cui tre accessi in
memoria, due in lettura (caricamento dei valori delle celle numero 230 e 100) e
uno in scrittura (archiviazione del valore del prodotto nella cella 300).
Insomma, un bel pò di roba! E tutto quanto deve essere sequenzializzato (in
gergo si parla di operazione di scheduling) nella giusta maniera. L'esecuzione
diretta prevede che le istruzioni vengano eseguite direttamente, senza una fase
di interpretazione delle medesime. Chiaramente, l'hardware deve essere assai
complesso per permettere al processore di lavorare in questa maniera. Siccome
l'ISA consiste di centinaia di istruzioni, più o meno diverse, è necessario un
approccio diverso al problema, in quanto eseguire direttamente istruzioni
diversissime fra di loro richiederebbe una quantità improponibile di transistor
sul die (chip) di silicio.
La soluzione sta in un trucco: il processore contiene all'interno un memoria a
sola lettura (una ROM, read only memory), che contiene la "traduzione" delle
istruzioni complesse in una sequenza di passi più semplici.
In altri termini, anzichè essere noi a fornire al processore istruzioni molto semplici ma numerose
in forma di assembler, è il processore medesimo che si preoccupa di "espandere"
le istruzioni complesse che gli forniamo noi in istruzioni "atomiche"
direttamente eseguibili dall'hardware. Questa operazione di decodifica, che si
appoggia su una ROM cablata all'interno del processore medesimo, è un punto
fondamentale dei processori CISC. Si può pensare di avere una sorta di CPU nella
CPU. Dove sta lo svantaggio? Beh, è evidente: se le istruzioni sono troppo
complesse la CPU spreca un sacco di cicli preziosi per decodificarle. Non solo:
la ROM è interna al processore, e dunque in un certo senso "ruba via" area di
silicio altrimenti destinabile all'incremento del numero dei registri o delle
unità di esecuzione (unità per eseguire l'addizione o la moltiplicazione fra
interi, oppure operazioni in virgola mobile). Infine: abbiamo detto che la
macchina di Von Neumann , che rappresenta il nostro processore CISC, è un pò
come un tizio con un solo braccio. Se l'accesso in lettura richiede molti cicli
per essere portato a termine, le unità di esecuzione stanno lì a girarsi i
pollici, perchè la macchina non è abbastanza ottimizzata da poter eseguire altre
operazioni mentre una istruzione viene decodificata. Non so se ve ne stiate
rendendo conto, ma stiamo elencando tutti i motivi che hanno portato alla
nascita del concetto di macchina RISC ;-) Chiarita la differenza fra esecuzione
diretta ed esecuzione previa decodificazione tramite ROM, passiamo al concetto
di critical path.
Il critical path
Chi è che stabilisce a quanto ammonta il clock di un processore? In altri
termini, come faccio a dire "questo processore può raggiungere i 700 MHz di
frequenza, mentre quest'altro riesce ad arrivare ad 1GHz"? Bella domanda! Se
cercate in giro per siti, leggete fino alla nausea che lo scaling dei transistor
verso dimensioni inferiori permette di raggiungere più alte frequenze nominali
di funzionamento (a tal proposito, date un'occhiata al mio articolo sulla SOI).
È tutto vero, ovviamente, ma la domanda resta senza risposta.
Come fanno gli
ingegneri di AMD a stabilire sulla carta che un dato processore può toccare
certe frequenze ? Siete ragazzi svegli, e avete intuito che la risposta sta
proprio nel titolo del paragrafo: il critical path, ossia il cammino critico.
Per cammino critico si intende il percorso più lungo che un segnale deve
attraversare nel tempo di un ciclo di clock. Se in qualche punto esiste un
percorso che un segnale impiega la bellezza di un microsecondo per percorrere,
il clock massimo per quel processore sarà di 1MHz (l'inverso di 1 microsecondo).
Non importa se la stragrande maggioranza degli altri segnali interni impiega per
esempio 1 nanosecondo (cioè un millesimo di microsecondo),
basta un segnale
lento per obbligare tutto il circuito ad andare alla sua velocità, che è quella
di 1Mhz al massimo! Inoltre, per problemi legati all'invecchiamento dei
componenti, alla deriva termica e al fatto che i transistor non sono mai così
precisi come sulla carta, occorre tenersi del margine di progettazione per cui
ad 1MHz il dispositivo non andrà mai (a meno che qualche esemplare
particolarmente ben riuscito adatto all'overclock non capiti nelle nostre
mani..;-). Cosa c'entra questo con il CISC? C'entra, perchè fra poco vedremo che
un sistema per ovviare al problema del critical path è la pipeline, che nascerà
con l'approccio RISC al design di un processore. Il fatto che un processore CISC, di principio, possa eseguire una sola istruzione alla volta, fa sì che la
parte di circuiteria coinvolta nello svolgimento dell'esecuzione più complessa
sia quella più lenta, e quindi finisca per fare da tappo alla performance del
processore . Tanto per fare un esempio, una moltiplicazione eseguita
direttamente, e non tramite successivi steps di addizione, resta tuttavia molto
più lenta di una semplice addizione. Anche se la moltiplicazione
(operazione lenta) capitasse una
volta ogni 'morte di papa' nel listato assembler, il processore dovrà comunque
tenerne conto e pertanto dovrà essere sufficientemente lento da permettere alla
moltiplicazione di avvenire senza problemi.
LA NASCITA DEL RISC
Alla fine degli anni Settanta e nei primi anni Ottanta la situazione era
cambiata: i compilatori erano divenuti molto più efficienti, le memorie meno
costose e i progettisti di microcomputer stavano scoprendo che la "panacea" data
dall'implementazione in hardware di istruzioni complicatissime e a volte
strampalate stava costituendo un tappo per il miglioramento delle performance.
Si cominciò allora a pensare ad un modo diverso di progettare un
microprocessore, e le linee guida di progetto possono essere così riassunte:
1) Sulla base di una analisi statistica dei programmi, si scopre che per il 90%
del tempo il processore utilizza sempre un ristretto sottoinsieme di istruzioni.
2) Perchè allora non ottimizzare il processore nell'esecuzione diretta di queste
poche istruzioni lasciando al compilatore l'onere di spezzettare le istruzioni
più rare e molto più complesse in task più semplici? In tal modo
torna in auge
il ruolo del compilatore e si può fare a meno della ROM di decodifica.
3) Non solo: se il processore è in grado di eseguire direttamente in modo
ottimizzato poche ma importanti istruzioni, facciamo in modo che ogni istruzione
venga completata in un solo ciclo di clock!!
4) Inoltre, l'esecuzione dei programmi è spesso rallentata dai ripetuti accessi
in memoria centrale ordinati dalle varie istruzioni con indirizzamento
complesso: decidiamo allora di fare tabula rasa di queste istruzioni e
stabiliamo che l'accesso in memoria avvenga esclusivamente tramite due comandi:
il load per il caricamento del dato dalla memoria al registro e lo store per la
scrittura dal registro alla memoria.
5) Per limitare gli accessi in memoria centrale devono essere limitati il più
possibile, occorre disporre sul chip di un consistente numero di registri per
avere un magazzino di informazione sufficientemente capiente da consentire
l'elaborazione dei dati . Questo insieme di registri è visibile al programmatore
in assembler che in tal modo produce un codice altamente ottimizzato per la
macchina che deve eseguire il programma.
Per capire meglio i punti 4) e 5) facciamo un esempio.
Prendiamo questo pezzo di
codice (che incrementa j e i da 0 a 100):
j=0;
for (i=0; i<100 ; i++)
j = j + i;
è scritto in C e dice grosso modo questo: ad ogni ciclo, aggiungi il valore
corrente di i a j e salva il risultato in j; fatto questo, incrementa i di una
unità e se raggiunge il valore 100 esci dal ciclo. Se il compilatore non è
scemo, è evidente che salva i e j in due registri locali e quindi effettua su di
essi le operazioni; solo a ciclo concluso salverebbe i risultati in memoria.
Un
processore CISC, però, il cui codice assembler è molto poco ottimizzato,
potrebbe benissimo prevedere invece una infinità di accessi e di scritture in
memoria centrale per prelevare e aggiornare i valori di i e j! (questo fa già
intuire come il compilatore in ultima analisi decide la bontà dei benchmark su
una macchina anzichè su un'altra, ma questo è un'altra storia che avrò piacere
di trattare in un'altra occasione;-).Tutto questo causerebbe un rallentamento
terribile delle prestazioni del sistema. Sorpresi? Beh, prima di fare un
riassunto su quanto esposto torniamo al "formulone" sul calcolo della
performance e facciamo qualche commento:
time/program = (instructions/program) x (cycles/instruction) x (time/cycle)
(instructions/program): un processore CISC tenta, come abbiamo visto, di
diminuire questa quantità. Un RISC, invece, accetta un peggioramento di questo
fattore.
(cycles/instruction): il processore RISC tende a portare questa quantità al
valore unitario ossia un istruzione eseguita per ogni ciclo di clock!
(time/cycle): il RISC tende a far diminuire anche questa quantità, che è in
sostanza legata al cammino critico discusso prima. Più breve è il critical path,
maggiore è la frequenza di clock sopportabile dal processore. Nasce il concetto
di pipeline: sfruttando la semplicità delle istruzioni RISC è possibile fare in
modo che i vari passi di cui esse sono composte vengano eseguiti in cascata su
più istruzioni sequenziali come in una catena di montaggio. Il risultato è la
possibilità di eseguire le istruzioni in un solo ciclo di clock che è stata a
lungo caratteristica unica dei processori RISC.
Inoltre i passi della pipeline
possono essere semplici e dotato di critical path basso con conseguenti elevate
velocità di clock.
Definizione:
PIPELINE. L'elaborazione di
un'istruzione da parte di un processore si compone di cinque passaggi
fondamentali:
1.IF (Instruction Fetch): Lettura dell'istruzione da memoria
2.ID (Instruction Decode): Decodifica istruzione e lettura operandi da registri
3.EX (Execution): Esecuzione dell'istruzione
4.MEM (Memory): Attivazione della memoria (solo per certe istruzioni)
5.WB (Write Back): Scrittura del risultato nel registro opportuno
Ogni CPU
in commercio è gestita da un clock centrale e ogni operazione elementare
richiede almeno un ciclo di clock per poter essere eseguita. Una CPU classica
richiedeva quindi almeno cinque cicli di clock per eseguire una singola
istruzione.
La pipeline dati è la massima parallelizzazione del lavoro di un
microprocessore. Una CPU con pipeline è composta da cinque stadi specializzati,
capaci di eseguire ciascuno una operazione elementare di quelle sopra descritte.
La CPU lavora come in una catena di montaggio e quindi ogni stadio provvede a
svolgere solo un compito specifico. Quando la catena è a regime, ad ogni ciclo
di clock esce dall'ultimo stadio un'istruzione completata. Nello stesso istante
ogni unità sta elaborando in parallelo i diversi stadi delle successive
istruzioni. In sostanza si guadagna una maggior velocità di esecuzione a prezzo
di una maggior complessità circuitale del microprocessore, che non deve essere
più composto da una sola unità ma da cinque unità che devono collaborare tra
loro
 |
| Esecuzione delle istruzioni in un microprocessore
senza pipeline |
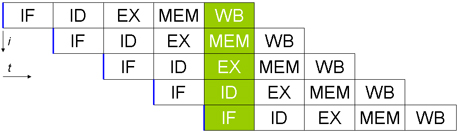 |
|
Esecuzione delle istruzioni in un microprocessore con pipeline |
Per rinfrescarvi le idee sulle differenze CISC-RISC, date un'occhiata a questa
tabella :
| |
Caratteristiche CISC |
Caratterisitiche RISC |
Approccio
fondamentale |
La
complessità si sposta dal codice all'hardware |
La
complessità si sposta dall'hardware al software, ovvero al compilatore
che deve essere molto efficiente |
|
Conseguenze della scelta per il programmatore |
Il codice è
molto compatto e occorre poca memoria per contenerlo; è l'hardware che
si incarica di decodificare istruzioni anche molto compatte e molto
complesse |
La
dimensione del codice aumenta in favore della semplificazione
dell'hardware. |
|
Conseguenze della scelta a livello hardware |
-Pochi
registri.
-Presenza di una ROM di decodifica.
-ISA molto articolato con centinaia di istruzioni.
-Modalità di indirizzamento memoria-memoria |
-Molti
registri
-Non esiste la modalità di indirizzamento memoria-memoria, ma alla
memoria si accede solo con il load e lo store
-ISA con qualche decina di istruzioni soltanto
-Direct execution
-Uso della pipeline per diminuire il ritardo del critical path. |
La tabella sovrastante fissa, a mio avviso, le
caratteristiche salienti delle due filosofie di progettazione . A questo punto,
cari lettori, vi starete probabilmente domandando:
ma l'Athlon o il Pentium4
sono CISC o RISC? La domanda non è banale, visto che in precedenza ho scritto
che il Pentium4 è obbligato, per ragioni di retrocompatibilità, a eseguire il
vecchio codice ISA a 8 e 16 bit. Poichè l'ISA della Intel è stato concesso in
licenza ad AMD e a Transmeta, anche l'Athlon e il Crusoe devono potere eseguire
le medesime operazioni e quindi complessivamente si parla di piattaforme x86. .
Come venga poi effettivamente eseguito il codice x86, beh, a questo punto ognuno
segue ciò che ritiene sia la strada migliore e più performante. La situazione è
così schematizzabile :
Se il Pentium o l'Athlon (o quello che è)
sono ancorati alla decodifica di un
set di istruzioni arcaico e complicato come quello x86, dovrebbero essere
considerati processori CISC, quindi poco performanti...eppure, sappiamo bene che
l'Athlon ha una struttura a pipeline composta da ben 10 stadi, è superscalare ed
ha un sacco di "chicche" in più! Così anche il P4 che di stadi nè ha addirittura
20. Quindi dovrebbero essere RISC, secondo la tabella di cui sopra! Insomma ,CISC
o RISC? La risposta è: entrambi! Confusi? Avete motivo di esserlo. Ma adesso
cercherò di chiarirvi le idee.
L'architettura
interna dei processori general purpose odierni, quali appunto il Pentium4 e l'Athlon, ha poco o nulla a che
vedere con l'approccio CISC descritto in precedenza. Infatti, essi sono ancorati
al passato solo perchè devono essere retrocompatibili con i vecchi programmi e
dunque con le obsolete istruzioni ISA che questi vecchi programmi utilizzavano.
Il codice x86 è un codice "brutto", frammentato, disomogeneo, e il fatto che sia
riuscito a sopravvivere per quasi trent'anni costituisce la prova de facto
dell'importanza della backward compatibility per il successo delle macchine
Intel e suoi cloni. Se la stessa Intel decide per la prima volta nella sua
storia di buttare a mare il codice sulla quale essa ha costruito la sua fortuna
commerciale, optando per la nuova piattaforma IA64 dell'Itanium, vuol dire che
l'ISA x86 è veramante giunto al capolinea della sua corsa e che sono finiti i
trucchi tecnologici che possono mantenerla ancora in vita.
Il K7 o il P4 possono essere considerati come dei processori che offrono un'
interfaccia CISC al codice ISA che devono eseguire (accettano cioè senza
problemi le istruzioni ISA che il programma corrente genera)
ma, una volta decodificate le istruzioni, il risultato di tale decodifica viene "digerito" da
una serie di stadi di elaborazione che nel loro insieme costituiscono in tutto e
per tutto un processore RISC. La figura seguente chiarisce le idee
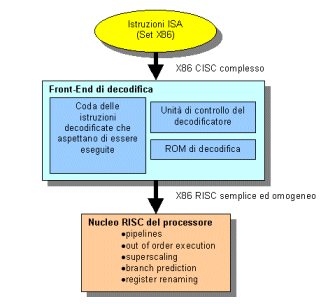
I commenti che si possono fare sono i seguenti:
1) Il codice ISA x86 complesso (nel senso di tante istruzioni di natura diversa)
e disomogeneo (nel senso che alcune istruzioni sono lunghe 8 bit, altre 16 e
quelle degli applicativi più recenti 32 bit) viene decodificato secondo lo
schema già studiato: una ROM contiene la corrispondenza fra le istruzioni
complesse e quelle più semplici omogenee. L'unità di controllo è il regista
dell'operazione di decodifica.
2) Alle poche compatte istruzioni ISA x86 vengono sostituite le più numerose
istruzioni di formato omogeneo (a 32 bit) che possono essere quindi immesse in
una memoria tampone (buffer) in attesa di venire processate dalle unità di
elaborazione più a valle. Le istruzioni decodificate sono RISC-like, nel senso
che appartengono ad un "alfabeto" meno ricco del codice nativo ISA x86 ma
altamente ottimizzato per essere convenientemente compreso dalla circuiteria
preposta al suo trattamento.
3) Queste istruzioni Risc-like possono allora essere manipolate secondo quanto
di meglio la tecnologia odierna possa offrire.
Conclusione
Dopo quanto detto è abbastanza evidente come nello scontro CISC vs RISC sia
stata quest'ultima filosofia ad aver avuto la meglio. Di processori RISC
oggigiorno ne abbiamo piene le letteralmente le tasche: dai palmari ai cellulari
della prossima generazione, Oggi ogni processore che voglia essere snello e al
contempo potente nasce sotto l'effige del RISC (Tranmeta Crosue è un caso
particolare di cui parleremo in altra sede). Gli stessi processori x86, come
abbiamo visto hanno assimilato il paradigma RISC unica e vincente mossa che ne
ha prorogato la vita oltre ogni rosea aspettativa. Del resto il percorso di
sviluppo delle capacità di un processore non si ferma a quello che abbiamo
detto. Quindi i microprocessori Intel integrano all'interno un'architetture RISC
che utilizza uno strato di emulazione per eseguire il codice x86 che è di tipo
CISC.
L'obiettivo di qualsiasi progettista di processori è quello di ottenere sempre
il max throughput complessivo, cioè ,detto in italiano (cara vecchia lingua!),
il massimo volume di dati processati e consegnati in uscita nell'unità di tempo.
Come conseguire il massimo rendimento? la parola d'ordine in questi casi è
parallelismo. Il parallelismo è stato il passo successivo compiuto dalla
tecnologia dei processori dopo l'affermazione del RISC. Questo si esplica
principalmente in due modalità differenti all'interno di un singolo processore:
il pipelining (già illustrato) e il superscaling (superscalare).
Un'altra tecnica di ottimizzazione delle risorse è il multithreading, che
come scuola di pensiero ha pochi anni alle spalle ma già promette interessanti
innovazioni.
DEFINIZIONE:
SUPERSCALARE:
Una macchina superscalare contiene più unità di esecuzione capaci di
lavorare contemporaneamente. Questo consente al processore di eseguire
concorrentemente più istruzioni inviando ciascuna istruzione all’unità di
esecuzione disponibile in quell’istante. Ad esempio una macchina superscalare
con due unità aritmetiche può sommare due coppie di numeri contemporaneamente,
posto che i risultati non debbano andare nella stessa locazione. Un
instruction set tipico di una macchina RISC si adatta bene a macchine
superscalari poiché le unità di esecuzione occupano meno spazio sul chip e
possono, di conseguenza, essere replicate una o più volte. Le macchine
superscalari sono indicate nel caso in cui le dipendenze tra istruzioni siano
ridotte al minimo.
In
una CPU superscalare
sono presenti diverse unità funzionali dello stesso tipo, con dispositivi
addizionali per distribuire le istruzioni alle varie unità. Per esempio, sono
generalmente presenti numerose unità per il calcolo intero (definite ALU).
Le unità di controllo stabiliscono quali istruzioni possono essere eseguite in
parallelo e le inviano alle rispettive unità. Questo compito non è facile, dato
che un'istruzione può richiedere il risultato della precedente come proprio
operando, oppure può dover impiegare il dato conservato in un registro usato
anche dall'altra istruzione; il risultato può quindi cambiare secondo l'ordine
d'esecuzione delle istruzioni. Pentium è un esempio di processore superscalare.
Una macchina Superscalare può essere
intesa come una Multipipelining
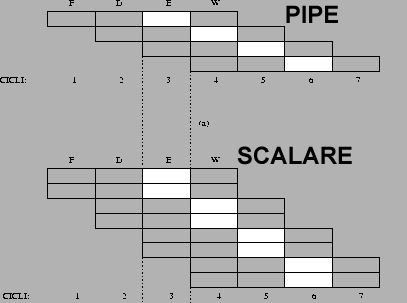
DEFINIZIONE: La tecnologia HyperThreading (o Hyper-Threading,
sigla HT,
tradotto HyperFlots o HyperFlux)
consiste nel definire due processori software all'interno di un processore
hardware. Così, il sistema
riconosce due processori hardware e si comporta come un sistema multitask
inviando due thread simultanei, si parla allora di SMT (Simultaneous
Multi Threading). Questa « astuzia » permette di utilizzare al meglio le
risorse del processore garantendo che i dati gli siano inviati in massa.
Ecco l'elenco delle CPU con il socket utilizzato
|
Nome del Socket |
Anno di fabbricazione |
Modello CPU |
Package |
Nr Pin |
Bus speed |
|
DIP |
1970s |
Intel 8086
Intel 8088 |
DIP |
40 |
5/10 MHz |
|
PLCC |
? |
Intel 80186
Intel 80286
Intel 80386 |
PLCC |
68, 132 |
6-40 MHz |
|
Socket
1 |
1989 |
Intel 80486 |
PGA |
169 |
16-50 MHz |
|
Socket
2 |
? |
Intel 80486 |
PGA |
238 |
16-50 MHz |
|
Socket
3 |
1991 |
Intel 80486 |
PGA |
237 |
16-50 MHz |
|
Socket
4 |
? |
Intel Pentium |
PGA |
273 |
60-66 MHz |
|
Socket
5 |
? |
Intel Pentium
AMD K5 |
PGA |
320 |
50-66 MHz |
|
Socket
6 |
? |
Intel 80486 |
PGA |
235 |
? |
|
Socket
7 |
1994 |
Intel Pentium
Intel Pentium MMX
AMD K6 |
PGA |
321 |
50-66 MHz |
|
Super Socket 7 |
1998 |
AMD K6-2
AMD AMD K6-III
Rise mP6
Cyrix
MII |
PGA |
321 |
66-100 MHz |
|
Socket
8 |
1995 |
Intel Pentium Pro |
PGA |
387 |
60-66 MHz |
|
Slot 1 |
1997 |
Intel Pentium II
Intel Pentium III |
Slot |
242 |
66-133 MHz |
|
Slot 2 |
1998 |
Intel Pentium II Xeon |
Slot |
330 |
100-133 MHz |
|
Slot A |
1999 |
AMD
Athlon |
Slot |
242 |
100 MHz |
|
Socket
370 |
1999 |
Intel Pentium III
Intel Celeron
VIA
Cyrix III
VIA
C3 |
PGA |
370 |
66-133 MHz |
Socket
462/
Socket A |
2000 |
AMD Athlon
AMD Duron
AMD Athlon XP
AMD Athlon XP-M
AMD Athlon MP
AMD Sempron |
PGA |
462 |
100-200 MHz
|
|
Socket
423 |
2000 |
Intel Pentium 4 |
PGA |
423 |
400 MT/s (100 MHz) |
Socket
478/
Socket N |
2000 |
Intel Pentium 4
Intel Celeron
Intel Pentium 4 EE
Intel Pentium 4 M |
PGA |
478 |
400-800 MT/s
(100-200 MHz) |
|
Socket
495 |
2000 |
Intel
Celeron |
PGA |
495 |
? |
|
PAC418 |
2001 |
Intel
Itanium |
PGA |
418 |
133 MHz |
|
Socket
603 |
2001 |
Intel
Xeon |
PGA |
603 |
400-533 MT/s
(100-133 MHz) |
|
PAC611 |
2002 |
Intel Itanium 2 |
PGA |
611 |
? |
|
Socket
604 |
2002 |
Intel
Xeon |
PGA |
604 |
400-1066 MT/s
(100-266 MHz) |
|
Socket
754 |
2003 |
AMD Athlon 64
AMD Sempron
AMD Turion 64 |
PGA |
754 |
200-800 MHz |
|
Socket
940 |
2003 |
AMD
Opteron
Athlon 64 FX |
PGA |
940 |
200-1000 MHz |
|
Socket
479 |
2003 |
Intel Pentium M
Intel
Celeron M |
PGA |
479 |
400-533 MT/s
(100-133 MHz) |
|
Socket
939 |
2004 |
AMD Athlon 64
AMD Athlon 64 FX
AMD Athlon 64 X2
AMD Opteron |
PGA |
939 |
200-1000 MHz |
LGA
775 o
Socket T |
2004 |
Intel Pentium 4
Intel Pentium D
Intel Celeron
Intel Celeron D
Intel Pentium XE
Intel Core 2 Duo
Intel Core 2 Quad
Intel Xeon |
LGA |
775 |
1600 MHz |
|
Socket
563 |
? |
AMD Athlon
XP-M |
PGA |
563 |
? |
|
Socket
M |
2006 |
Intel Core Solo
Intel Core Duo
Intel Dual-Core
Xeon
Intel Core 2 Duo |
PGA |
478 |
533 - 667 MT/s
(133-166 MHz) |
LGA
771 o
Socket J |
2006 |
Intel Xeon |
LGA |
771 |
1600 MHz |
|
Socket
S1 |
2006 |
AMD Turion 64 X2 |
PGA |
638 |
200-800 MHz |
|
Socket
AM2 |
2006 |
AMD Athlon 64
AMD Athlon 64 X2 |
PGA |
940 |
200-1000 MHz |
|
Socket
F |
2006 |
AMD Athlon 64 FX
AMD Opteron |
LGA |
1207 |
? |
|
Socket
AM2+ |
2007 |
AMD Athlon 64
AMD Athlon X2
AMD Phenom |
PGA |
940 |
200-2600 MHz |
|
Socket
P |
2007 |
Intel Core 2 |
PGA |
478 |
533-1066 MT/s
(133-266 MHz) |
|
Socket
441 |
2008 |
Intel Atom |
PGA |
441 |
400-667 MHz |
LGA
1366/
Socket B |
2008 |
Intel Core i7 (900 series) |
LGA |
1366 |
4.8-6.4 GT/s |
|
Socket
AM3 |
2009 |
AMD Phenom II
AMD Athlon II
AMD Sempron |
PGA |
941[14] |
200-3200 MHz |
LGA
1156 o
Socket H |
2009 |
Intel Core i7 (800 series)
Intel Core i5 (700, 600 series)
Intel Core i3 (500 series)
Intel Xeon (X3400, L3400 series)
Intel Pentium (G6000 series)
Intel Celeron (G1000 series) |
LGA |
1156 |
2.5 GT/s |
|
Socket
G34 |
2010 |
AMD Opteron (6000 series) |
LGA |
1974 |
200-3200 MHz |
|
Socket
C32 |
2010 |
AMD Opteron (4000 series) |
LGA |
1207 |
200-3200 MHz |
La tabella sottostante evidenzia come lo stesso
modello subisca nel tempo una notevole evoluzione:
|
Nome Commerciale |
Data |
Socket |
Clock |
Molt. |
Pr.Prod. |
Voltag. |
Watt |
Bus |
Cache |
XD |
64 |
HT |
ST |
VT |
Core |
|
Pentium 4 1,3 GHz |
03/gen/2001 |
423 |
1,3 GHz |
13x |
180 nm
42 mil. |
1,75 V |
50 W |
400
MHz |
L1=8KB
L2=256KB
L3=0KB |
No |
No |
No |
No |
No |
Willamette |
|
Pentium 4 1,4 GHz |
20/nov/2000 |
1,4 GHz |
14x |
53 W |
|
Pentium 4 1,5 GHz |
1,5 GHz |
15x |
56 W |
|
Pentium 4 1,6 GHz |
02/lug/2001 |
1,6 GHz |
16x |
61 W |
|
Pentium 4 1,7 GHz |
23/apr/2001 |
1,7 GHz |
17x |
64 W |
|
Pentium 4 1,8 GHz |
02/lug/2001 |
1,8 GHz |
18x |
67 W |
|
Pentium 4 1,9 GHz |
27/ago/2001 |
1,9 GHz |
19x |
69 W |
|
Pentium 4 2,0 GHz |
2,0 GHz |
20x |
72 W |
|
Pentium 4 1,4 GHz |
set/2001 |
478 |
1,4 GHz |
14x |
55 W |
|
Pentium 4 1,5 GHz |
ago/2001 |
1,5 GHz |
15x |
58 W |
|
Pentium 4 1,6 GHz |
1,6 GHz |
16x |
61 W |
|
Pentium 4 1,7 GHz |
1,7 GHz |
17x |
63 W |
|
Pentium 4 1,8 GHz |
1,8 GHz |
18x |
66 W |
|
Pentium 4 1,9 GHz |
1,9 GHz |
19x |
73 W |
|
Pentium 4 2,0 GHz |
2,0 GHz |
20x |
75 W |
|
Pentium 4 1,6 GHz A |
27/ago/2001 |
1,6 GHz |
16x |
130 nm
55 mil. |
1,525 V |
47 W |
L1=8KB
L2=512KB
L3=0KB |
Northwood |
|
Pentium 4 1,8 GHz A |
1,8 GHz |
18x |
50 W |
|
Pentium 4 2,0 GHz A |
2,0 GHz |
20x |
54 W |
|
Pentium 4 2,2 GHz |
7/gen/2002 |
2,2 GHz |
22x |
57 W |
|
Pentium 4 2,4 GHz |
02/apr/2002 |
2,4 GHz |
24x |
60 W |
|
Pentium 4 2,5 GHz |
26/ago/2002 |
2,5 GHz |
25x |
61 W |
|
Pentium 4 2,6 GHz |
2,6 GHz |
26x |
63 W |
|
Pentium 4 2,267 GHz |
06/mag/2002 |
2,267 GHz |
17x |
58 W |
533
MHz |
|
Pentium 4 2,4 GHz B |
2,4 GHz |
18x |
60 W |
|
Pentium 4 2,533 GHz |
2,533 GHz |
19x |
61 W |
|
Pentium 4 2,667 GHz |
26/ago/2002 |
2,667 GHz |
20x |
66 W |
|
Pentium 4 2,8 GHz |
2,8 GHz |
21x |
68 W |
|
Pentium 4 3,06 GHz |
14/nov/2002 |
3,06 GHz |
23x |
1,55 V |
82 W |
Sì |
|
Pentium 4 2,4 GHz C |
21/mag/2003 |
2,4 GHz |
12x |
1,525 V |
66 W |
800
MHz |
|
Pentium 4 2,6 GHz C |
2,6 GHz |
13x |
69 W |
|
Pentium 4 2,8 GHz C |
2,8 GHz |
14x |
70 W |
|
Pentium 4 3,0 GHz |
14/apr/2003 |
3,0 GHz |
15x |
1,55 V |
82 W |
|
Pentium 4 3,2 GHz |
23/giu/2003 |
3,2 GHz |
16x |
|
Pentium 4 3,4 GHz |
2/feb/2004 |
3,4 GHz |
17x |
84 W |
|
Pentium 4 2,4 GHz A |
2,4 GHz |
18x |
90 nm
125 mil. |
1,4 V |
89 W |
533
MHz |
L1=16KB
L2=1MB
L3=0KB |
Prescott |
|
Pentium 4 2,8 GHz A |
2,8 GHz |
21x |
|
Pentium 4 2,8 GHz E |
2,8 GHz |
14x |
800
MHz |
|
Pentium 4 3,0 GHz E |
3,0 GHz |
15x |
|
Pentium 4 3,2 GHz E |
3,2 GHz |
16x |
|
Pentium 4 3,4 GHz E |
3,4 GHz |
17x |
|
Pentium 4 3,2 GHz EE |
03/nov/2003 |
3,2 GHz |
16x |
130 nm
178 mil. |
1,55 V |
92 W |
L1=8KB
L2=512KB
L3=2MB |
Gallatin |
|
Pentium 4 3,4 GHz EE |
02/feb/2004 |
3,4 GHz |
17x |
1,6 V |
103 W |
|
Pentium 4 505 |
21/giu/2004 |
775 |
2,667 GHz |
20x |
90 nm
125 mil. |
1,4 V |
84 W |
533
MHz |
L1=16KB
L2=1MB
L3=0KB |
Prescott |
|
Pentium 4 515 |
2,933 GHz |
22x |
|
Pentium 4 520 |
2,8 GHz |
14x |
800
MHz |
|
Pentium 4 530 |
3,0 GHz |
15x |
|
Pentium 4 540 |
3,2 GHz |
16x |
|
Pentium 4 550 |
3,4 GHz |
17x |
|
Pentium 4 560 |
3,6 GHz |
18x |
115 W |
|
Pentium 4 520 J |
15/nov/2004 |
2,8 GHz |
14x |
84 W |
Sì |
|
Pentium 4 530 J |
3,0 GHz |
15x |
|
Pentium 4 540 J |
3,2 GHz |
16x |
|
Pentium 4 550 J |
3,4 GHz |
17x |
|
Pentium 4 560 J |
3,6 GHz |
18x |
115 W |
|
Pentium 4 570 J |
3,8 GHz |
19x |
|
Pentium 4 521 |
28/giu/2005 |
2,8 GHz |
14x |
84 W |
Sì |
|
Pentium 4 531 |
3,0 GHz |
15x |
|
Pentium 4 541 |
3,2 GHz |
16x |
|
Pentium 4 551 |
3,4 GHz |
17x |
|
Pentium 4 561 |
3,6 GHz |
18x |
115 W |
|
Pentium 4 571 |
3,8 GHz |
19x |
|
Pentium 4 524 |
11/mag/2006 |
3,06 GHz |
23x |
84 W |
533
MHz |
|
Pentium 4 3,4 GHz EE |
21/giu/2004 |
3,4 GHz |
17x |
130 nm
178 mil. |
1,6 V |
110 W |
800
MHz |
L1=8KB
L2=512KB
L3=2MB |
No |
No |
Gallatin |
|
Pentium 4 3,46 GHz EE |
15/nov/2004 |
3,46 GHz |
13x |
111 W |
1066
MHz |
|
Pentium 4 630 |
21/feb/2005 |
3,0 GHz |
15x |
90 nm
168 mil. |
1,4 V |
84 W |
800
MHz |
L1=16KB
L2=2MB
L3=0KB |
Sì |
Sì |
Sì |
Prescott |
|
Pentium 4 640 |
3,2 GHz |
16x |
|
Pentium 4 650 |
3,4 GHz |
17x |
|
Pentium 4 660 |
3,6 GHz |
18x |
115 W |
|
Pentium 4 3,73 GHz EE |
3,73 GHz |
14x |
1066
MHz |
|
Pentium 4 670 |
27/mag/2005 |
3,8 GHz |
19x |
800
MHz |
|
Pentium 4 662 |
15/nov/2005 |
3,6 GHz |
18x |
Sì |
|
Pentium 4 672 |
3,8 GHz |
19x |
|
Pentium 4 631 |
16/gen/2006 |
3,0 GHz |
15x |
65 nm
168 mil. |
1,3 V |
86 W |
No |
Cedar Mill |
|
Pentium 4 641 |
3,2 GHz |
16x |
|
Pentium 4 651 |
3,4 GHz |
17x |
|
Pentium 4 661 |
3,6 GHz |
18x |
BIOS
Il BIOS, acronimo di Basic Input Output System
(Sistema di base per l'immissione/emissione dati), è uno speciale software
residente in una memoria di tipo Flash ROM (memoria scrivibile solo con certi
livelli di tensione).
Questo chip contiene una serie di istruzioni per il microprocessore del PC con
un codice che viene eseguito automaticamente all'accensione del computer. Il
BIOS si incarica di eseguire una procedura di autodiagnostica (POST, Power On
Self Test) che procede a tutta una serie di controlli e verifiche sulla memoria
RAM, tastiera, processore, drive, disco fisso, porte di comunicazione e che
permette, infine, di caricare il sistema operativo da floppy disk o da hard
disk. Affinchè il BIOS possa eseguire correttamente il suo compito, necessita
di conoscere l'hardware installato nel personal computer e la sua
configurazione. Tutti i parametri di configurazione e setup (settaggio)
necessari al funzionamento del BIOS e del computer, sono registrati su di una
memoria chiamata RAM Cmos (una memoria a bassissimo consumo di appena 64 Kb) che
rimane costantemente alimentata. Quando il PC è spento, tale alimentazione
viene garantita da una piccola batteria tampone presente sulla scheda madre. Ne
consegue che un esaurimento di questa batteria provocherà la perdita dei dati
contenuti nella RAM Cmos, con inevitabili problemi all' avvio della macchina e
la necessità di riconfigurare il setup dopo aver sostituito la batteria.

Se la
RAM Cmos
non fosse sempre alimentata, ad ogni accensione della la macchina, bisognerebbe
sempre inserire alcuni dati come la data, l'ora, il tipo di periferiche
installate (hard disk, cd-rom, floppy disk, ...), ecc, informazioni che servono
al sistema per funzionare e questo comporterebbe tempi di caricamento molto più
lunghi. Per contenere questo programma e per evitare
la sua involontaria cancellazione é stato scelto di inserirlo in memorie di
tipo Eprom, che possono essere cancellate solo con sofisticati metodi che non
descriveremo per non entrare troppo nello specifico.
Se la scheda madre è equipaggiata
con un BIOS su Flash ROM riprogrammabile, esiste la possibilità di aggiornarlo
periodicamente con nuove versioni sviluppate dai produttori di schede. Il
software è prelevabile via - Internet presso il sito del produttore.
L'aggiornamento del BIOS offre sicuramente dei vantaggi, ma
può comunque
comportare dei problemi.
Una improvvisa assenza della tensione di alimentazione
durante l'aggiornamento o un inadatto file di upgrade possono produrre
conseguenze molto serie. In questi casi ci troveremmo ad avere
una scheda madre
priva di BIOS e quindi assolutamente inutilizzabile. Sarebbe necessario
dissaldare il chip e riprogrammarlo con un programmatore esterno con costi
abbastanza alti paragonabili al valore della motherboard stessa. Per evitare cataclismi
di questo tipo è bene, prima di procedere all'aggiornamento, fare delle copie
si sicurezza del BIOS di serie usando il software fornito con la scheda madre
onde evitare che una volta sostituito venga eliminato per sempre. Su alcune
schede è presente un jumper che opportunamente impostato consente o meno di
sovrascrivere sul chip.

Nel 1996 l'avvio del
sistema è diventato unico poiché le diverse aziende produttrici di HW decisero di adottare lo
standard BIOS Boot
Specification. A tutt’oggi questo standard
definisce come i sistemi operativi interni al
sistema (i bootstrap loader)
avviano l’OS vero e proprio.
Anche se i sistemi
operativi vengono dotati costantemente di nuove opzioni grafiche, il BIOS rimane
sempre uguale. Questo perchè i produttori non vogliono che l’utente metta mano
al Bios e questo per evitare che
possa combinare guai. Il nuovo BIOS EFI supporta il sistema operativo a 64 bit,
possiede una nuova interfaccia grafica ma purtroppo ci sono ancora pochissimi PC
dotati di EFI, poichè mancano le schede madri compatibili. Solo Apple lo
utilizza dal 2006.
Esistono tre produttori di bios:
-
PHOENIX BIOS
-
AMI BIOS
-
AWARD BIOS
Il setup del BIOS
Come già specificato, i parametri
relativi alla configurazione del PC ai quali fa riferimento il BIOS sono
contenuti in una memoria RAM Cmos. Per cambiare questi dati è necessario
entrare nel BIOS Setup, un programma che consente di vedere e cambiare la
configurazione del computer. Attenzione! Alterare questi parametri in modo
errato porterebbe al blocco del PC!
Non entrate nel BIOS Setup se non
siete all'altezza o se non siete abbastanza pratici.
Generalmente
si entra nel BIOS
Setup premendo una combinazione di tasti [solitamente
il Del],
appena dopo aver acceso il PC, quando compare un messaggio specifico sul monitor.
(Ad esempio : Hit <DEL> if
you want to run SETUP).
 |
|
SETTAGGI PRINCIPALI DEL BIOS
Per accedere al BIOS bisogna premere il tasto
Del (o Canc) all'avvio del computer. Una volta entrati in questo
piccolo programma viene visualizzato un menù
che riassume le
parti fondamentali in cui é diviso il programma.
|
|
N.B. : non
tutti i bios sono fatti in questo modo, perché esistono diverse case che li
producono; perciò, nel vostro BIOS, potreste non avere alcuni dei parametri
sopracitati oppure averne alcuni non presenti in questa pagina.
Ed ora vediamo alcuni di questi menu in dettaglio:
MAIN MENU:
In questa sezione si impostano l'ora e la data, si indicano le caratteristiche
degli hard disk eventualmente presenti, il tipo di floppy drive
installato (ormai in disuso). I parametri degli hard disk vengono riconosciuti automaticamente,
durante la fase di POST. Anche il lettore di DVD è riconosciuto automaticamente.
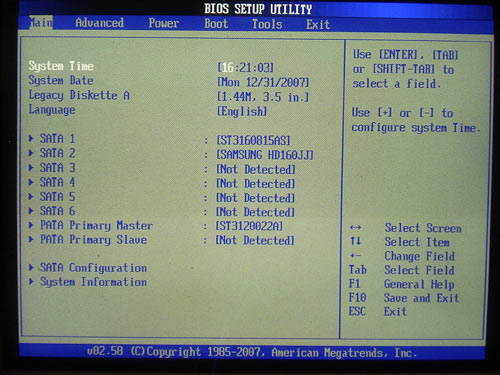
ADVANCED MENU:
In questa sezione
si impostano parametri della CPU, del Chipset, porta USB, il plug and play.
vediamo alcuni sottomenu in dettaglio
 |
Configurazione della CPU:
Execute Disable Bit: consente al processore di
classificare aree in memoria in cui il codice può essere eseguito e
altre in cui non può essere eseguito. Quando un worm nocivo tenta di
inserire il codice nel buffer, il processore disattiva l'esecuzione di
tale codice per impedire danni o la propagazione del worm.
- CPU Ratio Settings è un moltiplicatore fra la frequenza di FSB e
quella di funzionamento della CPU. Molto utile per tutti gli
overclockers ma funzionante solo su processori che abbiano il
moltiplicatore non bloccato dalla casa costruttrice. |
 |
Configurazione
del chipset (north e south bridge più la configurazione delle eventuali
periferiche installate sulla motherboard) |
 |
configurazione delle periferiche "On-board"
come scheda audio, Scheda LAN, porte seriali e firewire |
 |
configurazione del controller USB
Legacy USB Support: questa opzione consente
di vedere un mouse o una tastiera usb come se fossero periferiche legacy
(ps2) e quindi visibili a quei sistemi operativi che non supportano usb
(come il dos ad esempio). |
 |
Abilitazione
del Plug and Play e configurazione del Bus PCI.
Clear NVRAM: Nella NVRAM (memoria non volatile),
sono memorizzati i dati più importanti del Bios (configurazione degli
interrupt). Essa non necessità di alimentazione, (come la CMOS), e può
essere modificata da Windows o da un VIRUS.
Pci IDE busmaster: è una gestione del bus pci mediante la quale il controller del disco, che è connesso al bus pci,
mantiene l'uso esclusivo del bus per un numero prefissato di cicli senza
chee le altre periferiche possano interromperlo. Questa gestione
migliora la velocità globale in lettura e scrittura (e quindi le
performance), ma potrebbe portare anche a piccoli rallentamenti su
applicazioni che non hanno bisogno di grosse quantità di dati, ma che
richiedono continuità nel flusso in lettura (o scrittura) dei dati.
Palette Snooping: consente
ad una scheda MPEG ISA di
acquisizione video di funzionare deve accedere al frame buffer di una
PCI/AGP scheda video VGA
PCI Latency Timer: è' il numero massimo di cicli in cui una periferica
PCI può occupare il bus PCI.
Allocate IRQ ti PCI VGA: Se abilito questa voce un IRQ verrà assegnato
alla scheda grafica PCI VGA
|
POWER MENU:
In questo menu è
possibile consultare una serie di parametri legati al consumo
energetico. Inoltre permette di specificare le opzioni relative al risparmio
energetico.
Power On By ...:
indica se il sistema in standby deve riattivarsi
Standby Mode: specifica il tempo trascorso il quale il sistema entra
nella modalità Standby; il video e l'hard disk vengono spenti mentre tutte le
altre periferiche restano in funzione.
HDD Power Down: specifica il tempo di inattività del disco trascorso il
quale esso si spegne, mentre le altre periferiche rimangono accese.
Resume by Ring: se tale funzione é abilitata é possibile risvegliare il
sistema da una postazione remota.
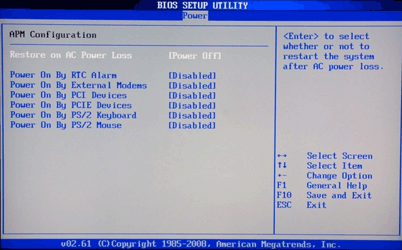
BOOT MENU:
Specifica la sequenza con
cui le unità (floppy,
dischi EIDE, lettore CD-Rom, unità SCSI, USB)
vengono lette dal boot loader alla
ricerca del sistema operativo
MENU SECURITY:
Con questo menu é possibile inserire una password che impedisce ad altri utenti
di intervenire sui settaggi del bios (Supervisor
Password) o di utilizzare la
macchina (User Password).
MENU DI USCITA (EXIT):
Le opzioni previste in questo menu sono le
seguenti:
Discard Changes:
annulla le modifiche senza uscire dal Bios.
Exit & Save Changes:
permette di uscire dal setup salvando le impostazioni eventualmente modificate.
Exit & Discard Changes:
fa uscire dal setup senza salvare le impostazioni eventualmente modificate.
Load Setup Defaults:
permette di caricare i settaggi di default, cioè predefiniti.
Per chi fosse interessato ad
approfondire le singole voci presenti nel bios consiglio questa guida
all'indirizzo:
http://www.freeplayclub.org/BIOS-t466.html
|
Sequenze di errore |
|
Il sistema adottato dai bios
Phoenix emette tre tipi
di beep con una sequenza molto simile. Ad esempio:
UN BEEP – DUE BEEP VICINI – UN BEEP (errore sul timer)
Questo fatto potrebbe trarre in inganno, perciò è bene
che ascoltiate attentamente ciò che il bios ha da dirvi!
|
PHOENIX BIOS |
|
Sequenza dei beep |
Errore |
|
1 + 1 + 3 |
Impossibile leggere la configurazione
del CMOS |
|
1 + 1 + 4 |
Errore generico del bios |
|
1 + 2 + 1 |
Errore sul chip del timer |
|
1 + 2 + 2 |
Errore generico sulla scheda madre |
|
1 + 4 + 2 |
Errore della memoria |
|
2 + 1 + 1 |
Errore della scheda video o della
memoria |
|
4 + 4 + 3 |
Errore del CoProcessore matematico |
|
4 + 2 + 4 |
Errore della scheda audio o del modem |
|
4 + 4 + 1 |
Errore della porta seriale |
|
4 + 3 + 4 |
Batteria tampone scarica |
|
4 + 2 + 1 |
Errore del chipset |
|
3 + 2 + 4 |
Errore del controller della tastiera o
del mouse |
|
Brevi e continui |
Mancano i moduli di memoria |
Il sistema
Ami, invece, usa due lunghezze differenti dei beep alternando
insieme i due tipi per indicare le diverse anomalie; a mio avviso è il
più complicato!
|
AMI BIOS |
|
Sequenza dei beep |
Errore |
|
1 breve |
Errore di refreshing della memoria RAM |
|
2 brevi |
Errore della memoria RAM (Parity check) |
|
3 brevi |
Errore della memoria RAM (primi 64k) o
video |
|
4 brevi |
Errore del timer della scheda madre |
|
5 brevi |
Errore del processore |
|
6 brevi |
Errore del controller della tastiera (Gate
A20) |
|
7 brevi |
Errore del processore o della scheda
madre (molto vago) |
|
8 brevi |
Errore della scheda video e/o della
memoria video |
|
9 brevi |
Errore generico all'avvio del bios
(errore sulla ROM) |
|
10 brevi |
Batteria tampone scarica |
|
11 brevi |
Errore della cache di secondo livello |
|
1 lungo + 3 brevi |
Errore nel test della memoria |
|
1 lungo + 8 brevi |
Errore nell'accesso alla scheda video |
Il sistema
Award, infine, è molto semplice ma anche molto vago:
|
AWARD BIOS |
|
Sequenza dei beep |
Errore |
|
1 lungo + 2 brevi |
Errore della scheda video |
|
1 lungo |
Errore della memoria RAM |
|
1 lungo + 3 brevi |
Errore della scheda video |
|
1 lungo continuato |
Errore della scheda video o della
memoria |
|
1 beep con pausa ogni 2 secondi |
Errore della memoria (necessita di
almeno due moduli ECC) |
|
Cosa parte con il BIOS?
Ti sarà capitato di sentire un bip dopo pochissimi secondi all’avvio del tuo
sistema operativo. Per la maggior parte degli utenti ciò significa che il
computer è a posto e che si sta avviando il sistema operativo. Pochi però sanno
cosa avviene nei primi secondi prima del bip: alimentatore di corrente, Cpu,
RAM, connessioni dell’hard disk, controller e scheda madre sono tutti componenti
che vengono controllati dal Bios, in inglese (Basic Input Output System).
All’avvio del PC sono passati circa due secondi
Subito dopo l’accensione si attiva la prima parte del Bios, il Post Test, in
inglese (Power – On Self – Test), che si assicura che i componenti basilari del
computer funzionino perfettamente. Quindi il Bios analizza il chipset del
computer. Dapprima il sistema effettua il reset della Cpu, operando la
disconnessione da parte del Bios del processore dalla linea NM interrupt (non
maskable Interrupt). A tale scopo si serve del Bit 7 della porta I/O 70h. Quasi
contemporaneamente si resetta anche il controller della tastiera attraverso i
Bit Hard Reset corrispondenti, nel momento in cui parte l’alimentazione
elettrica. Il Bios controlla attraverso la Reset Determination se al controller
è sufficiente un soft reset. Per fare ciò legge i bit corrispondenti nel
controller della tastiera. Un soft reset è più veloce di alcuni millesecondi,
poichè il sistema verifica la memoria solo fino a 64 kb. Tutto quello descritto
avviene in circa due secondi dall’accensione del computer.
All’avvio del PC sono passati circa due secondi e mezzo
Il Bios compie ora un test su sè stesso calcolando il (checksum) di tutti i bit
del suo chip. Tale analisi deve riportare il valore “00” unito a una determinata
cifra. Successivamente il computer invia un comando al controller della
tastiera. Quest’ultimo avvia un altro test e definisce un buffer di dati per i
comandi di programmi in cui il Bios scrive un byte di comando e verifica in
questo modo il controller interno della tastiera.
All’avvio del PC sono passati poco più di quattro secondi
Ora è la volta del chip CMOS (Complementary Metal Oxide Semiconductor).
Qui si
trovano le impostazioni del Bios definite da te quando imposti il computer
nell’utilizzo. Questi files di configurazione vengono letti dal Bios a ogni
avvio del chip CMOS. Il problema: il chip mantiene i dati e le impostazioni solo finchè la batteria è connessa, come avviene per la memoria RAM. Il sistema
verifica anche il checksum del chip Cmos: la parte riscrivibile del Bios. Anche
in questo caso calcola un checksum. Tale procedura dovrebbe rilevare se c’è una
batteria difettosa nel computer. Se questa è vecchia la tensione non basta più
per rifornire determinate parti del chip CMOS Lo puoi capire dal fatto che l’orologio di sistema
del tuo computer non risulta corretto.
All’avvio del PC sono passati poco più di quattro secondi e mezzo
Nel passo successivo il Post verifica la funzione dell’Interrupt Time che serve
per lo svolgimento corretto dell’attribuzione degli Irq.
Gli IRQ (Interrupt Request) sono comandi che l’hard disk o la scheda grafica inviano alla CPU per
comunicare la presenza di dati da elaborare. Queste richieste sono sempre
accompagnate da un tempo di latenza che corrisponde al tempo che intercorre tra
il segnale Irq e l’inizio dell’elaborazione dei dati. Infine il Bios crea una
tabella di vettori IRQ e carica le impostazioni utente del Bios nella memoria
CMOS. Le richieste di interrupt dei dispositivi arrivano innanzitutto al
Programmabile (Interrupt Controller) che li invia poi alla CPU. Il processore
interrompe i processi in corso e conferma l’Interrupt del Controller. A questo
punto la CPU legge il numero dell’IRQ corrispondente “vettore” nel controller e
lo utilizza come indice nella tabella vettori Interrupt. Essa contiene il
relativo incarico per ciascun Irq: per esempio quello di eseguire un’azione
specifica per il dispositivo. Dato che esiste solo un numero limitato di IRQ,
nei sistemi moderni diversi dispositivi condividono un IRQ (Interrupt Sharing).
Il problema: la routine di un Interrupt di questo tipo deve poter avviare poi
tutti i driver i cui dispositivi lo hanno avviato. Può succedere che i singoli
drivers programmati in modo non ottimale siano contrassegnati come attivi per un
periodo di tempo troppo lungo. Un altro di questi dispositivi scrive nel
frattempo in un buffer che si riempie rapidamente e causa un overflow a partire
da un certo punto, e ciò può comportare la perdita dei dati.
Nelle periferiche
moderne è il sistema operativo a occuparsi dell’assegnazione dinamica di
singoli numeri IRQ (NVRAM).
| Assegnamenti predefiniti ISA IRQ |
| IRQ |
Periferica
assegnata |
|
IRQ0 |
Riservata; generata dal
timer del sistema |
|
IRQ1 |
Riservata, generata dal
controller della tastiera |
|
IRQ2 |
Impostata dal controller di
interrupt secondario |
|
IRQ3 |
Disponibile |
|
IRQ4 |
Porta seriale; disponibile
se la porta seriale non è configurata per COM1 o COM3 |
|
IRQ5 |
Disponibile |
|
IRQ6 |
Generata dal controller
dell'unità disco floppy per indicare che l'unità richiede l'assistenza
del microprocessore. |
|
IRQ7 |
Porta parallela; disponibile
se la porta parallela è disattivata |
|
IRQ8 |
Riservata; generata
dall'orologio di sistema a tempo reale |
|
IRQ9 |
SCI in modalità ACPI |
|
IRQ10 |
PCI IRQA, B, C, D |
|
IRQ11 |
Disponibile |
|
IRQ12 |
Riservata; generata dal
controller della tastiera per segnalare che il buffer di uscita del
touchpad o del mouse PS/2 è pieno |
|
IRQ13 |
Riservata; generata dal
coprocessore matematico |
|
IRQ14 |
Riservata; generata
dall'unità disco rigido per indicare che l'unità richiede l'assistenza
del microprocessore. |
|
IRQ15 |
Riservata; generata
dall'unità CD-ROM o DVD-ROM nell'alloggiamento dei supporti esterni per
indicare che l'unità richiede l'assistenza del microprocessore |
E possibile visualizzare gli IRQ assegnati dal sistema
operativo lanciando l'utility di sistema: MSINFO32.EXE
All’avvio del PC sono passati quasi cinque secondi
Il Bios verifica che non ci siano errori nelle linee di attribuzione e di
indirizzo della memoria RAM nel primo megabyte. In tal senso il Post scrive dei
modelli di dati nella RAM e poi li raffronta.
Il sistema verifica ora
l’adattatore video e analizza la scheda grafica: dapprima il Bios controlla il
tipo di adattatore video e poi esegue una serie di test su adattatore e monitor.
Solo a partire da questo momento possono comparire dei messaggi di errore sullo
schermo.
All’avvio del PC sono passati poco più di cinque secondi
Ora è la volta dei controller Dma (Direct Memory Access): la Cpu e la memoria
Ram sono collegate mediante il cosiddetto north bridge (chiamato anche host
bridge) al bus dati della scheda madre. La maggior parte delle transazioni sul bus avviene tra il bridge e i restanti
dispositivi periferici. Affinchè quest’ultimi possono elaborare i propri dati
nel modo più rapido possibile, essi possono accedere direttamente all’host
bridge e scrivere in tal modo nella memoria RAM senza ulteriori perdite di
tempo. Per eseguire il test, il Bios utilizza nuovamente dei modelli di dati che
vengono scritti dal sistema nella memoria. Anche la connessione della tastiera
deve essere verificata. Il Bios sarebbe ora in grado di riconoscere una
tastiera diffettosa. Il tasto Bloc Num, che abilita il tastierino numerico sulla
destra, ora è attivo.
Il DMA permette di scavalcare la CPU, durante l'elaborazione e il
passaggio dei dati dalle periferiche di sistema alla memoria centrale. La CPU
quindi, se questo controller è presente ed abilitato, non verrà minimamente
sfiorata dai processi in corso che sfruttano questa caratteristica. Il DMA può
essere abilitato sia per unità ottiche e hard disk. Come puoi intuire sfruttare
tali caratteristiche significa non impegnare il processore in ulteriori
elaborazioni. Ne guadagnerai in velocità.
All’avvio del PC sono passati poco più di sette secondi e mezzo
Ora avvengono i test finali: eventuali drivers del floppy, il
disco fisso e le
connessioni vengono ricontrollate dal Bios, prima che il sistema passi al boot
loader Interrupt 19. Questo si occupa di caricare il sistema operativo e
sorveglia il trasferimento dei dati dal disco fisso e dal Controller
corrispondente. Molte versioni di Bios offrono la possibilità di disattivare
l’IRQ19. Ciò ha senso solo se esiste un Controller del disco aggiuntivo nel
computer, per esempio un (Controller Pci Raid). Se in qualche punto
dell’autotest si verifica un errore, il computer emette diversi bip e visualizza
un messaggio di errore sullo schermo.
All’avvio del PC sono passati quasi dodici secondi e mezzo
Se tutto è a posto, il computer emette un breve bip e cerca poi un supporto di
avvio con il sistema operativo funzionante. Se si verifica un errore in questo
frangente, risiede nel fatto che manca il Mbr (Master Boot Record). Se dovesse
apparire un messaggio di errore, puoi provare a ripristinare il sistema con il
DVD di installazione di Windows.
















